
Sommaire
Un des sujets qui fait l’objet d’une attention accrue dans le référencement depuis quelques mois est la question de savoir comment utiliser la directive noindex dans le fichier robots.txt. Ce qui, pour de nombreux SEO, est plutôt un conseil d’initié pour le crawl et le contrôle d’index sera bientôt une chose du passé.
Dans son blog Webmaster Central, Google a annoncé le 2 juillet 2019 qu’il ne compterait plus sur Noindex dans le fichier robots.txt de septembre.
Sur la base de ce message, certains sites ont déjà commencé à nettoyer leur fichier robots.txt et à supprimer les index noindex. Cependant, comme le montre un cas, la suppression prématurée du noindex dans le fichier robots.txt peut avoir des conséquences directes. Au contraire, sur la base de ces résultats, il convient de se demander s'il est judicieux que Google renonce à cette solution à l'avenir.
Les avantages de Noindex dans le fichier robots.txt
Sur la scène du référencement, il y a certainement eu des opinions et des expériences différentes concernant cette déclaration de robots.txt au fil des ans. Si certains ont répondu à la solution proposée par Matt Cutts en 2008, les autres étaient plutôt sceptiques quant à l'utilité réelle de cette directive.
En principe, l'instruction noindex dans le fichier robots.txt (à ne pas confondre avec la balise robots dans l'en-tête HTML (Meta Robots) ou les en-têtes de réponse HTTP (x robots)) fonctionne de manière presque analogue à la directive Disallow, avec l'extension uniquement. no noex peut mieux empêcher les URL verrouillées à l'analyse d'entrer dans l'index de Google. En principe, on pourrait penser qu’il est impossible d’indexer une page non explorée. Toutefois, à la fois la pratique de ces dernières années et, en fin de compte, la documentation de Google prouvent qu’une interdiction ne peut empêcher l’indexation des URL. Le fond: Pour pouvoir explorer une adresse, celle-ci doit être connue. Cela nécessite des références à partir d'une adresse connue. En conséquence, il existe des données sur une URL avant son appel (pour la première fois).

Figure 1: Résultat de recherche Google exemplaire sans informations sur la page en raison d'un verrou robots.txt
Ceux qui ont déjà travaillé avec la spécification Noindex dans robots.txt ont eu l'expérience de parler de cela empêcher l'indexation indésirable peut. En partie, il a été appris que cette directive avait déjà supprimé les URL indexées de l'index du moteur de recherche. Mais vous ne pouvez pas planifier cela en toute sécurité.
Pourquoi les alternatives proposées par Google ne sont pas des options
Néanmoins, le Noindex dans le fichier robots.txt était l’un des plus efficaces à ce jour. QuickWinOptions permettant d'optimiser simultanément l'analyse et l'indexation de sites pour des cas d'utilisation spécifiques. Certes, la clé du contrôle optimal de l’exploration et de l’indexation est plus un mise en œuvre technique propredans lequel je, par exemple, n'ancrez aucun signal d'URL vers des pages non pertinentes dans mon code source, mais l'expérience a montré qu'il est rarement possible pour un projet de site d'atteindre rapidement l'état souhaité.
Il est donc d'autant plus regrettable que Google nous retire de septembre la directive "no index" du fichier robots.txt. Fait intéressant, c’est encore une fois les alternatives proposées par Google:
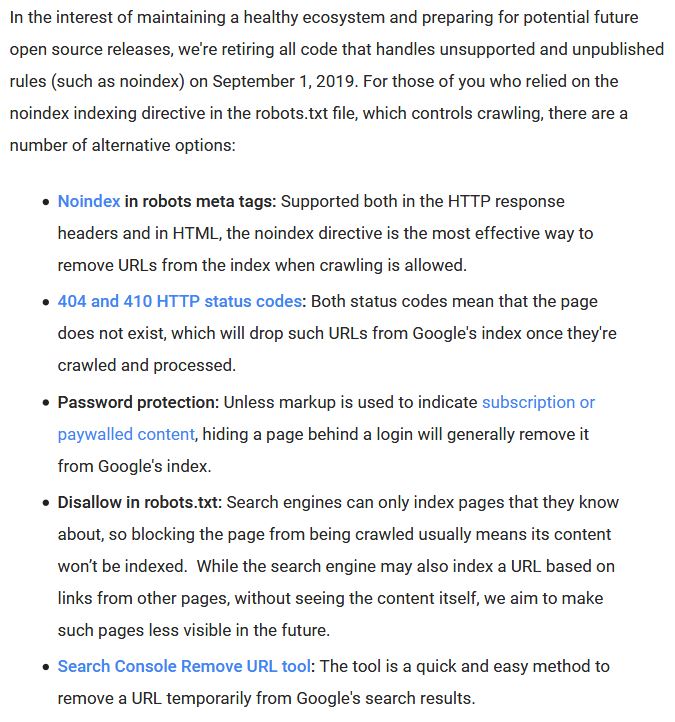
Figure 2: Alternatives à Noindex dans le fichier robots.txt, selon Google
À mon avis, les options ci-dessus spécifiées par Google dans son blog Webmaster Central sont largement déraisonnables ou au moins une fois très malchanceuses:
- Balise Meta-Robots "noindex": Cela garantit que les URL ne pénètrent pas dans l'index Google ni n'en sortent, mais elles peuvent quand même être explorées et, dans le pire des cas, avoir un impact négatif sur le budget de l'analyse. En ce sens, cette option est hors de question pour de nombreuses applications.
