Sommaire
L'apprentissage automatique et l'intelligence artificielle (IA) jouent un rôle de plus en plus important dans la modélisation et la classification des modèles de marketing en ligne. Des entreprises telles que Tesla, Google, Microsoft, Amazon et Facebook mènent de nombreuses recherches dans le domaine de l'intelligence artificielle.
Après l'annonce de Google en novembre 2015, un nouveau signal de classement très important ou un facteur de classement important appelé rang cerveau travaille depuis des mois, l’intérêt pour le sujet est-il Machine Learning enfin arrivé dans la communauté du référencement et du marketing en ligne. Je tiens le sujet Apprentissage machine en particulier dans le contexte numérique, pour des raisons tout aussi incisives et prospectives, comme par exemple: les thèmes du marketing mobile, du big data et du contenu. Comme l'apprentissage machine lié à d'autres mots à la mode récents tels que Intelligence artificielle (Intelligence artificielle), sémantique ou Apprentissage en profondeur Je voudrais expliquer ci-dessous et quels sont les effets de ce développement sur les algorithmes d'autoapprentissage des moteurs de recherche. Je tiens à souligner que je suis le sujet Intelligence artificielle ou Apprentissage machine pourrait considérer que superficiellement. Si vous souhaitez approfondir le sujet, vous trouverez une collection détaillée de vidéos et de liens vers le sujet à la fin de l'article.
Dans cet article, je vais essayer le monde de la machine learning et son influence sur le référencement avec le soutien de précieux collègues nommés Markus Hövener. Sepita Ansari. Christian Kunz. Marcus Tober. Kai Spriestersbach, Sebastian Erlhofer et Marcel Schrepel rendre plus tangible.
Qu'est-ce que l'apprentissage automatique? Signification, définition et méthodologie
L'importance actuelle et surtout future de l'apprentissage automatique doit être classée de la même manière que les thèmes du marketing mobile, du Big Data ou du marketing de contenu dans le contexte numérique. Le nombre de visites sur la couverture médiatique des sujets a également considérablement augmenté depuis 2014, comme le montre l'évolution de Google.
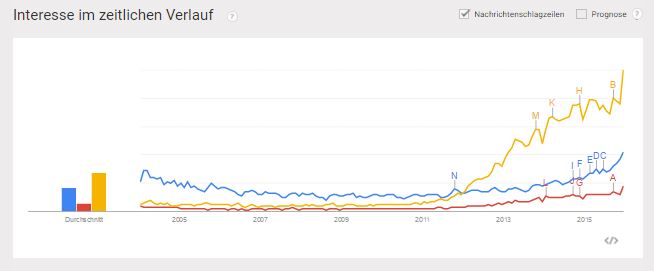
Google Trends: développement d'un volume de recherche global pour les mégadonnées (en jaune), l'apprentissage automatique (en bleu) et le marketing de contenu (en rouge)
Comme je l'ai déjà expliqué dans mon article sur le Web sémantique (Web 3.0) en tant que conséquence logique du Web 2.0, les systèmes qui rendent les informations identifiables, catégorisables, évaluables et triables selon le contexte font de l'unique possibilité du flot d'informations et de données basé sur les innovations. devenir le gentleman du Web 2.0. Mais la sémantique pure ne suffit pas ici. C'est pourquoi les portiers numériques ont besoin de plus en plus d'algorithmes fiables pour accomplir cette tâche. Algorithmes d’autoapprentissage basés sur Intelligence artificielle et les méthodes d’apprentissage automatique jouent un rôle de plus en plus important. C’est le seul moyen de garantir la pertinence des résultats ou des dépenses / résultats attendus.
Mais qu'est-ce que l'apprentissage par machine maintenant et comment ça marche?
Apprentissage machine est dans le sujet Intelligence artificielle trop allemand Intelligence artificielle localiser. Le domaine de l'intelligence artificielle est divisé en sous-domaines suivants:
1er raisonnement
2. Représentation des connaissances
3. Planification et ordonnancement automatisés
4. Apprentissage automatique
5. Traitement du langage naturel
6. vision par ordinateur
7. Robotique
8. Intelligence générale ou forte IA
Le terme renseignement s’applique en relation avec Machine Learning Ce n’est pas tout à fait qu’il s’agit moins d’intelligence, mais bien de modèles et de précision reconnaissables par machine ou ordinateur. Apprentissage machine traite du développement automatisé d'algorithmes basés sur des données empiriques ou des données d'apprentissage. L'accent est mis sur l'optimisation des résultats ou l'amélioration des prévisions dues aux processus d'apprentissage.
Intelligence artificielle Le but est de prendre des décisions en fonction des données collectées selon un humain. Cela nécessite plus que des méthodologies d'apprentissage machine. La technologie à l'origine de l'apprentissage automatique s'appelle des réseaux de neurones.
Que sont les réseaux de neurones?
Réseau de neurones trop allemand Réseaux de neurones sont des groupes d'algorithmes construits conformément à un cerveau humain pour reconnaître des modèles récurrents, puis pour les étiqueter ou les étiqueter. Les modèles reconnus sont traduits en vecteurs mathématiques. Toutes les informations du monde réel, telles que les images, le son, le texte ou les séquences temporelles, sont prises en compte.
Les réseaux de neurones aident à classer les nouvelles informations de différents systèmes sur la base de similitudes et à les regrouper en groupes de modèles. Les étiquettes aident à nommer ces groupes. Des exemples d'étiquettes peuvent être: Spam, Pas de spam, Client satisfait, Client insatisfait, Lien acheté, Lien non acheté …
La diapositive suivante d'un exposé de Jeff Dean, de Google, montre que certains modèles, par exemple Grâce à ces modèles récurrents, l'apprentissage automatique peut être utilisé pour interpréter et étiqueter automatiquement l'image d'un lion.

Source: Présentation Jeff Dean / Google
Réseaux de neurones se composent de plusieurs niveaux ou couches qui contribuent en série au raffinement ou à la précision des hypothèses. Si vous êtes plus profondément concerné par le sujet, voici une belle introduction.
types d'apprentissage automatique
Il existe fondamentalement trois types différents d’apprentissage automatique:
- Apprentissage surveillé
- Apprentissage non surveillé
- Renforcement de l'apprentissage
De plus, un extrait de l'allemand Wikpiedia:
- Apprentissage supervisé apprentissage superviséL'algorithme apprend une fonction à partir de paires d'entrées et de sorties données. Pendant l’apprentissage, un "enseignant" fournit la valeur de fonction correcte pour la saisie. L’objectif de l’apprentissage supervisé est que le réseau soit formé après plusieurs calculs avec différentes entrées et sorties, la possibilité de créer des associations. Un sous-champ du apprentissage supervisé est la classification automatique. Un exemple d'application serait la reconnaissance de l'écriture manuscrite.
- Apprentissage non surveillé (angl. apprentissage non superviséL'algorithme génère un modèle pour un ensemble donné d'entrées qui décrit les entrées et permet des prédictions. Il existe des méthodes de regroupement qui divisent les données en plusieurs catégories, qui diffèrent les unes des autres par des modèles caractéristiques. Le réseau crée ainsi indépendamment des classificateurs selon lesquels il divise les modèles d’entrée. Un algorithme important dans ce contexte est l'algorithme EM, qui définit de manière itérative les paramètres d'un modèle afin d'expliquer au mieux les données visualisées. Ce faisant, il utilise la présence de catégories non observables et, à son tour, estime l'affiliation des données à l'une des catégories et aux paramètres qui constituent ces catégories. Une application de l'algorithme EM se trouve, par exemple, dans les modèles de Markov cachés (HMM). Autres méthodes d'apprentissage non supervisé, par exemple. B. L'analyse en composantes principales supprime la catégorisation. Ils ont pour objectif de traduire les données observées en une représentation plus simple qui les reproduit le plus fidèlement possible malgré des informations considérablement réduites.
- Renforcement de l'apprentissage (engl. apprentissage par renforcementL’algorithme apprend par la récompense et la punition une tactique sur la manière d’agir dans des situations susceptibles de se produire afin de maximiser les avantages de l’agent (c’est-à-dire le système auquel appartient la composante d’apprentissage). C'est la forme la plus commune d'apprentissage d'une personne.
J'ai aussi dans cette présentation de Rahul Jain trouvé de bons graphiques. (Lien vers la présentation en fin d'article).
