
Sommaire
Tous les webmasters connaissent le problème: tous les domaines du site Web ne doivent pas nécessairement être explorés par les moteurs de recherche. A l'aide du fichier robots.txt, vous avez la possibilité de le spécifier séparément.
En plus de travailler avec ce fichier, nous vous montrerons les erreurs les plus courantes que vous pouvez commettre lors de la création d'un fichier robots.txt et la meilleure façon de les éviter.
Il existe diverses raisons pour lesquelles les webmasters choisissent d’exclure l’indexation de certains répertoires et pages par les moteurs de recherche (zones de connexion ou fichiers archivés, par exemple). Pour ce faire, le "Protocole standard d’exclusion de robots" a été publié en 1994. Ce protocole détermine que les robots du moteur de recherche doivent d'abord rechercher le fichier robots.txt dans le répertoire racine et lire les informations qu'il contient. Ce n'est qu'alors que les robots d'exploration (également appelés agents utilisateurs) peuvent commencer l'analyse.
En rapport avec l'utilisation du fichier robots.txt, des erreurs peuvent souvent survenir, par exemple si la syntaxe d'une instruction est incorrecte ou si un répertoire est bloqué par inadvertance. Ces erreurs courantes peuvent survenir lors de l'utilisation de robots.txt:
Bug n ° 1 – Utilisation d'une syntaxe incorrecte
Le fichier robots.txt est un simple fichier texte qui peut être facilement créé à l’aide d’un éditeur de texte. Une entrée dans le fichier robots.txt est toujours composée de deux parties: vous spécifiez tout d'abord pour quel agent utilisateur l'instruction suivante doit s'appliquer (par exemple, Googlebot), puis vous pouvez, par exemple, Utilisez la commande Interdire pour répertorier toutes les pages qui ne doivent pas être explorées. Pour que les instructions du fichier robots.txt fonctionnent réellement, vous devez utiliser une syntaxe correcte, comme dans l'exemple suivant.
Agent utilisateur: Googlebot
Interdit: / exemple_directory /
Dans ce cas, l'explorateur Web de Google doit exclure le répertoire / rép_exemple / crawl. Si cette instruction doit s'appliquer à tous les robots, vous pouvez écrire les informations suivantes dans votre fichier robots.txt:
Agent utilisateur: *
Interdit: / exemple_directory /
L'étoile (également appelée caractère générique) est considérée comme une variable pour tous les robots d'exploration. L'effet opposé est l'utilisation d'une seule barre oblique (/), ici tout le site Web est exclu de l'indexation (par exemple, lors d'un essai avant une relance).
Agent utilisateur: *
Interdit: /
Bug n ° 2 – Bloquez des répertoires au lieu de répertoires ("/" oubliés)
Si un répertoire doit être verrouillé, vous devez absolument penser à la barre oblique à la fin du nom du répertoire.
Interdit: / répertoire Par exemple, non seulement / directory /, mais aussi / directory-one.html lock
Si vous souhaitez exclure plusieurs pages de l'indexation, vous devez créer une ligne distincte pour chaque répertoire, car la spécification de plusieurs chemins d'accès sur une ligne entraîne des erreurs non désirées.
Agent utilisateur: googlebot
Interdit: / exemple-repertoire /
Interdit: / exemple-repertoire-2 /
Interdit: /example-file.html
Bug n ° 3 – Blocage involontaire de répertoires
Avant que le fichier robots.txt ne soit chargé dans le répertoire racine de la page Web, vous devez toujours vérifier l'exactitude de la syntaxe du fichier. Même les plus petites erreurs pourraient amener le robot à ignorer les informations et à explorer les pages qui ne devraient pas être incluses ultérieurement dans l'index. Assurez-vous que les répertoires indexés ne sont pas derrière la commande Disallow: debout.
De même, dans le cas où la structure de page de votre page serait modifiée à la suite d'un relancement, par exemple, vous devez rechercher des erreurs dans le fichier robots.txt. Vous pouvez facilement le faire avec l'outil de test gratuit de SEO Expertise.
Bug n ° 4 – Ne mettez pas le fichier robots.txt dans le répertoire racine
L'erreur la plus commune avec le fichier robots.txt n'est pas de le placer dans le répertoire racine de la page Web. Comme les agents d'utilisateurs ne recherchent généralement que le fichier robots.txt dans le répertoire racine, les sous-répertoires sont ignorés.
L'URL correcte pour un fichier robots.txt devrait être:
http://www.deine-webseite.org/robots.txt
Bug n ° 5 – Interdit aux pages avec une redirection
Si le fichier robots.txt bloque les pages redirigées vers une autre page, le robot pourrait ne pas reconnaître la redirection. Dans le pire des cas, la page avec une URL incorrecte peut continuer à apparaître dans les résultats de la recherche. Les données Google Analytics de votre projet peuvent également être falsifiées.
Avec l'aide de surveillance robots.txt chez SEO Expertise vous ne pouvez pas faire de telles erreurs. Sous la rubrique "Surveillance" -> "Robots.txt Surveillance", votre fichier robots.txt est vérifié toutes les heures pour en vérifier la disponibilité (statut 200). Si ce n'est pas le cas, vous recevrez un e-mail vous informant que votre fichier robots.txt n'est actuellement pas disponible.
Même si votre fichier robots.txt renvoie le statut 200 (accessible), SEO Expertise vérifiera toujours si votre fichier robots.txt a été modifié. Si un écart se produit, l'outil répertorie le nombre exact de modifications. S'il y a plus de 5 modifications, vous recevrez un e-mail vous demandant de consulter le fichier robots.txt et de voir si ces modifications sont intentionnelles ou s'il y a une erreur.
Astuce: Robots.txt vs. noindex
Il est important de savoir qu'une exclusion dans le fichier robots.txt ne signifie pas automatiquement que la page ne peut pas être indexée. Le fichier robots.txt permet uniquement le contrôle de l'agent utilisateur. Néanmoins, les moteurs de recherche peuvent inclure des fichiers ou des répertoires dans l'index, par exemple, dès qu'une URL exclue via le fichier robots.txt est liée à une page externe analysable. Cependant, comme il empêche le bot d'analyser, l'un des messages d'erreur suivants est généralement affiché à la place de la méta-description:
- "En raison du fichier robots.txt de ce site, aucune description n'est disponible pour ce résultat."
- "Le fichier robots.txt de ce site ne permet pas d'afficher une description du résultat de la recherche."
- "La description de ce résultat n'est pas disponible en raison du fichier robots.txt de ce site"
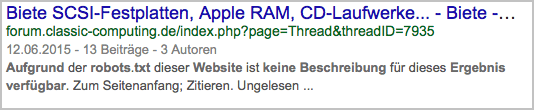
Figure 2: Par exemple, nips une page qui est exclue par le fichier robots.txt mais toujours indexée.

Figure 3: Version anglaise du message d'erreur robots.txt dès qu'une page est bloquée.
Un simple lien vers la page concernée suffit pour inclure cette URL dans l'index, même si "Disallow" a été défini dans le fichier robots.txt. Aussi le réglage de la
Donc, si vous voulez vous assurer que certaines URL ne finissent pas dans l'index Google, vous devez utiliser le