- Code de statut HTTP 404 ou 410: Si une URL devait cesser d'exister, l'utilisation d'un code de statut HTTP 404 ou supérieur à 410 est certainement une option. Néanmoins, il est douteux d'introduire un code d'erreur comme alternative à Noindex dans le fichier robots.txt.
- Protection par mot de passe: Encore une fois, cette recommandation ne correspond pas à 99% des cas. Certes, la configuration la plus optimale pour l’indexation d’un système intermédiaire est la protection par mot de passe. Néanmoins, il est plutôt douteux d’appeler cela une alternative sans donner d’exemple. D'autant plus que les zones sont désormais protégées par un mot de passe, auparavant accessible aux utilisateurs sans mot de passe et verrouillé uniquement pour les robots d'exploration.
- fonction de suppression URL: Cette fonctionnalité de la console de recherche Google est un excellent outil pour supprimer rapidement les URL de l'index. Comme le montre l'article de mon blog d'il y a quelques semaines sur le sujet, l'outil devra être encore développé pour que les URL non souhaités puissent être bannis des résultats de la recherche.
- Interdire dans le fichier robots.txt: Comme décrit ci-dessus, l'indication d'interdiction actuelle n'empêche pas l'indexation des URL de manière satisfaisante. On peut seulement espérer que Google améliore sa déclaration de révocation avec sa déclaration "nous visons à rendre les pages de recherche moins visibles à l'avenir".
Quelle conséquence a eu le changement de vision de Google sur Noindex dans le fichier robots.txt
Bien que vous ne soyez peut-être pas satisfait des alternatives existantes, en tant que propriétaire de site Web, vous devez être prêt dans les prochaines semaines à adapter votre fichier robots.txt et à vous dispenser de la spécification Noindex. Ceci est particulièrement important car la non-interprétation des informations dans le fichier robots.txt peut également être la cause de tous les problèmes. ignoré les autres directives du robot peut être (voir aussi le commentaire de Tobias Schwarz ici). Si cela s'applique également à Google, est inconnu.
Compte tenu de l'ordre des instructions du fichier robots.txt, i. Tout d'abord interdire, puis autoriser et uniquement à la fin, par exemple, un Noindex, vous pouvez également envisager de maintenir le statu quo actuel, si vous utilisez d'autres robots d'exploration de moteurs de recherche, s'ils fonctionnent avec Noindex dans le fichier robots.txt, poursuivez cette directive. mitzugeben. Quoi qu’il en soit, il est certainement recommandé de mettre en place une surveillance correspondante afin de suivre les modifications apportées à l’exploration et à l’indexation à partir du 1er septembre.
Quel retrait précoce de Noindex dans le fichier robots.txt peut provoquer
La question cruciale qui se posait jusque-là: que se passera-t-il si vous supprimez déjà les directives Noindex dans le fichier robots.txt et que vous vous fiez uniquement à Disallow? Pour l'un de nos clients, le fichier robots.txt a déjà été ajusté une semaine après la publication du message par Google, à savoir E. Les instructions Noindex ont été supprimées du fichier robots.txt et seules les entrées en double non autorisées précédemment existantes sont conservées. Ce qui est arrivé un jour après (!) Était assez surprenant à nos yeux.