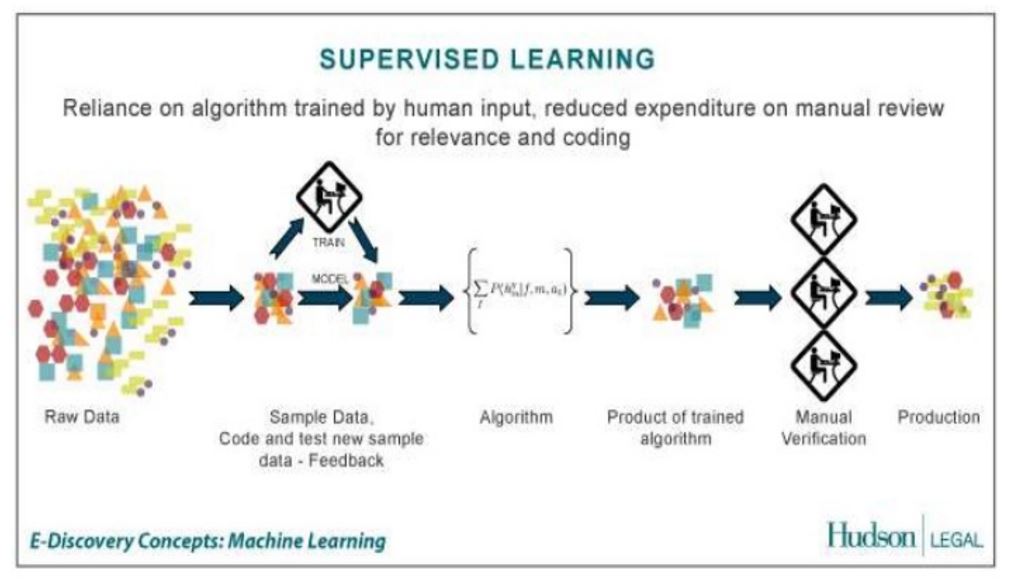
Processus d'apprentissage automatique: apprentissage supervisé
la Apprentissage surveillé De nombreux travaux préparatoires sont nécessaires car les modèles de modèles doivent être définis et étiquetés au préalable afin de pouvoir identifier les informations entrantes et les affecter à ce groupe de modèles. Cet étiquetage est généralement effectué à la main en raison de l’assurance qualité. En raison de certains modèles récurrents, le système peut alors reconnaître de manière indépendante des informations avec des propriétés de modèle identiques ou similaires à l'avenir et les affecter au groupe de modèles correspondant.
 Processus d'apprentissage automatique: apprentissage non surveillé
Processus d'apprentissage automatique: apprentissage non surveilléDans le cas d'un apprentissage non supervisé, l'étiquetage avancé n'a pas lieu et les groupes de modèles sont automatiquement formés sur la base de modèles.
Processus d'apprentissage automatique: renforcer l'apprentissageSemblable au terme d'intelligence artificielle, le terme d'apprentissage automatique est souvent assimilé à un apprentissage en profondeur et à la sémantique ou appelé dans le même souffle. Vous trouverez ci-dessous une tentative de différenciation.
Différence entre l'apprentissage automatique et l'apprentissage en profondeur
Apprentissage en profondeur est un sous-domaine de l’apprentissage automatique, on pourrait aussi parler de développement. Alors que les algorithmes classiques d’apprentissage automatique reposent sur des groupes de modèles solides pour la reconnaissance et la classification, les algorithmes d’apprentissage approfondi développent indépendamment ces modèles ou créent indépendamment de nouveaux niveaux de modèle au sein des réseaux de neurones. Par conséquent, il n'est pas nécessaire que les modèles pour les nouveaux événements soient développés et implémentés manuellement, comme ce serait le cas avec les algorithmes traditionnels d'apprentissage automatique. Il est donc préférable de répondre aux prévisions d’Algos qui ont un apprentissage en profondeur. En outre, ce graphique (l’Orginaquelle n’est malheureusement plus en ligne. C’est pourquoi nous faisons référence à cet article.)
Différenciation entre apprentissage automatique et sémantique
La sémantique peut aider à mieux identifier la signification d'un objet grâce à sa classification en tant qu'entité unique et à ses relations avec d'autres entités. Lors de la classification, la sémantique utilise des propriétés similaires aux modèles associés aux groupes de modèles dans l'apprentissage automatique. La principale différence, cependant, est que la sémantique ne poursuit aucun processus d'apprentissage, comme c'est le cas avec l'apprentissage automatique. De ce fait, les systèmes sémantiques sont plutôt statiques et peu capables d’effectuer des prévisions pour de nouvelles situations. Les groupes de modèles et les modèles ou entités doivent être connus.
Apprentissage automatique et algorithmes (moteur de recherche)
La chose intéressante à propos de ce développement est la Machine Learning est que les algorithmes peuvent évoluer et s’adapter à l’avenir. Jusqu'à présent, par exemple Chez Google, l’algorithme de recherche s’est développé comme suit.
Une modification moyenne des algorithmes commence par une idée visant à améliorer la recherche de l’un des développeurs de Google. Ils suivent une approche basée sur les données et toutes les modifications d’algorithme proposées sont testées avant publication dans le cadre d’une évaluation de la qualité complète.
En règle générale, les développeurs partent d'une série d'expériences, optimisent l'une ou l'autre variable et demandent un feedback à leurs collègues. S'ils sont satisfaits du résultat, l'expérience est diffusée à un public plus large.
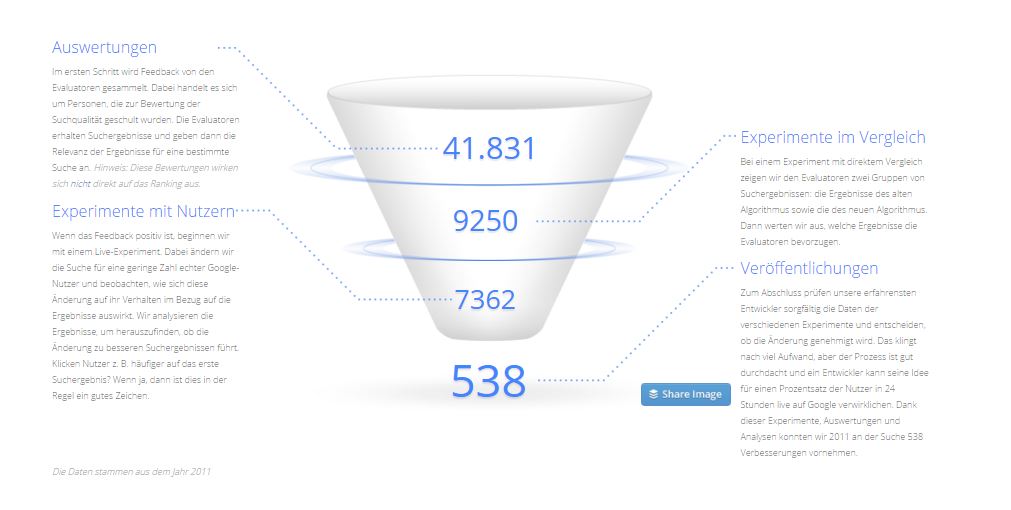
Développement d'algorithmes chez Google Source: Google
Le résultat est un algorithme général statique qui est développé par de nombreuses mises à jour plus petites et plus grandes. Cet algorithme est le même pour chaque situation. Plongez complètement dans de nouvelles situations sans précédent, une fois débordé. La prise en compte de chaque contexte individuel, tel que Emplacement, terminal utilisé … dans lequel un utilisateur est situé doit utiliser cet algorithme. Dans le cas optimal, chaque utilisateur ou au moins groupe d'utilisateurs aurait "gagné" son propre algorithme pour pouvoir être utilisé en fonction du contexte respectif. Ce n'est pas possible avec le précédent algorithme relativement statique.
Il n'est pas possible d'écrire votre propre algorithme pour chaque tâche. Des algorithmes doivent être écrits pour apprendre des observations. L'apprentissage automatique rendrait cela possible et Google va déjà dans cette direction.
En outre, les utilisateurs de Google peuvent utiliser des signaux qui peuvent être utilisés comme indicateurs de réussite dans le processus d'apprentissage:
- Rapport de clic long à court
- Proportion de chercheurs effectuant des requêtes de recherche connexes et supplémentaires
- Mesures d'engagement de l'utilisateur (détectables via Chrome, par exemple)
- Taux de kick relatif dans les SERPs
- Contenu partagé
- Engagement de l'utilisateur sur les sites Web
En combinaison avec les signaux classiques de classement hors page tels que les backlinks, les co-citations et les co-occurrences, ceux-ci peuvent être utilisés comme métriques de succès pour la vérification d'une estimation par l'algorithme.
Une question intéressante est la suivante: où Google obtient-il les données de formation relatives à l'utilisateur pour lancer le processus d'apprentissage automatique?
S'agit-il de véritables données utilisateur ou Google continue-t-il d'utiliser les données fournies par les évaluateurs de recherche? Quality Rater à générer dans un environnement de test?
(Des discussions comme celle-ci dans les commentaires.)
Devenant progressivement obsolète, l'algorithme de développement d'algorithme ci-dessus. En témoignent également les mises à jour de plus en plus fréquentes en temps réel telles que. les mises à jour de pingouin en temps réel ou les mises à jour de "panda" en attente. Auparavant, les mises à jour à venir étaient annoncées volumineuses et par de tels collègues. sistrix documentée. Je pense qu'une telle documentation aura bientôt perdu sa signification. Et aussi des enquêtes et des aperçus des facteurs de classement tels que nous les connaissons jusqu’à présent seront historiques dans quelques années. Mais plus à ce sujet ci-dessous.
