
Sommaire
Depuis plus de deux ans, les moteurs de recherche intègrent de plus en plus d’entités et de faits sous forme de graphiques de connaissances ou de représentations de carrousel dans les résultats de recherche. Il y a quelques jours à peine, Google annonçait déjà que près de 25% de toutes les requêtes de recherche de ce graphe de connaissances seraient affichées.
Cela signifie donc que Google fournit des faits clairs et des entités à un quart des recherches. Selon les statistiques actuelles, cela représente environ 6 milliards de demandes par jour. Et à partir de ces mêmes recherches et combinaisons d'entités, de la sémantique permettant de comprendre le cœur de la recherche et de toutes les données que nous fournissons sur des pages Web, Google apprend chaque jour.
Le brevet de Google intitulé "Générer des connexions perspicaces entre des entités graphiques" indique:
"Les implémentations fournissent un résultat de recherche étendu pour améliorer l'expérience de recherche de l'utilisateur. Par exemple, le résultat peut inclure des informations pertinentes, pertinentes pour la requête, qui n'étaient pas explicitement demandées, mais qui pourraient intéresser l'utilisateur, telles que les relations entre deux entités correspondant à la requête (…). Des faits uniques peuvent être d’excellents attributs pour une entité, tels que le plus grand acteur, le président le plus âgé, le titre le plus cher, etc. (…). "
Comment Google représente-t-il les entités et d'où proviennent les données?
Google utilise plusieurs sources pour les résultats d'entité. Par exemple, Wikipedia et Freebase, où la base de données Freebase sera fermée et transférée sur Wikimedia cette année, serviront de sources officielles. Mais vous avez certainement aussi accès aux données de tous les sites Web dans l'index des moteurs de recherche. La raison pour laquelle Google présente des entités et des faits sous la forme de graphiques de connaissances est logique. Google souhaite enregistrer les clics de l'utilisateur sur des sites Web et la recherche d'informations, si la recherche ne nécessite qu'une réponse simple mais précise. Par exemple, la date de naissance de Jan Böhmermann. Ce serait moins convivial si l'utilisateur appelait d'abord l'article de Wikipedia ou d'autres sources et qu'il devrait le chercher. Le moteur de recherche le rend plus facile et plus rapide. Et pourtant, de nombreux propriétaires de sites Web considèrent ces graphiques dans les SERP comme un grand danger.
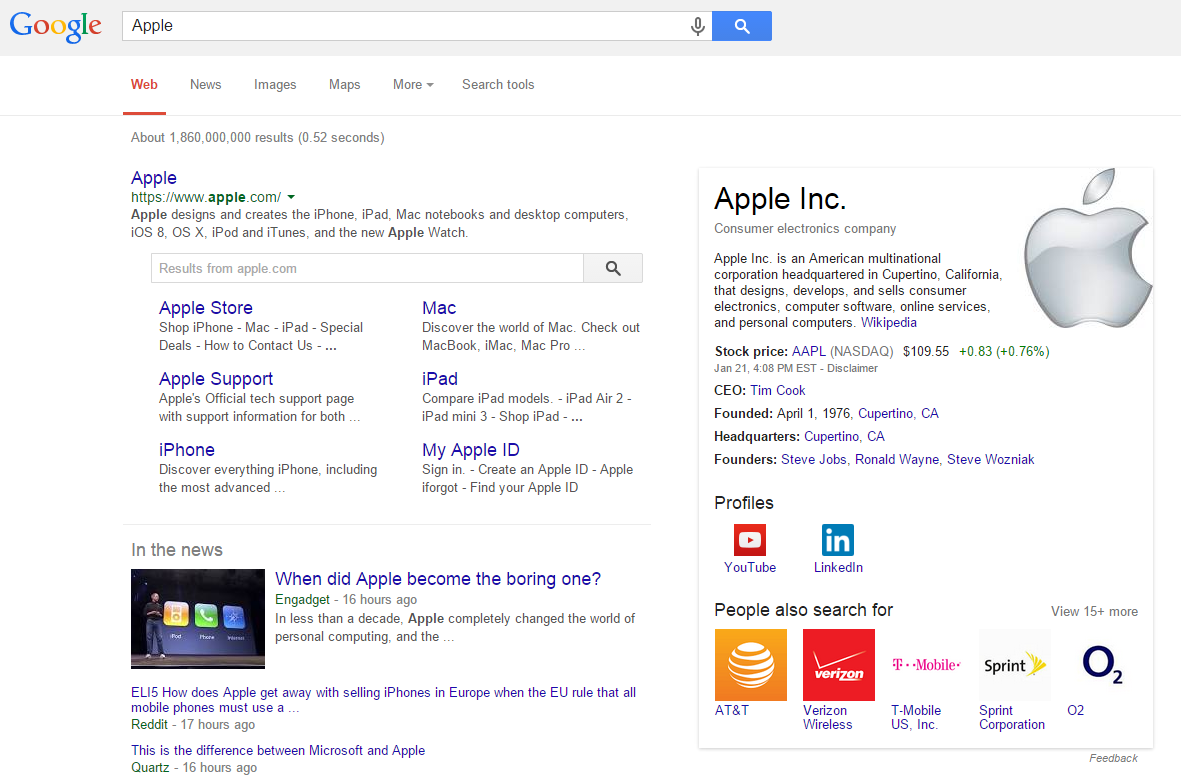
Figure 1: Knowledge Graph pour rechercher "Apple"
Le défi qui se pose à Google est de reconnaître ce qui est recherché. Savoir si et comment Google comprend la lecture interligne devient particulièrement évident dans les entités. Ma recherche de "pomme" pourrait aussi signifier une pomme. Mais si Google intègre l'historique de mes recherches et mes centres d'intérêt en fonction des données de mon navigateur, de l'historique, des informations de Google+ et d'autres données, la tendance est plus technique que biologique. À mon avis, le moteur de recherche peut mieux comprendre l'arrière-plan d'une requête de recherche par utilisateur individuellement. Un autre exemple serait "Jaguar": Google ne semble pas sûr à 100% et me propose donc des informations sur l'animal situé sous la marque automobile Knowledge Graph.
