
Sommaire
Quiconque créera un site Web rencontrera tôt ou tard le terme "robots.txt". Ce fichier texte indique aux crawlers des moteurs de recherche quelles zones d’un domaine doivent être explorées et lesquelles ne le doivent pas.
Fondamentalement, la création et l’emplacement d’un fichier robots.txt n’est pas sournois, car votre répertoire Web est structuré de manière logique. Dans cet article, nous vous montrons comment créer un fichier robots.txt et ce que vous devriez garder à l'esprit.
Le fichier robots.txt est un petit fichier texte facile à créer à l’aide d’un éditeur de texte et à télécharger à la racine d’une page Web. La plupart des robots Web s'en tiennent à cela Robots Exclusion de protocole standard, Cela spécifie que les robots des moteurs de recherche (également: agent utilisateur) recherchent d'abord dans le répertoire racine un fichier appelé robots.txt et lisent les spécifications contenues avant de commencer l'indexation. Les webmasters créent un fichier robots.txt pour mieux contrôler les zones de votre site que les bots peuvent et ne doivent pas être explorés par les bots.
Dans le fichier robots.txt, vous définissez des instructions pour les agents d'utilisateur de Google. Cela peut être des navigateurs, mais aussi des robots (araignées, robots) d'un moteur de recherche. Les agents utilisateurs les plus courants sont Googlebot, Googlebot Image (Google Image Search), Adsbot Google (Google AdWords), Slurp (Yahoo) et bingbot (Bing).
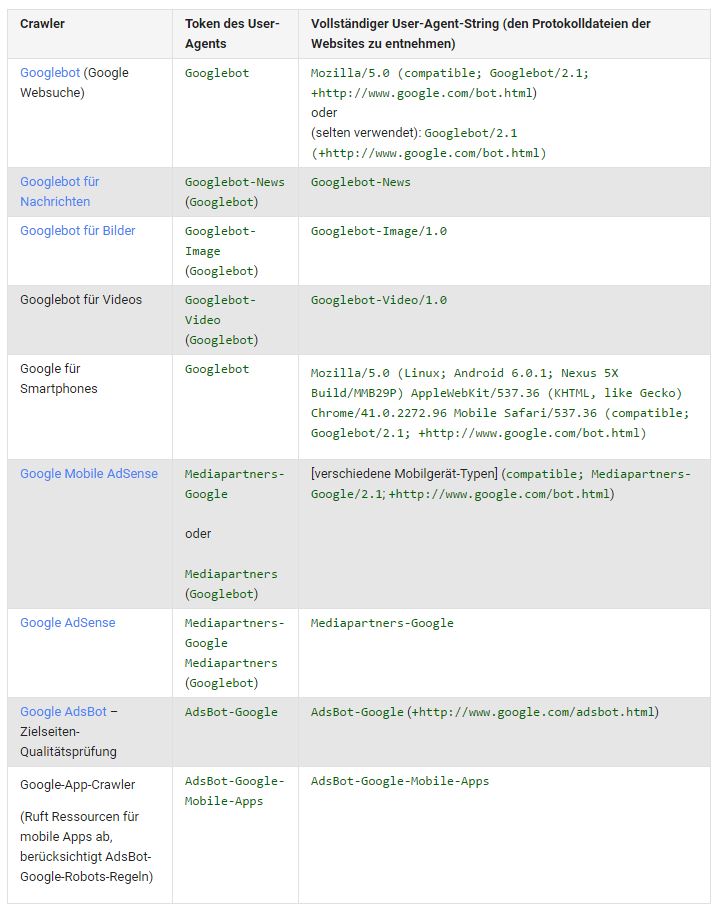
Figure 1: Google User Agents
Construire un fichier robots.txt
Les entrées dans le fichier robots.txt ont deux parties. Dans l'exemple suivant, ils se trouvent sur deux lignes, mais ils peuvent en comporter plusieurs, en fonction du nombre de commandes et d'agents utilisateur. Dans la partie supérieure, vous parlez à l'agent utilisateur par son nom. Ci-dessous, vous lui demandez un acte.