Google contient déjà de nombreuses informations provenant de différents niveaux d'indexation et de classement, qui doivent en quelque sorte être prises en compte dans l'algorithme.
- texte
- Visuels (images, vidéos)
- acoustique
- le comportement des utilisateurs
- Knowledge Graph (image des relations)
Pendant ce temps, Google peut déjà lire les chiffres et le texte des images, comme mon collègue Philipp le décrira avec brio dans son message de la semaine prochaine.
Plus dans l'article Reconnaissance d'images: Google peut-il lire et reconnaître des textes dans des images?
Si vous examinez à nouveau les différents types d’apprentissage automatique et que vous les transférez au monde des moteurs de recherche, il est logique de penser aux endroits où au moins les approches d’apprentissage automatique sur Google sont déjà utilisées. En termes de recherche, vous pouvez au moins reconnaître les approches de la ML ici:
- Graphique de connaissances
- colibri
- rang cerveau
- éventuellement pingouin en temps réel
De plus, certains produits Google utilisant des fonctionnalités d'apprentissage en profondeur, tels que: Texte en reconnaissance d'image, reconnaissance vocale, Google Translate …
La grande question est de savoir comment créer des systèmes capables de gérer toutes ces informations.
Et encore une fois, la réponse est que l'apprentissage automatique peut être cela.
Le problème le plus important lié au traitement d’une telle masse de données est celui des performances et de l’évolutivité. Néanmoins, Google souhaite, de toutes ses forces, aller de l'avant vers l'apprentissage automatique. Selon Eric Schmidt, l'apprentissage automatique est le thème dominant de l'avenir de Google, comme il l'a récemment présenté aux étudiants de la TU Berlin:
Le sujet exceptionnel des années à venir selon Schmidt Machine Learning. Ainsi, le développement de machines et d'ordinateurs pouvant apprendre de manière autonome. Schmidt: "Nous n'aurons plus à poser de questions à l'ordinateur à l'avenir, car il a appris ce que nous allons demander. Quelque chose de très grand commence tout juste. "Schmidt fait confiance aux machines. Les ordinateurs sont simplement meilleurs et plus rapides que les humains à bien des égards.
Engagement de Google en matière d'intelligence artificielle et d'apprentissage automatique
Que Google finisse par créer un cerveau artificiel et que, pour Hummingbird et le graphe de Knowldege, ce n’est que le début de ma collègue Svenja il ya deux ans, avec l’article Knowledge Graph: Google construit un cerveau ici, dans le blog. Mais jusqu'à présent, vous ne pouviez que le deviner. En raison des activités supplémentaires de ces dernières années, le tableau devient de plus en plus clair.
Selon Google, depuis 2014, Google a presque quadruplé ses activités d'apprentissage en profondeur, comme le montrent les diapositives de la conférence de Jeff Dean ci-dessous.
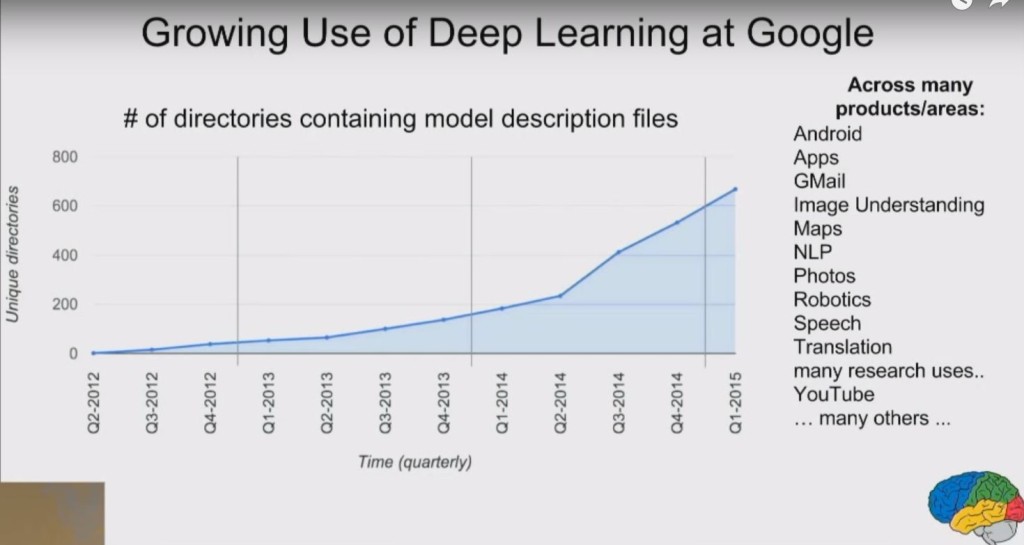
Source: Présentation Jeff Dean / Google
L'engagement de Google pour les choses Intelligence artificielle et Machine Learning commencé en 2011 avec le lancement de "Google Brain". L'objectif de Google Brain est de créer vos propres réseaux de neurones. Depuis lors, Google développe son propre logiciel d'apprentissage en profondeur DistBelief Continuez à développer vos propres produits d’apprentissage automatique. La deuxième génération de logiciels appelée Flux tensoriel mais est déjà dans les starting-blocks.
En regardant l’investissement et l’engagement dans l’intelligence artificielle au fil du temps, on comprend vite l’importance de Google dans ces domaines:
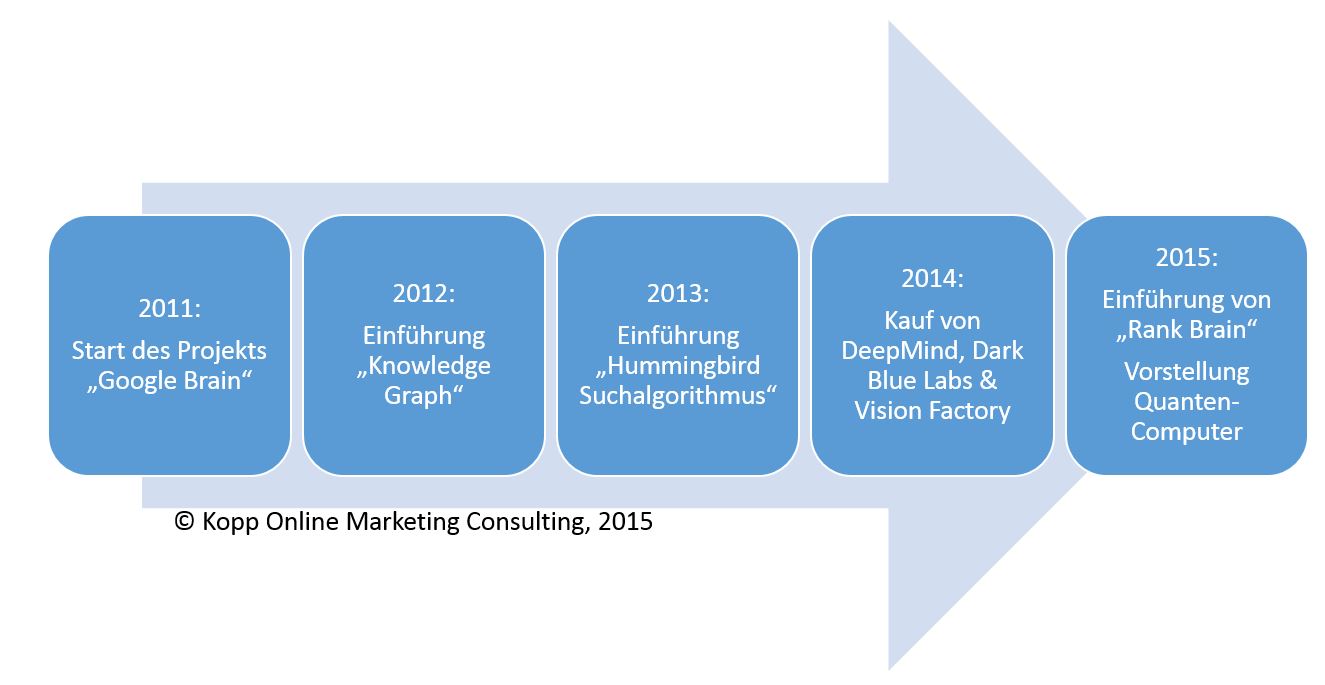
L'engagement de Google dans l'apprentissage automatique et l'intelligence artificielle
Bien que Knowledge Graph et Hummingbird incluent déjà des approches d’apprentissage automatique, l’accent a été mis davantage sur le moteur de recherche sémantique. Au plus tard, avec les investissements de plusieurs centaines de millions de dollars dans diverses entreprises des domaines de l'intelligence artificielle et de l'apprentissage automatique en 2014, il est clair que Google veut vraiment aller.
avec Esprit profond (environ 365 millions de dollars) Google a acheté une société fondée en 2011, spécialisée dans les systèmes autour de l'intelligence artificielle. et al DeepMind est responsable du développement de Google Now. La mission de DeepMind est de comprendre l'intelligence. De plus, DeepMind ne traite pas seulement du développement des réseaux de neurones, mais travaille également sur des modèles beaucoup plus souples, similaires à ceux d’une mémoire à court terme.