Le graphique de connaissances est-il vraiment une menace pour les propriétaires de sites Web?
Lorsque Google a déployé les graphiques de connaissances en 2013 et les a utilisés pour une grande partie des recherches d'entités, l'un des sites Web qui a le plus souffert était Wikipedia. Lorsque vous recherchez des entités, Wikipedia figure parmi les meilleurs résultats. La Wikipédia allemande a enregistré une baisse de 17% du nombre de visiteurs au quatrième trimestre de 2013 uniquement.
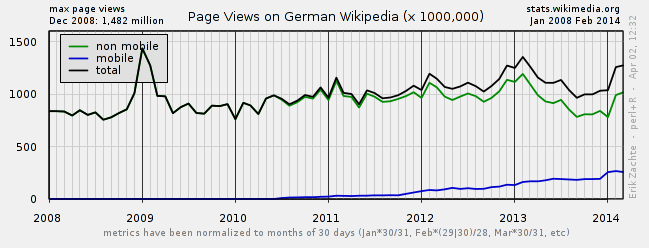
Figure 2: Statistiques d'accès de Wikipedia allemand (2008 à 2014) reportcard.wmflabs.org
Et dès 2014, les graphiques de connaissances étaient à nouveau rares, ce qui a également permis de rendre l'accès à Wikipedia plus rapide. Surtout sur les appareils mobiles, la présentation dans les SERP est populaire. Sur le smartphone, chaque clic ou contact enregistré est encore plus pratique pour l'utilisateur, car le temps de chargement est souvent beaucoup plus long que sur les appareils de bureau.
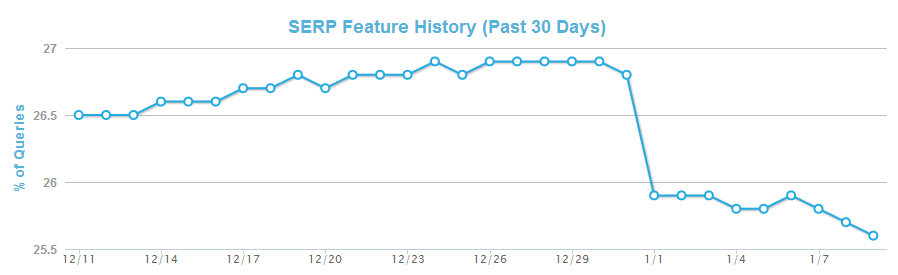
Figure 3: Knowledge Graph Ads – Début 2014 (mozcast.com)
La question qui se pose maintenant est la suivante: Wikipédia et Knowledge Graph ont-ils encore du trafic pour d'autres sites Web lorsqu'il s'agit d'entités? À mon avis, définitivement oui! La raison de cela, je vais expliquer avec l'exemple de Jan Böhmermann, modérateur du magazine NEO chez Royale:
Jan Böhmermann est une entité qui possède suffisamment de connaissances factuelles et référencées. En bref, Jan a un graphe de connaissances. Le mois dernier, environ 88% des requêtes de recherche qui affectaient uniquement l'entité "Jan Böhmermann" présentaient ce graphique.
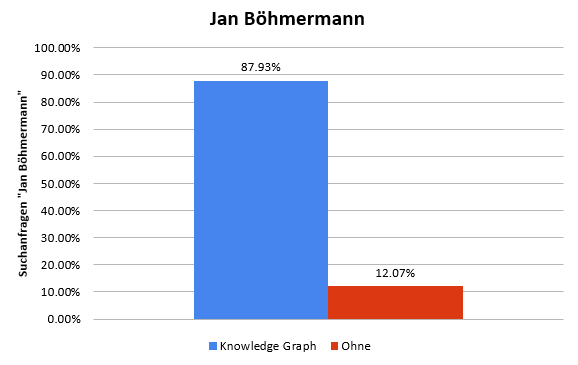
Figure 4: Statistiques: requêtes de recherche avec et sans Google Knowledge Graph
Cela ne signifie pas que seulement 12% de ces requêtes de recherche ont cliqué sur des liens de résultats de recherche. Et encore moins, cela signifie que la recherche d'entités se termine inévitablement toujours dans Wikipedia, comme le montre le trafic de l'article sur Jan Böhmermann dans Wikipedia de la même période.
