L'introduction de la recherche sémantique dans la mise à jour de Hummingbird en 2013 a fondamentalement modifié la recherche de Google et, partant, l'expérience utilisateur de Google. Hummingbird n'est pas sans raison considéré comme l'une des plus importantes mises à jour de Google dans l'histoire.
L'introduction du Knowledge Graph et de l'algorithme Hummingbird a façonné ma vision du référencement. Je travaille sur ce sujet depuis 2013 Sémantique et entités dans l'optimisation des moteurs de recherche,
Je souhaiterais mettre l’accent sur une série de classements basés sur des entités et sur le référencement sémantique, présentés ici sur le blog plus tard cette année.
Pour cela, je planifie chaque mois une contribution.
Je m'en occupe beaucoup Google Brevets. Informations des officiels de Google ainsi que le Aide Googlepropres expériences et opinions d’autres collègues. Celles-ci sont constamment incluses dans les contributions actuelles. En outre, je vais réviser et mettre à jour les contributions existantes des 5 dernières années.
Dans cet article, vous trouverez un aperçu actualisé de tous les articles écrits sur le référencement sémantique ici dans le blog. Il est mis à jour tous les mois.
Je mettrai à jour cet aperçu chaque mois avec le dernier post. Les premières contributions doivent être comprises comme une introduction au sujet. Tous les autres articles sont un peu plus en profondeur.
la Graphique de connaissances est la base de données sémantique de Google. Ici, les entités sont liées les unes aux autres, dotées d'attributs et dans un contexte thématique ou ontologies apporté. Ce faisant, les nœuds d'entités et la manière dont ces entités sont liées sont représentés sous forme d'arêtes … En savoir plus sur le graphique de connaissances de Google.
la algorithme de Hummingbird est l'algorithme de classement actuel de Google. colibri trop allemand Kollibri est basé sur une interprétation sémantique des requêtes de recherche, des documents et des autorités. En savoir plus sur Google Hummingbird ici.
Les entités jouent un rôle particulier pour Google depuis l'introduction de l'algorithme Hummingbird et, partant, pour l'optimisation des moteurs de recherche. L'optimisation des sujets et des entités remplace de plus en plus l'optimisation classique par des mots clés. En savoir plus sur les entités:
Dans cet article, je voudrais partager une découverte que j'ai faite avec vous sur Google. Google aimerait probablement avoir le vôtre dans le futur Boîte Entités ou panneau de connaissances peut réclamer et modifier.
Il s’agit de la quatrième partie d’une série de publications sur le référencement sémantique et aborde la question de savoir si Google comprend vraiment le sens des documents et des requêtes de recherche, ou s’il ne s'agit que d’une analyse statistique.
Les entités jouent un rôle de plus en plus important dans l'indexation pour Google depuis Knowledge Graph et Hummingbird. Je vais entrer dans cela plus en détail dans ce post.
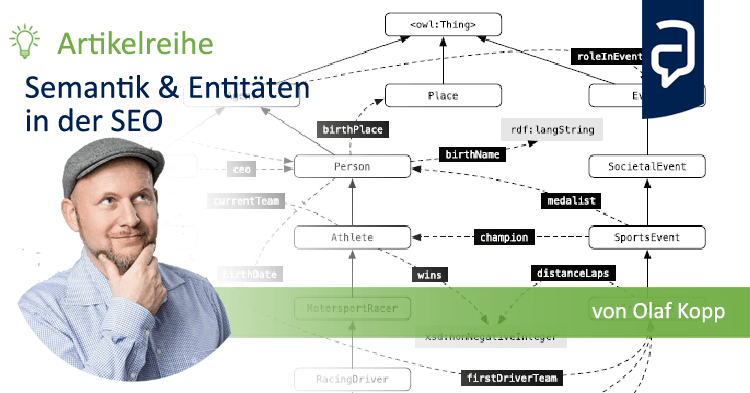
Il existe peu d'informations sur les éléments importants du graphe de connaissances Google, tels que les types d'entité, les classes et les attributs, ainsi que sur l'analyse des relations entre ces éléments. Une raison plus dans le contexte de ma série d'articles sur l'optimisation des moteurs de recherche sémantiques pour répondre.

Le principal défi que doit relever Google en matière de recherche sémantique consiste à identifier et à extraire des entités et leurs attributs à partir de sources de données telles que des sites Web. Ces informations sont généralement non structurées et non exemptes d'erreurs. Le Knowledge Graph actuel en tant que centre sémantique de Google repose en grande partie sur le contenu structuré de Wikidata et les données semi-structurées de Wikipédia ou de Wikimedia.
Avec les bases de données de connaissances telles que le graphique de connaissances, il est difficile de maintenir l'équilibre entre l'exhaustivité et l'exactitude des informations. Une condition nécessaire pour être complet est que Google puisse identifier, interpréter et extraire des informations dans des sources de données non structurées. Plus à ce sujet dans ce post.
Dans cet article, je vais approfondir le traitement du langage naturel pour l'exploration de données et plus particulièrement le graphe de connaissances et les moteurs de recherche.
La présence de fonctionnalités SERP telles que Knowledge Panel et Knowledge Cards dans les SERP de Google s'est développée rapidement depuis des années. En conséquence, les résultats de recherche classiques ont également reçu des "Liens bleus" appelés de plus en plus de concurrence lorsqu'il s'agit d'attirer l'attention des demandeurs. Ou mieux l'appeler le "questionneur". Parce que la plupart des requêtes de recherche sont des questions formulées implicitement et qui nécessitent une réponse. Google veut répondre directement aux questions avec les fonctionnalités du SERP. Ces fonctionnalités sont une fenêtre dans le Graphique de connaissances Google ou y sont directement ou indirectement liés.
Cet article devrait permettre de mieux comprendre le fonctionnement des différentes fonctionnalités du SERP telles que le Panneau de connaissances et les Cartes de connaissances.
Cet article de ma série d'articles sur la sémantique et les entités dans le référencement et Google examine le rôle des entités dans l'interprétation des requêtes de recherche. Amusez-vous à lire!