Labos Bleu Foncé d'autre part, l'accent est mis sur la reconnaissance et l'interprétation du langage naturel, ainsi que des formats audio.
vision Factory se spécialise dans la reconnaissance et l'interprétation de supports visuels tels que des images ou des vidéos.
Toutefois, lorsqu'il s'agit de textes, Google a une expérience de moteur de recherche basée sur le texte. Dans le domaine de l'audio, de la vidéo et de l'image, ils ont obtenu un soutien professionnel auprès des entreprises mentionnées.
En outre, Google investit depuis des années, selon sa propre déclaration, dans le domaine de l'intelligence artificielle. Ainsi, Google a par exemple investi des dizaines d’heures de travail dans le développement d’une infrastructure de pointe. propres réseaux de neurones investis. En outre, Google utilise des milliers de processeurs et de processeurs graphiques pour tirer des enseignements de milliers de milliards d'enregistrements en parallèle.
En décembre 2015, Google a annoncé qu'il travaillait avec la NASA sur un ordinateur quantique.
Google publie souvent des tâches scientifiques sur des sujets tels que la reconnaissance d'images, la reconnaissance vocale. Plus de 460 publications sur l'intelligence artificielle ont été publiées au cours des deux dernières années. Voir http://research.google.com/pubs/ArtificialIntelligenceandMachineLearning.html.
Et ce n'est pas juste la théorie. Par exemple, Google affirme avoir implémenté l'expérience d'apprentissage en profondeur depuis 2012 dans plus de 47 produits. Voici un extrait:
- Reconnaissance d'objets en images
- Détection de type d'objet dans les vidéos
- reconnaissance vocale
- Passants pour les voitures autonomes
- OCR: reconnaissance de texte en images
- Reconnaissance d'un langage familier
- Traduction automatique
- Publicité en ligne
Le système d'apprentissage automatique de l'équipe Expander utilise des ressources naturelles, des images, des vidéos et des requêtes, pour alimenter traduction de la langue, reconnaissance des objets visuels, compréhension du dialogue, etc.
Google reconnaît lui-même que l’apprentissage automatique semi-supervisé (expliqué plus haut dans l’article) est utilisé.
Fondamentalement, la plateforme d'Expander combine l'apprentissage automatique semi-supervisé et l'apprentissage à grande échelle basé sur des graphes en créant une représentation multi-graphes du concept. Le graphique contient généralement des données étiquetées (nœuds associés à une catégorie de sortie connue ou une étiquette) et des données non étiquetées (nœuds pour lesquels aucune étiquette n'a été fournie).
Il est difficile de déterminer qui prend en charge l'étiquetage manuel ou la précognition sur Google. Il se peut que cela soit fait en fonction de la tâche effectuée par Quality-Rater et par un favorable Clickworker.
Pour en savoir plus sur les activités d'intelligence artificielle de Google, je vous recommande l'une des nombreuses conférences de Jeff Dean.
Au plus tard, avec l'introduction de l'extension d'algorithme de Hummingbird nommée Rankbrain, chaque référencement naturel devrait indiquer clairement que le thème de l'apprentissage automatique constituera un facteur de plus en plus important dans le classement.
Avant d’examiner les effets de ces activités sur l’optimisation des moteurs de recherche, je vais approfondir quelques conseils de lecture.
Sources sur l'apprentissage automatique et l'intelligence artificielle
Apprentissage en profondeur vs apprentissage automatique vs reconnaissance de formes
Apprentissage automatique expliqué en mots simples
Wikipedia: Apprentissage automatique
Introduction à l'apprentissage automatique
Rise of the Machines de JAX TV sur Vimeo.
Quel est le rôle de Rankbrain?
Selon Google, Rankbrain a été initialement appliqué principalement à 15-20% des requêtes précédemment non demandées. Rankbrain est appliqué à toutes les requêtes de recherche depuis juin 2016.
Rankbrain est cité par Google comme le troisième facteur de classement en importance. Le facteur de classement du terme Ber est source de confusion. Facteur de classement oui, signal de classement non. Et ici commence pour beaucoup de SEO l'incertitude, qui n'est en partie pas résolue par les déclarations contradictoires de Google.
Il y a deux questions qui occupent les SEO avec Rankbrain
- Rankbrain est-il responsable du raffinement de la requête ou de la classification et de l'interprétation des mots-clés, ou du scoring des URL?
- Rankbrain utilise-t-il des données utilisateur réelles, des données de formation provenant d’évaluateurs de recherche ou d’évaluateurs de qualité, ni aucun d’eux comme données de formation?
Voici les théories suivantes:
- Rankbrain n'est pas un signal de classement mais seulement responsable du raffinement de la requête
- Rankbrain est un signal de classement et participe donc à la notation des documents
- Outre Rankbrain, d’autres systèmes d’apprentissage automatique sont utilisés chez Hummingbird.
1. Rankbrain n'est pas un signal de classement mais seulement responsable du raffinement de la requête
Rankbrain n'est pas un facteur de classement classique, tel que Titres de page ou backlinks. Rankbrain est plutôt une mise à jour de l'algorithme de Hummingbird sous la forme d'une extension. En raison de la détermination de la proximité thématique par rapport aux termes déjà connus, Rankbrain peut classer les requêtes de recherche précédemment inconnues en contextes thématiques ou, en particulier, décomposer les requêtes complexes plus longues en dénominateurs communs. En conséquence, la signification peut être mieux interprétée et ainsi la requête de recherche inconnue peut être attribuée à des synonymes déjà connus ou à des termes de signification similaire ou identique. Rankbrain, en particulier lors de l’interprétation des requêtes de recherche, peut faire progresser Google.
Par exemple, Rankbrain a été présenté dans la première annonce de Google et Paul Haahr de Google a confirmé cette théorie lors du SMX Advanced 2016 dans cette interview avec Danny Sullivan (à partir de 3h00). Notez que Gary Illyes joue également un rôle de soutien, qui est mentionné ailleurs.
2. Rankbrain est un signal de classement et est donc impliqué dans la notation des documents
Rankbrain est directement impliqué dans l'évaluation du contenu de la page. Ici, certains modèles, le contenu approprié pour une requête particulière, doivent être identifiés à plusieurs reprises et utilisés pour le scoring. Mais il n'y a que quelques déclarations de Google. Il est assez frappant de constater que Gary Illyes, dans le rôle principal joué lors d'une séance de questions-réponses avec Danny Sullivan également au SMX Advanced 2016, a déclaré ce qui suit concernant Rankbrain (à partir de 5:40 minutes):
"C'est moins pour comprendre la requête que pour marquer les résultats …"
Danny Sullivan semblait être plus susceptible de partir de la première théorie qui lui avait été confirmée lors du même événement par son collègue Halyr des Illyes.
Très déroutant ce que Google communique ici.
3. En plus de Rankbrain, d’autres systèmes d’apprentissage automatique sont utilisés chez Hummingbird.
Une autre hypothèse est que, en plus de Rankbrain, d’autres parties de Hummingbird Machine Learning incluent également, par exemple, est utilisé pour la notation de sites Web. Mario Fischer également dans une discussion sur Facebook:
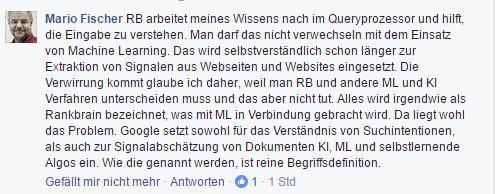
Mario Fischer confus à propos de Rankbrain dans une discussion sur Facebook du 22.11.2016
J'ai demandé à John Mueller de Google dans le Webmaster Hangout du 01.12.2016 une réponse. Voici son opinion sur le rôle de Rankbrain:
John confirme la première des trois théories selon lesquelles Rankbrain n'est utilisé que pour interpréter les requêtes de recherche. La notation réelle des sites Web, qui assure le tri des résultats de la recherche, a lieu dans l'algorithme de Hummingbird. Indique si les signaux utilisateur sont utilisés ici en tant que données d'apprentissage pour l'interprétation des requêtes de recherche, par ex. être utilisé pour l'enquête n'est pas clair.
Rankbrain pour le raffinement de la requête
Je crois en la première déclaration de Google selon laquelle Rankbrain est utilisé comme moyen de raffinement de la requête, c'est-à-dire sur la page de la requête de recherche. Surtout que Paul Haahr m'a fait dans les deux vidéos l'impression beaucoup plus compétente et que Gary Illyes ne s'est pas produit pour la première fois avec un manque de satisfaction en matière de communication. Mais cela voudrait dire que Rankbrain n’est pas un facteur direct, contrairement à ce que dit Gary Illyes.