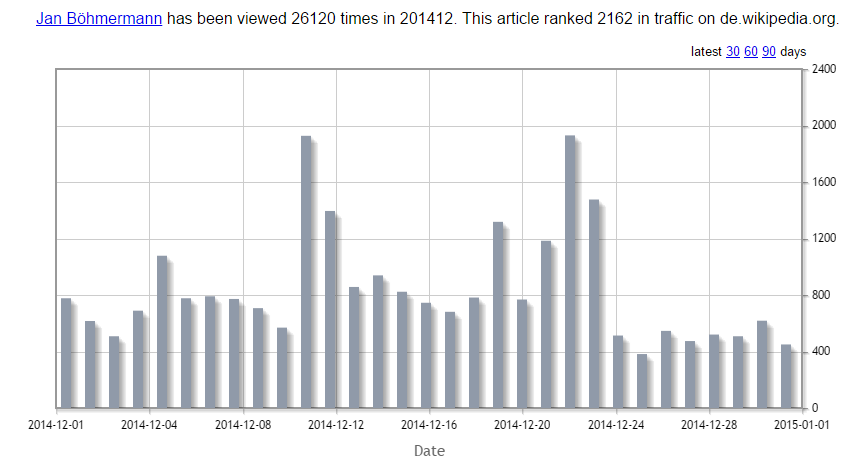
Figure 5: Vues d'articles de l'article de Wikipedia "Jan Böhmermann"
Les 26 120 pages consultées dans l'article de Wikipédia sont neutralisées par 74 350 requêtes Knowledge Graph, avec seulement une fraction des 26 120 vues générées par Google. Sans connaître le pourcentage exact de références organiques à l'article du wiki, je suppose un ratio de 80/20. Dans environ 80% des requêtes de recherche avec Knowledge Graph, dans ce cas, le résultat de Wikipedia n'est pas cliqué.
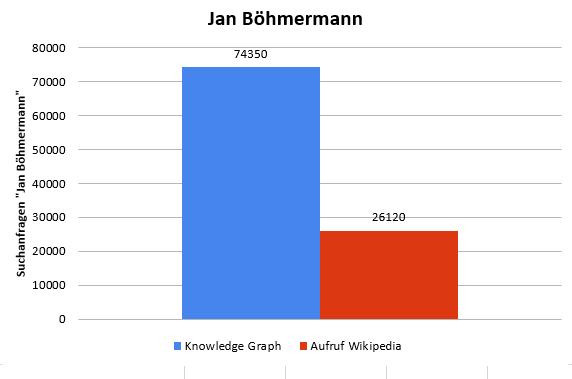
Figure 6: Statistiques: Google Knowledge Graph vs. pages vues Wikipédia
La crainte d'un "complot Google-Wikipedia", qui empêche les clics de nous, opérateurs de sites Web, n'est donc pas compréhensible. Bien sûr, certains sites Web enregistrent une baisse du trafic, mais cela ne signifie pas que Knowledge Graph est en faute.
Le résumé de l'évaluation du terme de recherche "Jan Böhmermann" en décembre 2014:

Tableau 1: Statistiques pour la requête "Jan Böhmermann"
La sémantique le rend possible!
La sémantique joue un rôle important dans la connexion d'entités. Pour Google, tout d’abord, l’intention de la requête de recherche est de comprendre exactement. Ce n’est qu’alors que le graphe de connaissances pourra être imprimé correctement. Si vous regardez par exemple, "Qui a fondé Apple?", Google doit savoir qu'il ne s'agit pas d'Apple, mais les fondateurs Steve Jobs et Steve Wozniak sont recherchés. Le point de départ dans ce cas est l'entité Apple, mais en conséquence, d'autres faits sont attendus.