Par exemple, la commande suivante indique à Googlebot de ne pas analyser uniquement le répertoire / cms /:
Agent utilisateur: Googlebot
Interdit: / cms /
Si l'instruction doit s'appliquer à tous les robots d'exploration, il faut lire:
Agent utilisateur: *
Interdit: / cms /
Si vous voulez vous assurer que non seulement les sections individuelles de votre site Web doivent être ignorées, mais l'ensemble du site Web, il suffit de placer une barre oblique:
Agent utilisateur: *
Interdit: /
S'il s'agit simplement d'une sous-page spéciale ou d'une image à exclure (dans ce cas, exemple de fichier ou exemple d'image), entrez:
Agent utilisateur: Googlebot
Interdit: /example_file.html
Interdit: /images/sample_image.jpg
Si toutes les images de votre site Web sont de nature privée et doivent être exclues, vous pouvez utiliser le signe dollar: Le caractère $ sert de paramètre de substitution pour une règle de filtrage qui atteint la fin d'une chaîne. Le robot n’indexe pas le contenu qui se termine par cette chaîne. Tous les fichiers jpg peuvent être exclus comme suit:
Agent utilisateur: *
Disallow: /*.jpg
Il existe également une solution si un répertoire doit être verrouillé mais qu'un sous-répertoire doit être libéré pour l'indexation. Ajoutez ensuite les lignes suivantes au code:
Agent utilisateur: *
Interdit: / boutique /
Autoriser: / shop / magazine /
Si vous souhaitez exclure les annonces AdWords de l'index organique, vous pouvez spécifier une exception dans votre code.
Agent utilisateur: Mediapartners-Google
Autoriser: /
Agent utilisateur: *
Interdit: /
allusionRemarque: le fichier robots.txt doit également faire référence au plan Sitemap pour indiquer aux robots d'exploration la structure d'URL d'une page Web. Cette référence peut ressembler à ceci:
Agent utilisateur: *
Disallow:
Plan du site: http: // (www.mysite.com) /sitemap.xml
Utiliser le fichier robots.txt avec des caractères génériques
Le protocole standard Robots Exclusion n'autorise pas les expressions régulières (caractères génériques) au sens strict. Cependant, il reconnaît deux caractères génériques pour le chemin:
Les caractères * et $.
Ils sont utilisés avec la directive Disallow pour exclure des sites Web entiers ou des fichiers et répertoires individuels.
Le caractère * est un espace réservé pour les chaînes qui suivent ce caractère. S'ils prennent en charge la syntaxe des caractères génériques, les robots n'indexeront pas les pages Web contenant cette chaîne. Pour l'agent utilisateur, cela signifie que la directive s'applique à tous les robots, même sans spécifier de chaîne.
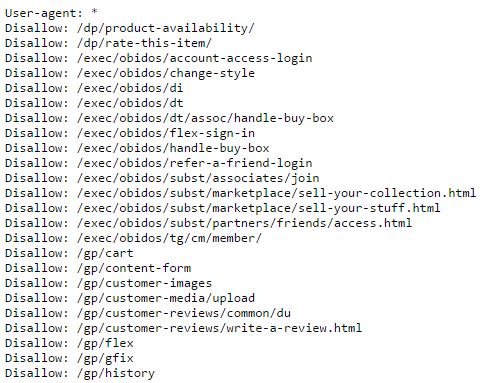
Figure 2: Extrait du fichier robots.txt d'Amazon
allusion: Si les caractères génériques et la programmation sont un nouveau territoire pour vous et que tout vous semble trop compliqué, utilisez simplement le générateur robots.txt de SEO Expertise pour créer votre fichier robots.txt.
Il existe des conditions obligatoires pour le fonctionnement correct d'un fichier robots.txt. Avant de mettre le fichier en ligne, assurez-vous que les règles de base suivantes sont respectées:
- Le fichier robots.txt se trouve au niveau supérieur du répertoire. L'URL du fichier robots.txt de http://www.beispieldomain.de devrait être: http://www.beispieldomain.de/robots.txt
- La fin d'une extension de fichier est marquée avec le signe dollar ($).
- Par défaut, le fichier est défini sur "autoriser". Si vous souhaitez bloquer des zones, vous devez les marquer avec "interdire".
- Les instructions sont sensibles à la casse, ce qui signifie qu'elles sont sensibles à la casse.