Je pense aussi qu’en plus de Rankbrain, d’autres systèmes d’apprentissage automatique, par exemple utilisé pour marquer les sites Web. Si ce n'est pas maintenant, alors à l'avenir. Je suis également convaincu que Google utilise également l'apprentissage automatique pour déterminer l'intention de recherche, y compris l'inclusion de données d'utilisateur réelles. Mais presque tout est spéculation ou acceptation à ce jour.
Rankbrain en tant que médiateur entre la requête de recherche et Hummingbird
Voyons comment fonctionne le moteur de recherche de Google.
La fonctionnalité de Google est divisée en gros dans les domaines suivants:
- Ramper et indexer
- Comprendre et développer les requêtes de recherche (y compris Rankbrain)
- Récupération et notation (Hummingbird / Knowledge Graph)
- Ajustements post-récupération (y compris Panda, Penguin)
Pour l'évaluation, l'évaluation de documents individuels indépendamment de la requête de recherche est par conséquent non pas Rankbrain responsable, mais l'algorithme de Hummingbird. Rankbrain n'interprète que les requêtes de recherche.
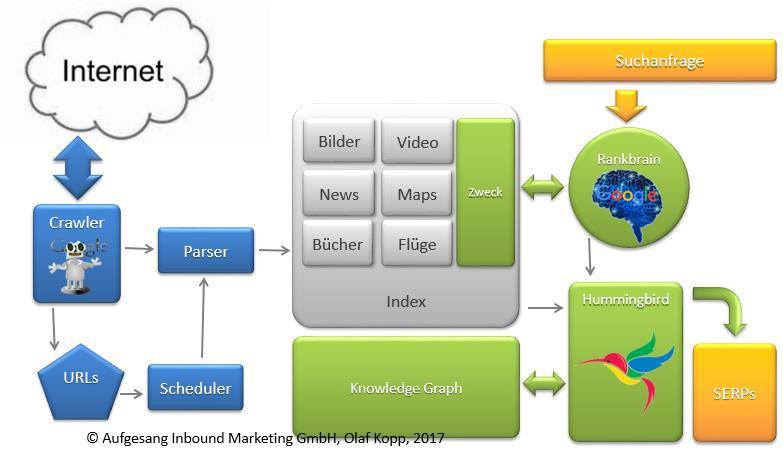
C'est ainsi que Google pourrait fonctionner aujourd'hui
Si on interprète déjà Gary Illyes presque un peu ennuyé et que sa réponse aux demandes de Rand Fishkins pourrait être utilisée, Rankbrain pourrait être utilisé pour pondérer différemment les facteurs de classement en fonction de l’intention de recherche. Cela influencerait donc le classement des documents.
Réclamez maintenant certains SEO qu'au moins dans la détermination de l'intention de recherche de Rankbrain Google sur des signaux d'utilisateur réels. Ich bin zuerst auch davon ausgegangen, aber laut Aussage von Gary Illyes scheint es nicht so. Zumindest keine Nutzersignale in der freien Online-Wildbahn.
It’s an offline learning algorithm. It’s refreshed every now and then with new training data.
Wenn man zwischen den Zeilen liest gibt es zwei Möglichkeiten:
- Google könnte Nutzersignale ihrer Such-Evaluatoren nutzen um auch die Suchintention zu ermitteln bzw. Keyword-Modellgruppen bezogen auf die Suchintention zu bilden.
- Google könnte Nutzersignale erfassen und als Trainingsdaten in das Offline Machine-Learning-System von Rankbrain einfließen lassen.
Aber alles pure Spekulation.
Kommen wir zum eigentlichen Scoring der Dokumente über Hummingbird. Ich versuche, das mal mit Hilfe von Paul Haahrs Vortrag von der SMX West 2016 zu erklären, ohne es genau zu wissen.
Google klassifiziert laut Paul Haahr (Video weiter unten) Dokumente und Websites in sogenannte Shards innerhalb des Index. Laut Haahr gibt es tausende von verschiedenen Shards. Ich könnte mir vorstellen diese Shards sind nach Zweck des Dokuments und/oder Themenbereich im Index klassifiziert. Das für das Ranking relevante Gesamt-Scoring findet dann aus dem allgemeinen Scoring des Dokuments im Abgleich mit der über Rankbrain identifizierten Suchintention der Suchanfrage statt.

Paul Haahr zum Thema Scoring
Zu weiteren Theorien, zu was Rankbrain noch genutzt werden könnte empfehle ich die Präsentation von Kai Spriestersbach von der SEOkomm 2016. Die Einschätzung zum Einfluss der Engagement-Daten wie Absprungrate und CTR auf Rankbrain teile ich allerdings nicht voll und ganz.
Wir sollten bei Kais Präsentation vielleicht eher von Machine Learning bei Google und nicht explizit von Rankbrain sprechen.
Wer sich mit dem Thema beschäftigt sollte sich auch diese Keynote von Marcus Tandler ansehen:
Marcus Tandler Vortrag, Rise of the Machines
Welche Auswirkung kann Machine-Learning zukünftig auf das Ranking haben?
Ich denke, dass Machine Learning Funktionalitäten nicht erst bei Rankbrain, sondern bereits bei Hummingbird und der stetigen Weiterentwicklung bzw. Vergrößerung und Strukturierung des Knowledge Graph im Einsatz sind. Dass Machine Learning zur Spam-Bekämpfung z.B. im Rahmen des Pinguin-Algos zum Einsatz kommt wurde inzwischen durch eine Aussage von Google bzw. Gary Illyes wiedersprochen. Ich hoffe hier bleibt es auch bei dieser eindeutigen Aussage.
Ob Google jetzt schon Machine Learning für die Bewertung von Websites nutzt kann aufgrund der widersprüchlichen Aussagen aus dem Hause Google nicht beantwortet werden. Sinn würde es für die Zukunft machen.
Ich denke, dass Machine Learning bereits schon seit längerem zur Kategorisierung von Suchanfragen, Inhalten aber auch Entitäten ( Mehr zum Thema Semantik und Entitäten) eingesetzt wird. Es muss ja nicht zwangsläufigüber Rankbrain sein. Die ein oder andere Prise Machine Learning könnte auch schon in den Hummingbird-Algo direkt eingeflossen sein.
Gerade in Kombination mit dem Knowledge Graph als semantische Datenbank hätte Google zwei mächtige Werkzeug an der Hand.
Hilfreich könnte hierfür auch ein Google-Patent zur Nutzung von Knowledge Base Kategorien sein, über das man im Beitrag How Google Might Make Better Synonym Substitutions Using Knowledge Base Categories mehr erfahren kann.
Dafür, dass Google Suchanfragen bereits zu verschiedenen Kategorien zuordnet gibt es klare Anzeichen wie z.B. die Beobachtungen von Ross Hudgens zeigen.
Entitäten-Katgeorien in Google Suggest: Quelle siehe obigen Link zu The SEM PostGoogle versucht hier zwecks Eindeutigkeit Begriffe insbesondere Entitäten mit mehreren Bedeutungen je nach Kontext über Kategorisierung voneinander abzugrenzen. Auch in Google Trends kategorisiert Google Begriffe bereits nach Kategorien:
Machine-Learning-Pozess: Bestärkendes Lernen / Quelle: http://www.slideshare.net/rahuldausa/introduction-to-machine-learning-38791937
Ob nun die Nutzerdaten oder das Feedback der Such-Evaluatoren bzw. Quality-Rater oder sogar beide Gruppen das bestärkende Element für den Algorithmus sind kann man nur erraten…
Das alles ist reichhaltiges Futter für die selbst lernende Weiterentwicklung der Ranking-Algorithmen und dadurch teils sehr individuelle Suchergebnisse pro Nutzer.
Ich glaube, dass die bisherigen Einsatzgebiete für Machine Learning bei Google nur der Anfang sind. So könnten theoretisch selbstlernende Algorithmen auch für alle vorkommenden Suchanfragen angewandt werden, nicht nur wie bei Rankbrain auf die bisher unbekannten Suchwörter. Doch welche Auswirkungen hätte das Ganze für SEOs?
Welche Auswirkung haben selbst lernende Algorithmen auf SEO?
Machine Learning als Teil des Ranking-Algorithmus könnte dafür sorgen, dass Google zukünftig auf die Optimierung von statischen Rankingsignalen durch Webmaster und SEOs nicht mehr angewiesen ist.
Die Implementierung von strukturierten Daten in Form von Mark-Ups hat in der Vergangenheit nur sehr schleppend stattgefunden. So hat eine Untersuchung des Tool-Anbieters Searchmetrics aus dem Jahr 2014 ergeben, dass nur 0,3% der untersuchten Websites auf Schema.org Mark Ups setzen. Die Daten stammen aus Herbst 2013 und es ist anzunehmen. dass sich hier inzwischen etwas getan hat. Ich denke, aber das Google lieber auch ohne der technischen Mithilfe von Webmastern, Redakteuren und SEOs erkennen möchte, was sich hinter einem Inhaltsbaustein verbirgt. Die meisten Inhalts-Verantwortlichen kennen sich mit Mark-Ups nicht aus und wollen sich auch zukünftig nicht damit beschäftigen. Deswegen ist es für Google umso wichtiger Inhaltselemente auch ohne die Ausweisung strukturierter Daten zu interpretieren.