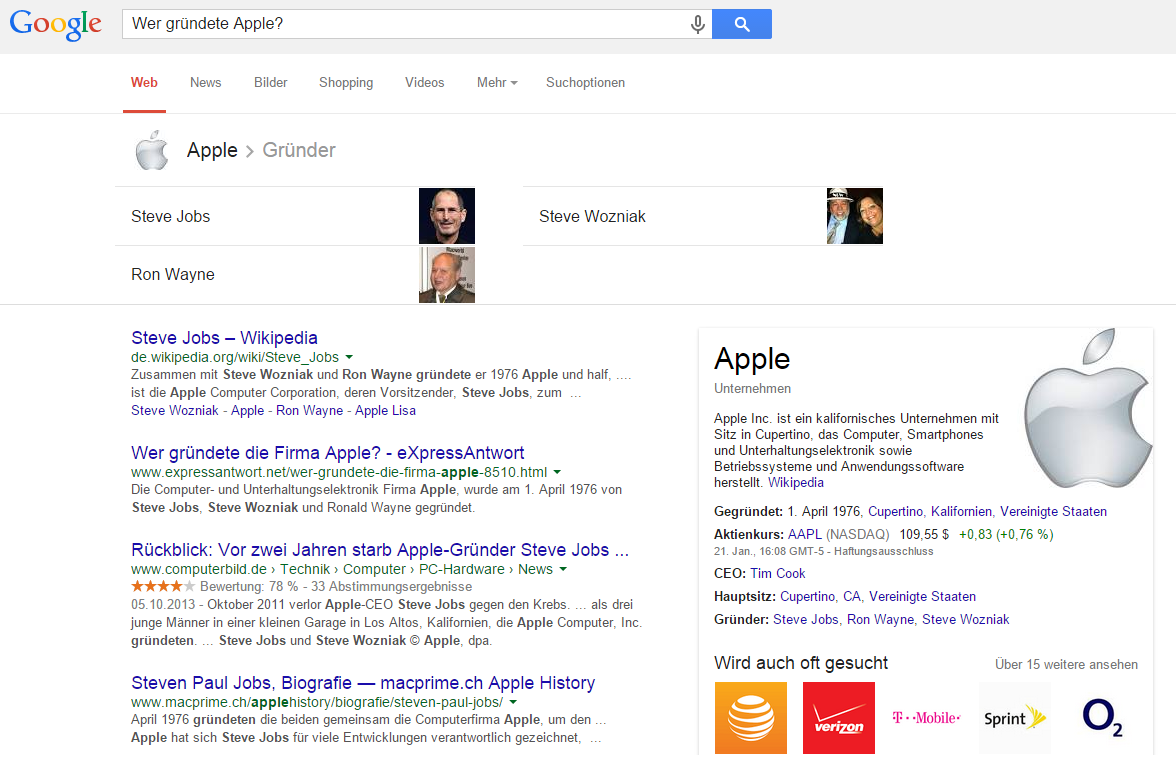
Figure 7: Recherche Google pour "Qui a fondé Apple?"
Si nous inversons la requête de recherche, Google peut ne pas la gérer correctement ou ne peut tout simplement pas décider de plusieurs résultats d'entité. La requête "Quelles entreprises ont fondé Steve Jobs?" Ne génère pas de résultat de graphique de connaissances. Pour les places 1 et 2 sont occupés avec des articles de Wikipedia à Steve Jobs et NeXT. De Apple, cependant, n'est pas grand chose à voir en premier.
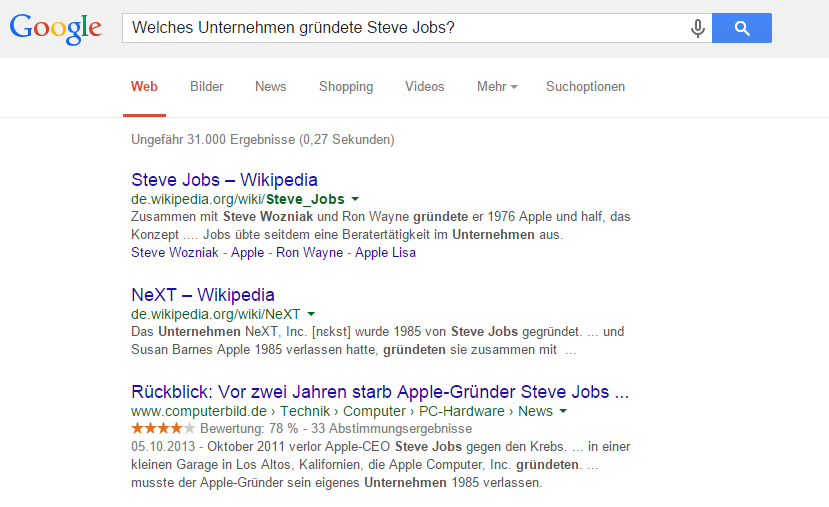
Figure 8: Recherche Google pour "Quelle entreprise a fondé Steve Jobs?"
Un autre exemple montre encore plus clairement le fait que les termes appartiennent à une catégorie d'entités superordonnées. Si nous recherchons "Sights in Salzburg", Google met déjà en évidence dans les SERP toutes les autres entités liées par cette catégorie. Si l'on compare les résultats dans le carrousel de la liste des liens avec les termes en gras dans les descriptions de page, on s'aperçoit qu'ils se recouvrent. Google nous montre ici que la connexion des entités n’est pas seulement importante pour les graphes de connaissances. Même sur les pages Web, le moteur de recherche détecte rapidement si la rubrique contient les termes associés.