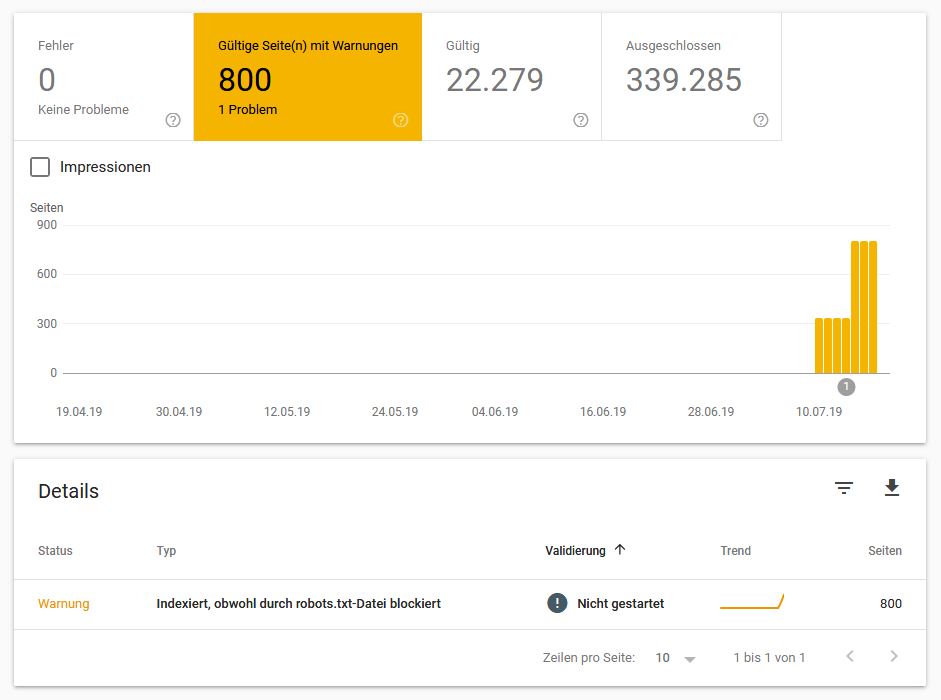
Figure 3: Problèmes de couverture dans la console de recherche Google après la suppression du noindex dans le fichier robots.txt
Relativement peu de temps après la modification du fichier robots.txt, Google a déjà commencé à utiliser la spécification Noindex inclure des URL bloquées dans l'index, La directive interdire restante bloque toujours ces URL de l'analyse. Toutefois, cela ne suffit pas pour empêcher l’indexation dans Google. Avec l'aide de cette affaire, nous avons réalisé une fois de plus l'efficacité de Noindex dans le fichier robots.txt!
En aucun cas jusqu'à présent, cela est devenu aussi clair qu'ici (nous ne pouvons malheureusement pas appeler le nom du client avec plus de détails ici). En ce sens, il est d'autant plus regrettable que vous ne puissiez plus y travailler à partir de septembre. Le seul espoir est que Google transfère les avantages de Noindex dans le fichier robots.txt à la spécification Disallow dans le futur.
conclusion
Comme nous l'avons appris du cas présenté, une correction trop précoce de robots.txt aux directives Noindex encore existantes n'est pas recommandée. Dans le pire des cas, il peut arriver que, comme d'habitude pour l'indication interdire, les URL bloquées soient indexées.
Même si nous ne savons pas quels changements nous parviendront à partir du 1er septembre 2019, en raison des changements chez Google, il faut s'attendre, compte tenu de l'état actuel, à adapter votre fichier robots.txt aussi près que possible de la date de septembre. Il est également recommandé de surveiller les URL verrouillées dans le fichier robots.txt.
En outre, la solution permettant d'optimiser l'équilibre entre l'analyse et l'indexation reste une implémentation techniquement propre au niveau du site Web. Le problème avec l'exemple présenté ici est qu'il y a beaucoup de signaux dans le code source qui poussent GoogleBot à explorer ou indexer lesdites URL. Cela ne signifie pas nécessairement href ou des liens de formulaire.
Les analyses de fichier journal ont montré que même les extraits d'URL dans les scripts, les commentaires ou les attributs HTML auto-définis peuvent amener Google à accéder à ces modèles d'URL. Cela montre encore une fois que le référencement nécessite une programmation propre et que vous ne devez pas vous fier uniquement au fichier robots.txt comme moyen de contrôle de l’exploration. Pour être positionné techniquement de manière optimale, des mesures telles que le masquage de lien, le modèle PRG et le protocole Co. sont encore nécessaires.
En ce sens: codage heureux!