Auch was Optimierungen der Seitentitel, Alt-Tags von Bildern, etc. angeht haben viele Websites immer noch Nachholbedarf.
Anhand selbst lernender pro Nutzer individueller Such-Algorithmen kann Google alle Dimensionen bezogen auf den situativen Kontexts des jeweiligen Nutzers berücksichtigen. Jeder Nutzer hätte damit komplett eigene Suchergebnisse. Das wäre der letzte Schritt von Google zur Entmanipulierung ihrer Suchergebnisse.
Die Folgen für SEOs noch einmal kurz zusammengefasst:
- Noch personalisiertere Suchergebnisse als bisher nach Kontext des Nutzers
- Nur noch bedingte Mithilfe durch SEOs bzw. Webmaster für Google notwendig
- Manipulierung der Suchergebnisse quasi nicht mehr möglich
- Einfluss statischer Rankingfaktoren wie Seitentitel, Backlinks, Nutzung von Keywords, Alt-Tags für Bilder … nimmt weiter ab
- Aktive Optimierung nur für Suchmaschinen verliert noch mehr an Wichtigkeit
Das Ganze ist natürlich Zukunftsmusik und wann und ob überhaupt Google das Ranking komplett selbst lernenden Algorithmen übergibt bleibt abzuwarten. Dies würde mit einem nahezu kompletten Kontrollverlust durch Google einhergehen. Somit könnte Google überhaupt nicht mehr nachvollziehen, warum Rankings für den einen Nutzer so und für den anderen Nutzer so aussehen. Laut Aussage von John Mueller scheint der anarchistische Algorithmus auch bisher nicht angedacht, wie aus seiner Aussage aus dem Webmaster Hangout Anfang Dezember zu entnehmen ist:
Wir machen viel mit Machine Leraning, das ist ein faszinierendes Feld. Manchmal ist es spannend, dass die maschinellen Algorithmen auf etwas kommen, an das wir sonst nicht gedacht hätten. Dann versuchen wir herauszufinden, wie die Algorithmen darauf gekommen sind.
Es ist jedoch oft schwer, in dieser Umgebung die Fehler zu finden. Wenn wir also einen nur maschinell lernenden Algorithmus hätten, der alles macht, dann würde es sehrschwerwerden potentielle Fehler zu finden und zu beheben.
Man muss also die richtige Balancezwischen den verschiedenen Algorithmen finden. Alles muss reproduzierbar und verständlich sein, aber es muss auch Raum für Neuerungen geben.
Google scheint hier selbst noch nicht sicher zu sein wie viel Kontrolle sie an selbst lernende Algorithmen abgeben wollen. Wir werden es in Zukunft sehen oder auch nicht …
Mehr zum Thema Semantik und Machine Learning kann man hier bei uns im Blog lesen >>>
Expertenstimmen zum Einfluss von Machine Learning auf SEO
Hier einige weitere exklusive Stimmen von geschätzten Kollegen und SEO-Experten zu der Thematik Machine Learning und SEO:
 Christian Kunz: Christian ist Inhaber der Webseite SEO Südwest und Senior Project Manager Search bei 1&1. Dort ist er unter anderem für die Suche-Projekte der Marken WEB.DE und GMX verantwortlich.
Christian Kunz: Christian ist Inhaber der Webseite SEO Südwest und Senior Project Manager Search bei 1&1. Dort ist er unter anderem für die Suche-Projekte der Marken WEB.DE und GMX verantwortlich.
Für die SEOs wird sich nur wenig ändern. Pourquoi? Dazu muss man sich den Wirkungskreislauf von SEO-Maßnahmen, Nutzersignalen und den durch maschinelles Lernen angepassten Rankingfaktoren ansehen. Gehen wir aus vom wichtigsten Indikator, den eine Webseite an Google sendet: den Nutzersignalen. Dazu gehören zum Beispiel die Verweildauer, die Absprungrate, aber auch die Gesamtzahl der Besuche und der Page Impressions. Anhand dieser Nutzersignale kann Google erkennen, ob eine Webseite den Bedürfnissen der Besucher entspricht. Wird die Seite häufig besucht, gibt es viele wiederkehrende Besucher und bleiben diese länger auf der Seite, dann kann davon ausgegangen werden, dass die Inhalte der Seite den Besuchern gefallen.
Google verwendet die besonders beliebten Seiten (und damit meine ich nicht nur die großen Webseiten, sondern zum Beispiel auch kleine Nischenseiten zu speziellen Themen) und analysiert deren Aufbau. Dabei werden nicht nur die Inhalte bewertet, sondern zum Beispiel auch die Navigation, die Seitenstruktur, das Verhältnis von Text zu Bildern und so weiter. Natürlich weiß außer einem kleinen Kreis von Google-Mitarbeitern niemand genau, wie genau diese Analyse abläuft und welche Faktoren betrachtet werden. Man kann aber mit ziemlicher Sicherheit davon ausgehen, dass die beliebten Seiten als Blaupause für die Bewertung weiterer Webseiten genutzt werden. Dabei können sich die Rankingfaktoren und deren Gewichtung immer wieder ändern. Umso mehr eine Webseite dem jeweiligen Idealbild entspricht, desto besser die Rankingchancen der Seite.
Hier kommt die Suchmaschinenoptimierung ins Spiel: Aufgabe der SEOs ist es, die Webseiten ihrer Kunden an die jeweils aktuellen Rankingfaktoren anzupassen. Wenn zum Beispiel gerade das Thema Mobilfreundlichkeit wichtig ist, dann muss dafür gesorgt werden, die Webseite des Kunden für die Darstellung auf Smartphones zu optimieren. Geht es um sichere Datenübertragung, muss die Webseite auf TLS und idealerweise auf HTTP/2 portiert werden und so weiter.
Die SEO-Maßnahmen wirken sich wiederum auf die Nutzersignale aus, die dann zur weiteren Anpassung der Rankingfaktoren führen können – ein sich fortsetzender Kreislauf also.
Die Arbeit der SEOs ändert sich im Vergleich zu früher nicht viel, denn sie sind weiterhin im Unklaren darüber, welche Rankingfaktoren mit welchem Gewicht wirken. Sie können nur spekulieren. Der Unterschied zum alten Vorgehen besteht in zwei Dingen: Erstens werden sich die Rankingfaktoren zukünftig schneller ändern, denn maschinelles Lernen wird Anpassungen nahezu in Echtzeit ermöglichen. Zweitens werden Nutzersignale wie die Verweildauer oder die Absprungrate noch wichtiger als schon in der Vergangenheit, denn sie werden die Hauptindikatoren für Google zur Bewertung der Webseitenqualität sein.
Bei alldem darf natürlich nicht vergessen werden, dass es neben dem beschriebenen Mechanismus weiterhin auch andere Rankingfaktoren geben wird, die konstant bleiben. Die Relevanz der Inhalte auf einer Webseite zur jeweiligen Suchanfrage wird genauso einfließen wie die Autorität der Webseite, gemessen an Backlinks und Signalen aus den sozialen Netzwerken.
 Markus Hövener: Markus ist Gründer und Head of SEO der auf SEO und SEM spezialisierten Online-Marketing-Agentur Bloofusion (www.bloofusion.de). Als geschäftsführender Gesellschafter von Bloofusion Germany ist er verantwortlich für alle Aktivitäten in Deutschland, Österreich und der Schweiz. Markus Hövener ist Chefredakteur des Magazins suchradar (www.suchradar.de) und Blogger bei den Internetkapitänen (www.internetkapitaene.de). Außerdem ist er Autor vieler Artikel und Studien rund um SEO und SEM und spricht auf vielen Online-Marketing-Konferenzen.
Markus Hövener: Markus ist Gründer und Head of SEO der auf SEO und SEM spezialisierten Online-Marketing-Agentur Bloofusion (www.bloofusion.de). Als geschäftsführender Gesellschafter von Bloofusion Germany ist er verantwortlich für alle Aktivitäten in Deutschland, Österreich und der Schweiz. Markus Hövener ist Chefredakteur des Magazins suchradar (www.suchradar.de) und Blogger bei den Internetkapitänen (www.internetkapitaene.de). Außerdem ist er Autor vieler Artikel und Studien rund um SEO und SEM und spricht auf vielen Online-Marketing-Konferenzen.
Grundsätzlich ist Machine Learning für Google ja nichts neues. Die haben zwar erst vor einigen Wochen TensorFlow („Open Source Software Library for Machine Intelligence“) veröffentlicht, aber das Thema verfolgt Google ja schon seit langem. So basiert ja schon das Panda-Update auf dem, was Googles Maschinen aus guten und schlechten Websites lernen konnten.
Für Google ist Machine Learning wahnsinnig wichtig, da sie so effizient arbeiten können und aus den gewaltigen Datenmengen Sinn machen können. Für klassisches SEO ist das natürlich der Exodus: Man kann Google halt nicht mehr mit einfachen Mitteln reinlegen und etwas mit geringer Qualität in etwas verwandeln, das Google trotzdem mag.