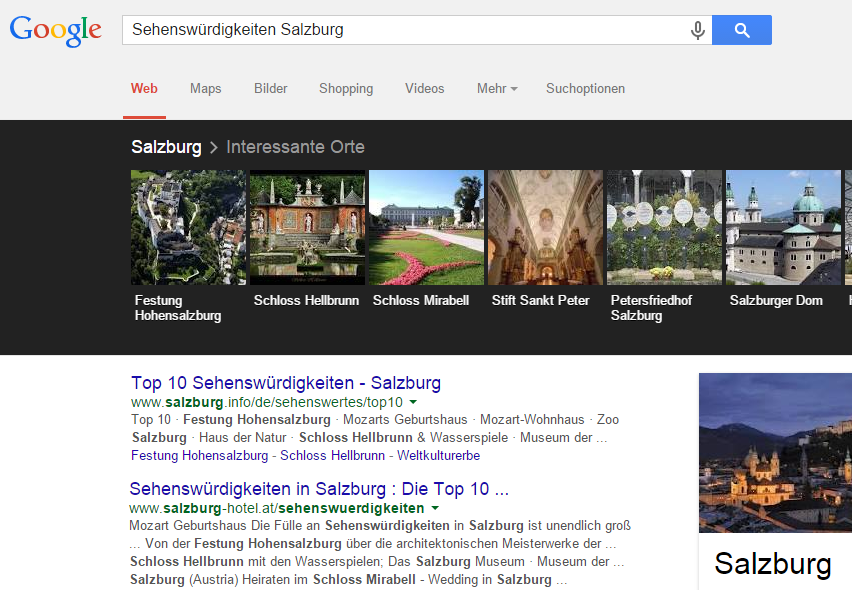
Figure 9: Google Knowledge Graph & Carousel sur "Sites à Salzbourg"
La compréhension sémantique des liens avec l'ancien footballeur Rudi Völler devient encore plus claire. Pour rechercher son surnom "Tante Käthe", le même graphe de connaissances apparaît que pour la recherche "Rudi Völler". Si vous consultez les requêtes de recherche associées, vous trouverez "Tante Käthe Rudi Völler" en haut de la liste. Google apprend avant tout le fait que ces termes ont un point commun.
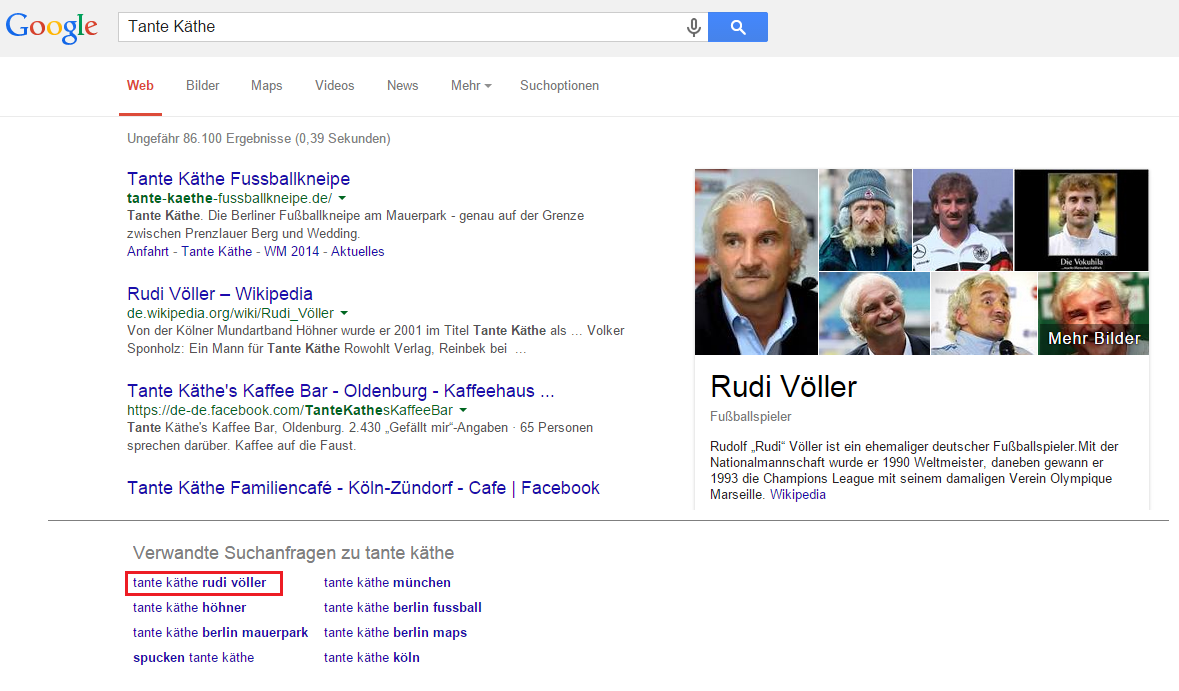
Figure 10: Graphique de connaissances sur Rudi Völler
Il existe plusieurs manières de savoir quelles entités sont liées au sujet de notre site Web:
Le moyen le plus simple consiste à examiner le graphique de connaissances pour obtenir des résultats connexes. D'une part, les entités sous "Sera souvent recherchée" résultent de la fréquence des requêtes de recherche contenant ces deux termes, mais également de l'occurrence courante sur les pages Web d'index des moteurs de recherche.