- Il y a une ligne vide entre plusieurs règles.
Testez le fichier robots.txt
Avec le très pratique SEO Expertise robots.txt Testing Tool, vous pouvez vérifier en quelques étapes si votre site Web contient un fichier robots.txt. Vous pouvez également travailler directement dans la console de recherche Google. Dans le menu principal de la page d'accueil, vous trouverez le sous-élément robots.txt-Tester dans la section "Exploration".
Si quelqu'un d'autre a créé votre répertoire Web et que vous n'êtes pas sûr d'avoir un fichier robots.txt, vous le verrez dans le testeur après avoir entré votre URL. Si "Le fichier robots.txt est introuvable (404)" apparaît ici, vous devez d'abord l'envoyer à Google si vous souhaitez ignorer certaines parties de la page du robot d'exploration Web.

Figure 3: La page Web ne contient pas de fichier robots.txt
1. Envoyez le fichier robots.txt à Google.
Si vous cliquez sur "Envoyer" en bas à droite de l'éditeur robots.txt, une boîte de dialogue s'ouvre. Téléchargez ici le code robots.txt modifié à partir de la page des testeurs en sélectionnant "Télécharger".
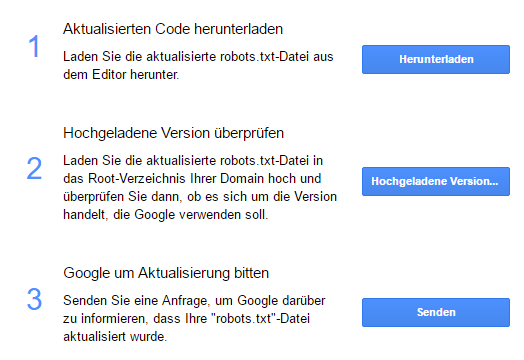
Figure 4: Téléchargez et mettez à jour le fichier robots.txt
Vous devez télécharger le nouveau fichier robots.txt dans votre répertoire racine, puis cliquer sur le bouton "Afficher le fichier robots.txt" pour voir si le fichier est analysé par Google. Vous dites donc simultanément à Google que le fichier robots.txt a été modifié et doit maintenant être exploré.
2. Correction d'une erreur robots.txt
Si le fichier robots.txt existe déjà, faites défiler le code pour voir s'il existe des avertissements de syntaxe ou des erreurs logiques.
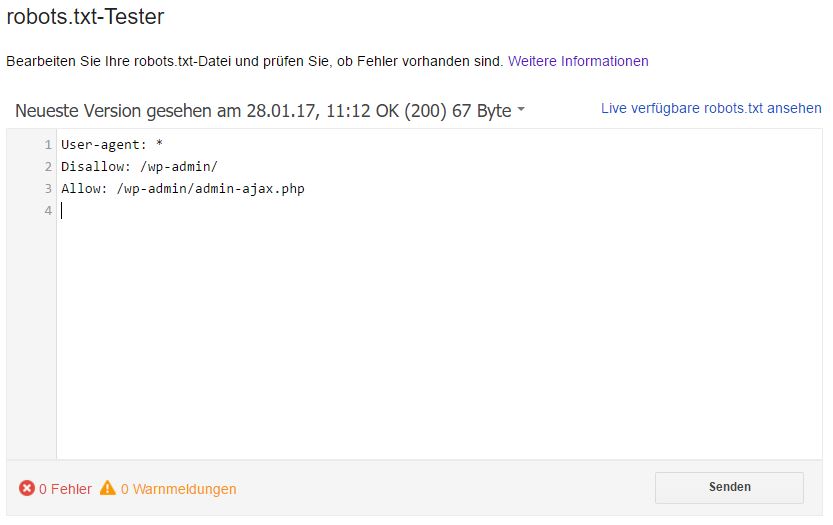
Figure 5: Exemple de fichier robots.txt
Sous le testeur, vous verrez une zone de texte dans laquelle vous entrez l'URL d'une page de votre site Web et cliquez sur "Test".
En outre, dans la liste déroulante située à droite de ce champ, vous pouvez sélectionner l'agent utilisateur que vous souhaitez simuler. Par défaut, le menu est sur "Googlebot".