Für SEOs ergibt sich also ein Nachteil – aber zeitgleich auch ein Vorteil, denn es geht ja schon lange nicht mehr darum, eine bestimmte Keyword-Dichte einzuhalten. Es geht für uns als Agentur wirklich darum, den Kunden dahin zu bringen, eine erstklassige Website mit herausragenden Inhalten zu haben.
 Marcus Tober: Marcus ist nicht nur als Gründer, Geschäftsführer und treibende Kraft von Searchmetrics über einschlägige SEO Kreise hinaus bekannt, sondern auch als Impulsgeber und Experte auf vielen internationalen Bühnen: Der „Big Data und Statistik-Freak“ (Tober über Tober) ist bei Kongressen, Symposien und Think Tanks weltweit ein gefragter Gast und Keynote Speaker.
Marcus Tober: Marcus ist nicht nur als Gründer, Geschäftsführer und treibende Kraft von Searchmetrics über einschlägige SEO Kreise hinaus bekannt, sondern auch als Impulsgeber und Experte auf vielen internationalen Bühnen: Der „Big Data und Statistik-Freak“ (Tober über Tober) ist bei Kongressen, Symposien und Think Tanks weltweit ein gefragter Gast und Keynote Speaker.
In 2016 wird für den SEO explizites Analysieren oder Anwenden von Machine Learning Funktionen nicht Bestandteil der Arbeit sein. Auch wenn Machine Learning längst allgegenwärtig ist und die Grundlage für zig Updates die Suchmaschinen in den letzten Jahren gemacht haben. Was bedeutet das? Suchmaschinen benutzen schon seit vielen Jahren die gelernten Daten aus vorherigen Updates (Panda 1,2,3 etc, Penguin) und mache täglich Tests aus denen sie wiederum Anpassungen vornehmen die zu weiteren Updates führen. Bei Google ist der ständige Everflux, quasi die andauernde Bewegung der Ergebnisse.
Userdaten dienen mindestens dazu zu bewerten ob die Features die Google eingebaut oder geändert zu Verbesserungen geführt hat. Für uns SEOs heißt das ingesamt dass die abhängig von guten Ergebnissen (Rankings) weniger von nur ein paar Faktoren abhängt. Vielmehr müssen SEOs immer den Kontext berücksichtigen. Sprich die Faktoren warum eine Page erfolgreich ist können stark abweichen wenn man verschiedene Branchen oder Keywords zwischen Shorthead und Longtail betrachtet. 2016 wird sich also der Trend fortsetzen dass sich SEO je nach Webseite, Branche und natürlich Gerät (Desktop, Mobile) ändern wird und man unterschiedliche Strategien braucht um holistisch erfolgreich zu werden.
 Sebastian Erlhofer: Sebastian ist geschäftsführender Gesellschafter der mindshape GmbH aus Köln und Bestsellerautor des Buches „Suchmaschinen-Optimierung“. Er betreibt SEO seit 2002 und freut sich auf die nächste SEO-Dekade
Sebastian Erlhofer: Sebastian ist geschäftsführender Gesellschafter der mindshape GmbH aus Köln und Bestsellerautor des Buches „Suchmaschinen-Optimierung“. Er betreibt SEO seit 2002 und freut sich auf die nächste SEO-Dekade
Als Suchmaschinen-Optimierer ist man ja gewohnt, regelmäßig sich mit neuen Technologien und Bewertungsmechanismen auseinander zu setzen. Vor 10 Jahren waren es noch ganz einfache statistische Verfahren, die ein Dokumententreffer und ein Ranking ausmachten: Wenn ein bestimmtes Keyword in der Meta-Beschreibung stand, dann kam das Dokument in die Treffermenge. Und wenn das Keyword noch häufig vorkam im Dokument, dann wurde dieses auch gut geranked. Heute ist – wie jeder SEO weiß – die ganze Geschichte etwas vielfältiger. Nach der Keyworddichte kam WDF*IDF und mittlerweile geht es um holistische, verständliche und nutzerorientierte Texte, die möglichst multimodal mit Videos, Infografiken und Co aufbereitet sein sollen. Links verlieren stetig an Bedeutung bzw. die Qualität der Links ist immer wichtiger. Soweit so klar.
Was verändert maschinelles Lernen dann eigentlich? Meiner Meinung nach ist das eine weitere Stufe in der Suchmaschinen-Optimierung. Mit zunehmender Rechnerkapazität und verstärkter Forschung werden Computerprogramme immer besser darin, bestimmte Entitäten zu verstehen, zu klassifizieren und letztendlich Rankings zu generieren. Irgendwann – aber das ist meiner Meinung nach noch Jahre entfernt – wird maschinelles Lernen eingesetzt werden können, damit Algorithmen sich selbst optimieren und verbessern. Hier sind wir dann im Bereich der künstlichen Intelligenz oder vielleicht sogar von künstlichen Lebensformen. Die Einflüsse des maschinellen Lernens auf SEO sind schleichend. RankBrain und Co. kommen Stück für Stück und die Forschungsergebnisse von den schlausten Forschern, die sich Google weltweit kaufen kann, werden über die nächsten Jahre spannende „Rankingfaktoren“ produzieren.Ich denke nicht, dass wir in den nächsten zwei bis drei Jahren signifikante Auswirkungen auf unsere Arbeit als SEOs spüren werden – nicht anders als sonst auch: Es werden neue Verfahren kommen und wir werden versuchen, sie zu verstehen und zu optimieren. Im Vergleich zu Beispielen aus der Vergangenheit, etwa WDF*IDF, werden allerdings noch mehr SEOs thematisch aussteigen. Heute schon können viele SEOs kaum die Hintergründe von WDF*IDF korrekt und vollständig erklären. Man nutzt die Tools und gut ist. Das reicht auch, um hier und da gut zu optimieren und Dienstleistungen zu verkaufen. Der Einäugige ist unter den Blinden immer der Sehende. Aber maschinelles Lernen mit neuronalen Netzen, Entscheidungsalgorithmen und anderen Dingen sind nicht für Laien verständlich – ich habe selbst im Informatikstudium mich alleine nur mit den Grundlagen beschäftigt (d.h. vor allem viel Mathematik die dahinter steckt) und es ist wahnsinnig komplex. Seit mittlerweile Generationen beschäftigen sich Forscher damit, Computerprogrammen das Lesen und Verstehen von Texten beizubringen. Wir sollten als SEOs nicht den Anspruch haben, das verstehen zu können oder zu wollen.
Wir sollten trotz des Fortschritts auf technischer Seite das im Fokus behalten, was unsere Arbeit ausmacht: Produkte und Dienstleistungen von unseren Kunden in den Suchergebnissen sichtbarer machen (um SEO einmal ganz klassisch zu definieren). Wir müssen Abschied nehmen von Glaubenssätzen wie „das hat bei anderen Sites auch so funktioniert“ und wir müssen uns verabschieden von den Tipps und Tricks, den Abkürzungen, die es früher gab, um schneller zu optimieren. Ich freue mich auf das jetzige und zukünftige SEO, weil es gezwungen nachhaltiger wird und damit zwingend auf den Menschen fokussiert werden muss. Nicht mehr auf Google. Denn spätestens wenn in ein paar Jahren maschinelles Lernen große Teile im Algorithmus ausmacht, und daran glaube ich definitiv, wird auch kein Ingenieur bei Google mehr irgendwelche logischen Zusammenhänge erklären können. Das können Sie heute im Prinzip schon nicht mehr. Am Ende können wir alle dann nur noch versuchen, die Entscheidungen des Rankalgorithmus nachzuvollziehen. Eben genau so, wie wir Entscheidungen von Mitmenschen nicht immer detailliert in ihre Bestandteile sezieren können, aber wir können sie nachvollziehen. Ich freu mich drauf!
 Marcel Schrepel: Marcel ist Geschäftsführer und Gründer der Onlinemarketing-Agentur trust in time in Berlin. Die fachlichen Schwerpunkte der Agentur liegen im Suchmaschinenmarketing für D-A-CH und Russland (Yandex). Marcel ist überzeugter Slow-Blogger und schreibt Fachartikel über Suchmaschinenoptimierung (SEO), Google und die moderne Welt des Web 2.0. Er beschäftigt sich gerne mit Strategieentwicklung und Kommunikationswissenschaft und ist nebenbei als Lehrbeauftragter tätig.
Marcel Schrepel: Marcel ist Geschäftsführer und Gründer der Onlinemarketing-Agentur trust in time in Berlin. Die fachlichen Schwerpunkte der Agentur liegen im Suchmaschinenmarketing für D-A-CH und Russland (Yandex). Marcel ist überzeugter Slow-Blogger und schreibt Fachartikel über Suchmaschinenoptimierung (SEO), Google und die moderne Welt des Web 2.0. Er beschäftigt sich gerne mit Strategieentwicklung und Kommunikationswissenschaft und ist nebenbei als Lehrbeauftragter tätig.