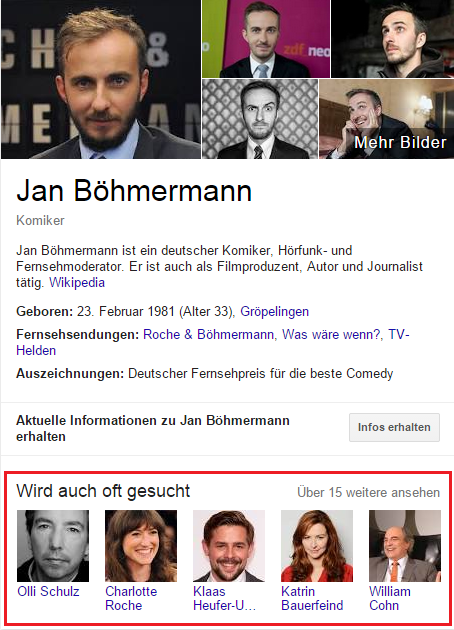
Figure 11: Connaissance graphique sur Jan Böhmermann
Une autre possibilité consiste à examiner l'article Wikipedia du sujet pour rechercher des liens internes vers d'autres articles. D'après mon expérience, dans le texte ci-dessus, les articles liés sont plus proches de l'entité, comme des liens plus bas. En outre, Wikipedia offre un moyen de voir tous les liens internes d’un coup d’œil.

Figure 12: Liens internes d'articles de Wikipedia
Avec RelFinder, ces connexions peuvent être visualisées. Si vous entrez deux entités, vous pouvez voir si les deux sont en relation l'une avec l'autre. Un exemple assez simple est la connexion entre "Steve Jobs" et "NeXT". Ici aussi, les connexions indirectes et moins fortes sont montrées.
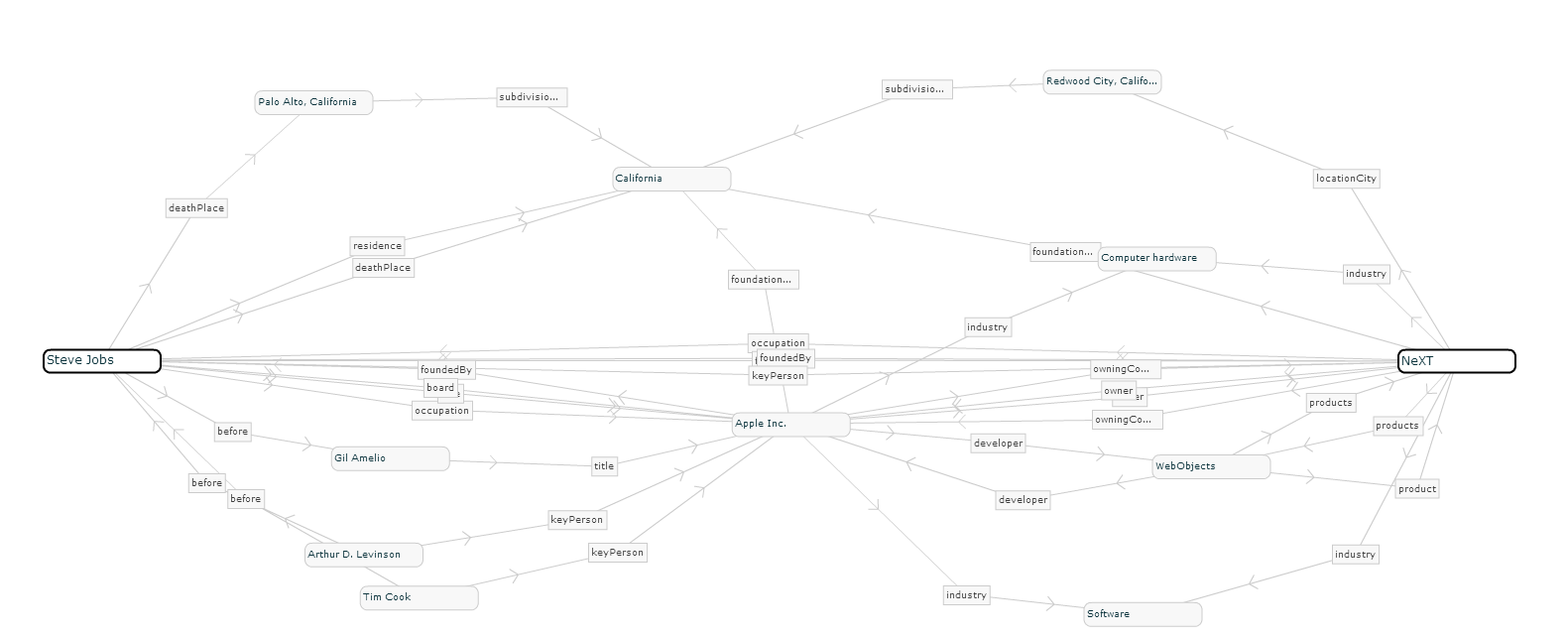
Figure 13: Connexions d'entité avec RelFinder
Comment pouvez-vous construire des entités basées sur ces connexions?
Tout d'abord, il faut comprendre que l'objectif principal dans la création d'entités ne devrait pas être d'obtenir leur propre graphe de connaissances. Comme indiqué ci-dessus, même dans le cas d'un graphe de connaissances, les liens de sites Web dans les SERP sont plus importants. Ainsi, si vous avez recherché les bonnes entités pour votre sujet et les liens entre ces termes, vous pouvez commencer à peaufiner votre page.