Figure 6: Les agents utilisateurs de Google
Si le terme "Approuvé" est affiché après le test, la page peut être indexée. Toutefois, si le résultat du test est bloqué, l’URL saisie pour les robots d’analyse Web sera bloquée par Google.
Si le résultat ne correspond pas à vos besoins, corrigez les erreurs dans le fichier et relancez le test. Éditez toujours le fichier robots.txt sur votre site Web, car le testeur n'autorise pas les modifications.
La surveillance robots.txt de SEO Expertise
Pour les grandes entreprises comme pour les petits propriétaires de sites Web, il est important de toujours vérifier que le fichier robots.txt est accessible à tout moment et que leur contenu a changé. Ceci est possible avec la surveillance du fichier robots.txt de robte. Le rapport est dans le module Succès du site à trouver.
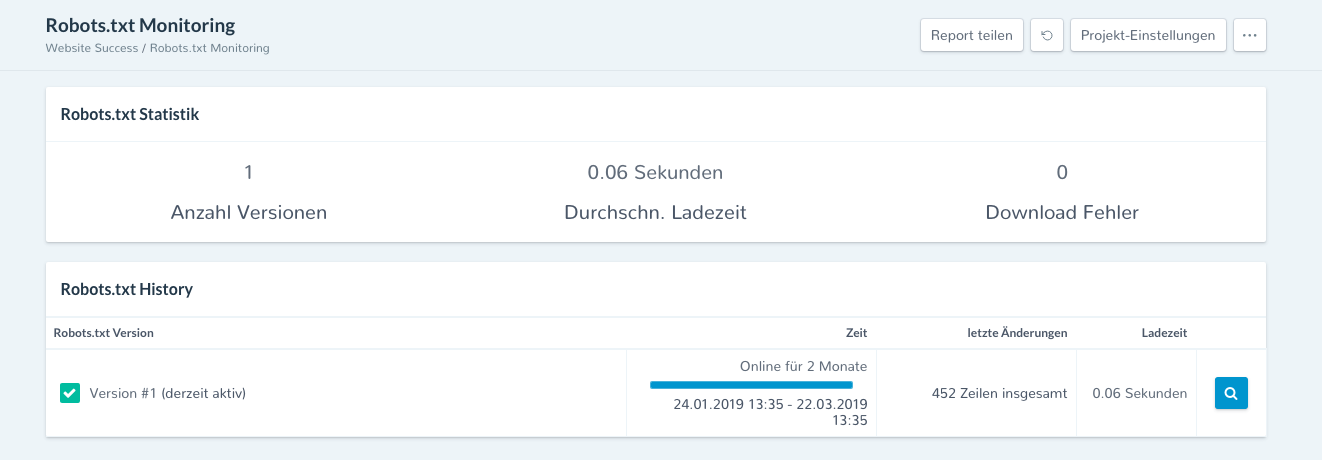
Figure 7: La surveillance robots.txt de SEO Expertise
Le fichier robots.txt du site Web est interrogé par SEO Expertise toutes les heures. Il vérifie si ceci est accessible (statut 200) et si le contenu du fichier a changé par rapport à la requête précédente. Faites également attention au temps de chargement du fichier et aux écarts tels que. Les délais d'attente enregistrés.
dans le Succès du site répertorie toutes les versions trouvées du fichier robots.txt, y compris leur temps de chargement moyen et les erreurs de téléchargement. Si vous souhaitez examiner de plus près une version, vous pouvez commencer la vue détaillée en cliquant sur la loupe située sur le bord droit de l'image.
conclusion
Une programmation et un positionnement corrects du fichier robots.txt sont très importants pour l’optimisation de votre moteur de recherche technique. Même les plus petites erreurs de syntaxe peuvent amener l'agent utilisateur à agir différemment que prévu. Les pages que vous vouliez exclure sont ensuite explorées ou inversement.
Réfléchissez bien si vous souhaitez vraiment exclure des pages via le fichier robots.txt. Vos instructions sont destinées aux robots d'exploration uniquement, car elles peuvent ne pas être suivies comme prévu. En outre, le fichier robots.txt peut être mal interprété par certains robots qui spécifient une syntaxe spécifique. Vérifiez régulièrement les conseils ci-dessus et vérifiez si le fichier est toujours accessible.