Durch die Digitale Revolution und die Computerisierung unserer Gesellschaft, haben sich Kommunikations- und Informationsprozesse seit der Jahrtausendwende gewaltig geändert. Fast alles ist digitalisiert und Nutzer- sowie Nutzerverhalten lassen sich immer besser in Form von Daten darstellen. Durch die zunehmende mobile Nutzung lässt sich das Nutzungsverhalten von Menschen auf immer mehr Ebenen messen und algorithmisch aus- und verwerten.
Maschinelles Lernen gibt es nicht erst seit gestern. Das Finden von Gesetzmäßigkeiten in Daten ist meiner Meinung nach die Kernfunktion von Google (Information Retrieval System).Man sollte meinen, dass man aus all diesen Modellen, da stark datengetrieben, SEO relevante Muster und Daten generieren kann, die man strategisch einsetzen kann. Viele verwechseln das immer noch mit Korrelationen. Man vergisst gerne schnell die Komplexität, mit der Algorithmen heutzutage arbeiten. Google-Algorithmen, KI-Modelle und erhobene Daten – das sind alles Variablen in einer „SEO-Rechnung“, die wir nicht kennen, auch wenn das vor 10 Jahren vielleicht noch anders war.
Menschen sind launisch und verändern ihre Gewohnheiten. Lebenslagen und Jobs wechseln. Krankheit, Heirat, Kinder sind einschlägige Ereignisse. Algorithmen werden von diesen Veränderungen lernen, inwiefern sich ein Nutzer anders im Netz bewegt.
„Emotionale Intelligenz“ ist das Stichwort.
Suchmaschinen wie Google wollen auch genau das lernen, damit der Algorithmus eine gewisse Flexibilität besitzt. Durch Machine Learning bedarf es keiner ständigen Einspielung separater Algorithmen oder Algorithmus-Updates – durch Machine Learning selbst wird ein Algorithmus erst flexibel und erweitert sein „Wissen“ auf selbstständige Art und Weise – dauerhaft und zeitgemäß.
Google wird in nicht allzu ferner Zukunft in der Lage sein, Menschen zu verstehen, sie kennen zu lernen und zu erahnen, was sie als nächstes tun werden. Aktuell arbeitet Google schon mit Mustern, z.B. die personalisierte Suche oder Hummingbird.
Dem ein oder anderen dürfte vielleicht das „Google Opinion Reward“ – Programm etwas sagen.
https://www.google.com/insights/consumersurveys/google_opinion_rewards
Auf den ersten Blick scheint dies wie ein Tool für Marktforscher zu wirken. Denkt man das Ganze aber etwas utopischer in die Höhe, so könnte Google theoretisch mit solchen Umfragen auch wertvolle Zusatzdaten über einen Nutzer generieren. Daten, die sich nicht aus dem normalen Sucherverhalten schöpfen lassen, die aber zur Erstellung von Lern-Modellen unbedingt benötigt werden. Quasi ein Vorzeigedatensatz zur Referenzierung in den Lern-Algorithmen.
Das Gleiche unterstelle ich Facebook mit dem Kauf von WhatsApp.Ich denke, dass sich SEO weiterhin in eine empathiegetriebene, zielgruppenorientierte Richtung entwickeln wird, was ja einige SEO´s schon länger praktizieren. Alleine deswegen, weil SEO längst nicht mehr rein datengetrieben funktioniert. Conversion Prozesse sind längst nicht mehr einzig und allein an die Auffindbarkeit eines Angebots gekoppelt. Traffic allein ist kein Garant für eine Conversion.
Ich denke, dass Machine Learning nur ein Faktor von etlichen ist, der dafür sorgen wird, dass einheitliche Rankings verschwinden werden. Schon jetzt sind die Unterschiede messbar.
 Kai Spriestersbach: Kai ist Online Strategy Consultant und strategischer Partner der eology GmbH sowie Inhaber der strategischen SEO-Beratung SEARCH ONE. Er berät und begleitet ausgewählte Kunden bei der Positionierung im Internet sowie der Verbesserung ihrer Online-Präsenz mit Blick auf die Sichtbarkeit in den Suchmaschinen. Derzeit forscht und entwickelt er an neuen Ansätzen für Marketing Software sowie Website-Projekten und bereitet sein erstes Buchprojekt vor.
Kai Spriestersbach: Kai ist Online Strategy Consultant und strategischer Partner der eology GmbH sowie Inhaber der strategischen SEO-Beratung SEARCH ONE. Er berät und begleitet ausgewählte Kunden bei der Positionierung im Internet sowie der Verbesserung ihrer Online-Präsenz mit Blick auf die Sichtbarkeit in den Suchmaschinen. Derzeit forscht und entwickelt er an neuen Ansätzen für Marketing Software sowie Website-Projekten und bereitet sein erstes Buchprojekt vor.
In der näheren Zukunft stehen uns spannende Veränderungen ins Haus. Aber Machine Learning ist nicht neu. Die beiden Updates Panda und Penguin basieren bereits auf Machine Learning Technologie und werden nun zu einem sich kontinuierlich selbst verbessernden System ausgebaut. Anhand der Informationen über das Panda Update, die allesamt sehr vage und auf einem sehr viel abstrakteren Level waren (z.b. Würden Sie dieser Seite Ihre Kreditkarteninformationen anvertrauen) wird klar, dass es in Zukunft noch weniger Informationen von Google über Updates und direkte Rankingfaktoren geben wird.
Zum einen liegt das daran, dass Deep Learning Algorithmen selbst erkennen, welche Metriken relevant sind und die Engineers bei Google keinen Einfluß mehr darauf haben und zum anderen sehr viel mehr Daten in das Ranking einfließen werden. Hier bei ist alles vorstellbar – Googles Mitarbeiter sind sehr kreativ – wieso nicht die (auf den ersten Blick) absurdesten Informationen über Webseiten einfach mal in das System kippen und die Maschine untersuchen zu lassen, was davon sich als Rankingfaktor eignet.
Deutlich wichtiger und auch sehr viel schneller spürbar werden Nutzerdaten in das Ranking einfließen. Eine schlechte Seite wird trotz toller Optimierung und vieler Links alleine durch die Signale unzufriedener Nutzer nach unten rutschen. Das ist zwar bisher schon der Fall, allerdings nur bei sehr großen Suchvolumen und über längere Zeiträume. Hier wird Google sehr viel schneller reagieren können.
Ich betrachte selbst die Entwicklungen als sehr positiv, denn wer sich darauf konzentriert den Nutzern genau das zu bieten, was diese Suchen, wird sehr viel stärker profitieren als bisher.
 Sepita Ansari: Sepita, Geschäftsführer der Catbird Seat GmbH, ist einer der anerkanntesten SEO-Experten in Deutschland. Seit 2005 beschäftigt sich Sepita Ansari mit Online Marketing. Der Wirtschafts-und Sozialwissenschaftler war 3 Jahre bei der Scout24-Gruppe tätig und hat dort das JobScout24-Online Team geleitet.
Sepita Ansari: Sepita, Geschäftsführer der Catbird Seat GmbH, ist einer der anerkanntesten SEO-Experten in Deutschland. Seit 2005 beschäftigt sich Sepita Ansari mit Online Marketing. Der Wirtschafts-und Sozialwissenschaftler war 3 Jahre bei der Scout24-Gruppe tätig und hat dort das JobScout24-Online Team geleitet.
Früher bedienten wir die Technik, heute dient die Technik uns und lernt und interagiert mit uns. Dank zahlreicher Sensoren, ist ein interaktiver Umgang mit Computern möglich geworden, dabei ist das Smartphone zum persönlichen Alltagsmanager geworden. Algorithmen und die künstliche Intelligenz „verstehen“ zunehmend den Bedeutungszusammenhang und liefern relevante Ergebnisse. Diese Maschinen werden uns weiter unterstützen und gar imitieren, ersetzen werden sie uns aber nicht.
Mit Hilfe von Daten können Suchmaschinen (mit stochastischer Wahrscheinlichkeit) das menschliche Suchverhalten vorhersagen, mit Hilfe von Mathematik kann die Suchvergangenheit erklärt werden. Die Zukunft kann jedoch nicht mit 100% Güte prognostiziert werden. Da unser menschliches (Such-)Verhalten auf individuellen Interpretationen und Bewertungen beruht, kann eine Maschine dieses noch schwer vorhersehen, aber sehr gut erklären. Diese Erklärbarkeit der Daten wird auch im SEO zum erfolgsentscheidenden Kriterium: Inhalte müssen individuell ansprechen, strukturiert sein und optimal innerhalb der User Journey auf den verschiedenen Medien und Geräten auf den Nutzer zugeschnitten werden. Damit wird die Datenstruktur, die -transparenz und –validität zu einem wichtigen Faktor innerhalb der Suchmaschinenoptimierung.
(poll id = "2")
Weitere Beiträge zum Thema Machine Learning und SEO
Videos zum Thema Machine Learning und Artificial Intelligence