Un lien Wikipedia est-il suffisant?
Non. Toute personne qui pense encore que se référer à un article de Wikipedia sur le même sujet promet un ingénieux boost de classement, sinon une place dans le graphe de la connaissance, est une erreur. Après avoir examiné les liens externes de 100 articles Wikipédia, je conclus que seuls les liens Internet officiels de cette entité se classent parmi les meilleurs résultats. Références uniques et références avec seulement 6% à peine.
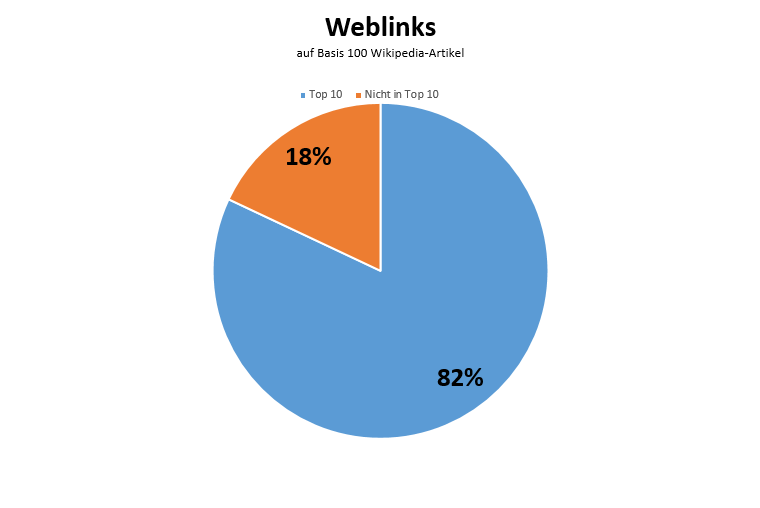
Figure 14: Statistiques: liens Web Wikipedia dans les SERP de Google
Après tout, 82% de toutes les pages Web, qui sont désignées comme liens Web officiels vers le message de Wikipédia, se trouvent dans les SERP sur la première page de cette requête de recherche.
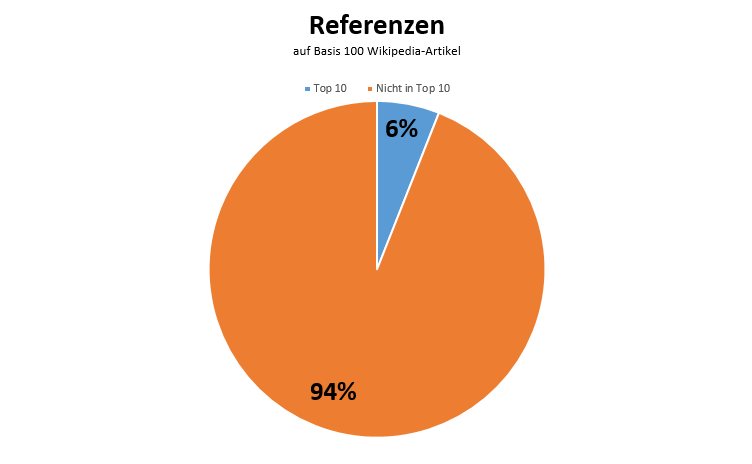
Figure 15: Statistiques: Références Wikipedia dans Google SERPs
94% des sites Web, qui sont liés dans l'article de Wikipédia en tant que référence ou preuve unique, ne figurent pas parmi les 10 meilleurs résultats dans les SERP pour la même requête de recherche. Donc, ils n'aident pas.
À l'aide de l'exemple de Jan Böhmermann, vous trouverez un article dans le top 5 des résultats du Süddeutsche Zeitung Magazin '. Ce qui est spécial à propos de cela, c'est que c'est la première chose qui n'est pas un site officiel du modérateur ou de son émission, aucun article Wikipedia, ni aucun canal social (à part Google News).
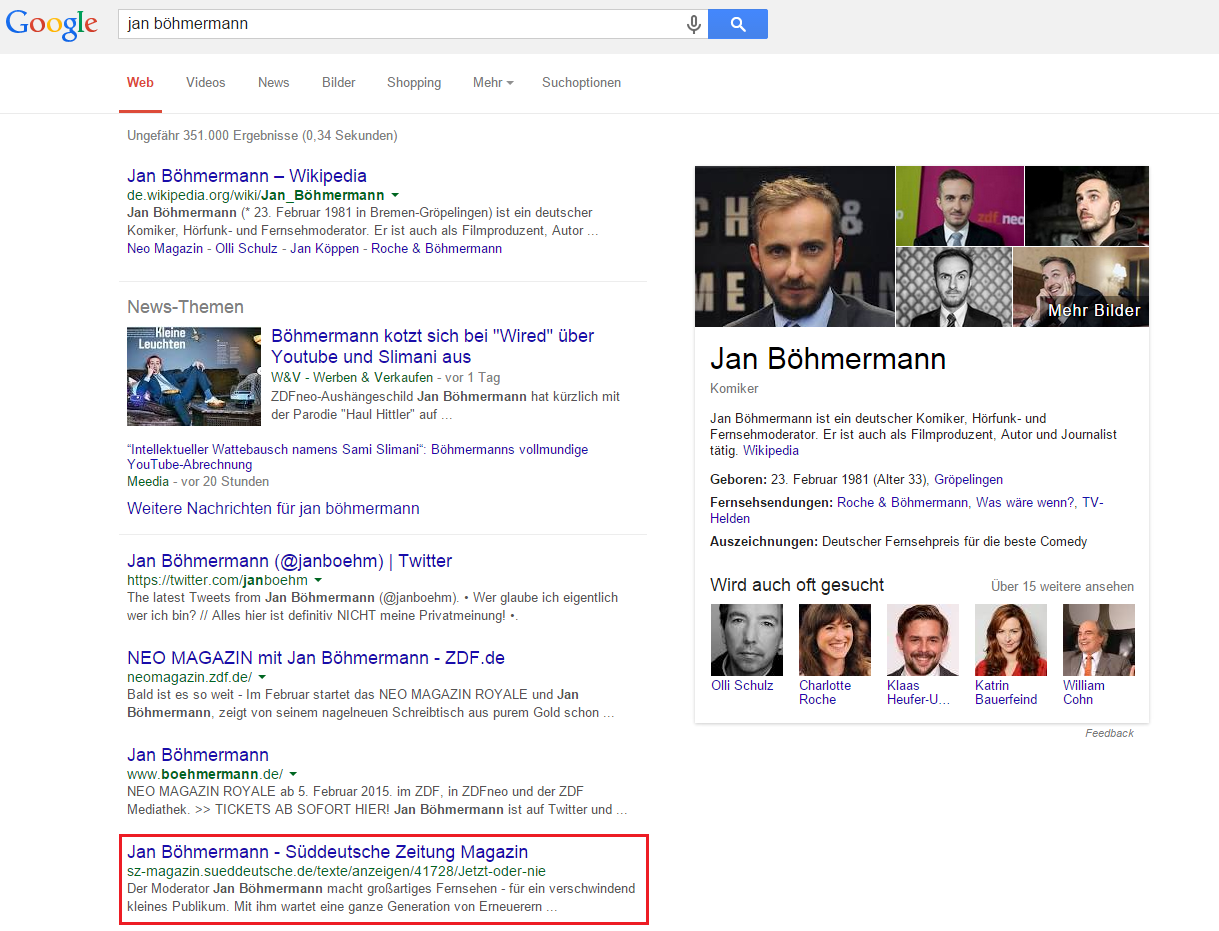
Figure 16: Résultats de la recherche "Jan Böhmermann"
Certes, le poste n'est pas idéal car il se trouve sous le graphique de connaissances. Mais si vous regardez de plus près cet article, vous vous demanderez pourquoi ce résultat fonctionne si bien. En réalité, l'article est composé de deux parties qui ne sont pas liées sauf par un lien. J'ai jeté un œil attentif à la première partie de la photo. J'ai remarqué que le nom de l'entité n'était pas placé dans H1, le texte avec un peu plus de 700 mots n'est pas très long, aucun lien dans le corps du texte n'est positionné … la ligne de fond est l'optimisation de la publication sur OnPage pas à mon avis au dessus de la moyenne. Cependant, il y a déjà plus de 30 autres entités dans ces 700 mots qui sont directement liées à Jan Böhmermann.
Est-ce vraiment le secret?
Certainement pas seul. L’autorité générale et la popularité du site Web jouent un rôle non négligeable. Si vous comparez cet article, mais avec d'autres sites Web classés à la page 1 de "Jan Böhmermann" dans Google, vous remarquerez qu'il n'existe pratiquement aucune autre entité appelée et expliquée liée à la personne.
Il semble donc qu'en raison de la compréhension sémantique du moteur de recherche, la "densité d'entité" joue également un rôle important. Si vous écrivez un article sur "Sights in Munich", vous devez absolument utiliser des entités telles que le jardin anglais, l'Alte Pinakothek, la Hofbräuhaus am Platzl, etc. situées à proximité de l'entité mère.
En plus de l'édition de texte, il est également possible d'utiliser des balises de schéma par entité afin de mettre en évidence des informations et des sujets très importants pour les moteurs de recherche. Les individus ou les entreprises peuvent être amenés à se focaliser avec des structures schématiques afin de renforcer la compréhension du moteur de recherche.
Enfin: 3 plats à emporter
- Le graphique de connaissances n'est pas quelque chose que les propriétaires de sites Web devraient avoir peur. Apprenez à l'utiliser à vos fins. Ce ne doit pas toujours être Wikipedia!
- Enrichissez vos articles et sujets avec des entités associées et montrez à Google & Co. que vous avez rassemblé et décrit toutes les informations pertinentes.
- La construction de liens seule dans Wikipedia ne va pas aider. Continuez à créer des liens avec des autorités de confiance et recherchez les connexions appropriées entre les entités.