
Sommaire
De nombreux sites Web ressemblent à une jungle d'URL. Cela coûte souvent des classements et du trafic. On peut l’empêcher, si l’on identifie l’extension d’URL de son site Web, les URL inutiles et les supprime.
Les classements les plus élevés, le meilleur contenu, les liens les plus forts – le référencement consiste principalement à générer plus de trafic et à générer plus de trafic. De nombreux sites Web ressemblent maintenant davantage à une URL de jungle qu’à un jardin alloué bien entretenu. Bien que Tante Google n'ait pas de problème avec un peu de chaos, elle préfère aimer les sites Web qui se prennent en charge.
Comment générer plus de trafic avec moins d'URL? Nous voulons nous consacrer à cette question aujourd'hui.
La vision – quels sont les avantages d’un site Web allégé?
Au début, "plus de trafic avec moins d'URL" semble contre-intuitif. Si mon site Web contient moins d'URL, il risque de se classer sur moins de sujets (certains disent encore "mots clés"), et si chaque URL d'un site Web contenait le meilleur contenu sur un sujet différent, ce serait la bonne chose à faire. pas si, plus précisément: jamais.
Il y a beaucoup de choses qui parlent pour moins d'URL. Ainsi, la qualité globale d'un site Web a un impact sur sa capacité de classement. Autrement dit: peu d'URL avec du contenu exclusivement cool battent de nombreuses URL avec des bons, des médiocres et des mauvais.
Moins d'URL ont aussi beaucoup plus d'avantages. Pour n'en nommer que quelques-uns:
- Moins de sources d'erreur pour le contenu en double, la gestion de l'indexation, l'internationalisation, etc.
- Concentration accrue du pagerank et des signaux utilisateur sur les URL importantes
- Plus de temps pour les URL importantes de votre site Web
- Le robot de recherche a plus de temps et est moins distrait (budget d'analyse des mots clés)
- Plus de vue d'ensemble avec moins d'effort administratif
- Relancer avec 10 000 URL au lieu de 1 000 000? L'admin t'embrasse les pieds et tu sauves une semaine de nerfs et de salaire
Épinglez la page Web – qu'y a-t-il, que doit-il aller?
Jusqu'à présent, la visite de votre site Web ressemble à une expédition en canot à pédale dans un affluent inexploré de l'Amazone? Pour éviter cela à l'avenir, nous souhaitons obtenir un aperçu de la totalité de la portée des URL du ou des sites Web lors de la première étape, puis éliminer les erreurs flagrantes. L’objectif est de ne pouvoir accéder en ligne qu’une seule version du site Web. Appelons-la:
https://www.meinewebsite.de
Quelles sont les sources de doublons de sites Web?
- Protocoles en double: l'appel du site Web depuis http://meinewebsite.de est-il correctement transféré (via 301) vers https://mywebsite.de ou inversement?
- Préfixe en double: le site Web www.mywebsite.de est-il correctement redirigé (via 301) vers mywebsite.de ou inversement?
- Sous-domaine et sous-dossier: Existe-t-il des sous-domaines ou sous-dossiers pouvant accéder à des versions supplémentaires du site Web?
- Domaines: existe-t-il des domaines supplémentaires que vous transmettez correctement (via 301) au domaine de site Web actuel (www.auchmeinewebsite.de sur www.meinewebsite.de)?
Comment trouver des doublons de sites Web?
Accès par serveur
Vous devez d’abord avoir accès au serveur hébergeant le site Web. Cela vous permet de contrôler quels dossiers ont été créés sur le serveur et comment ils sont liés au dossier du site Web.
Idéalement, vous avez également accès à l'interface d'hébergement de site Web associée. Ici, vous contrôlez quels domaines et sous-domaines le site Web est réalisable et si, pour toutes les autres possibilités en plus de notre https://www.meinewebsite.de, les 301 correspondances correctes sont activées. N'oubliez pas de vérifier les paramètres du protocole (HTTP ou HTTPS) et du préfixe (www ou non) par domaine / sous-domaine.
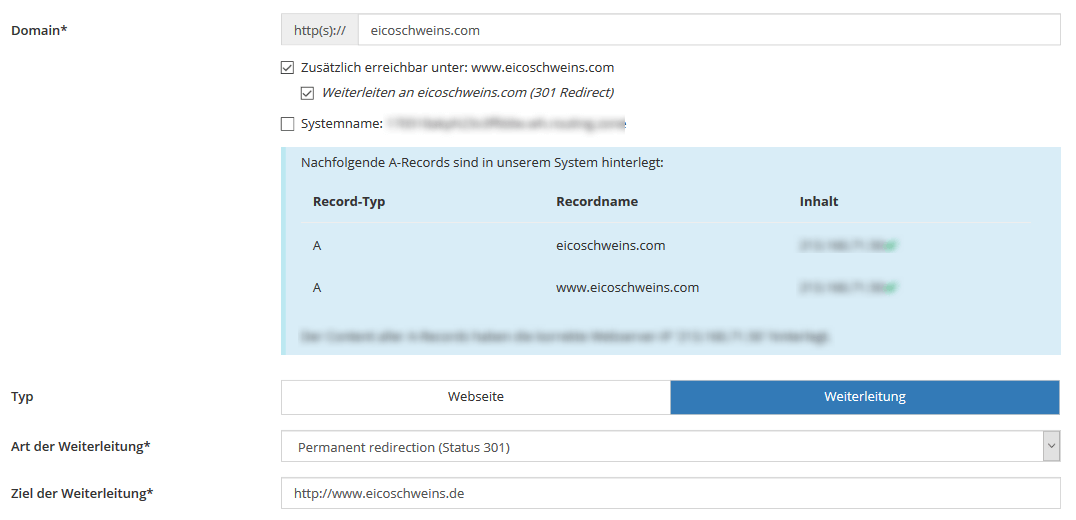
Figure 1: Comment les domaines se comportent, vous contrôlez dans l'interface d'hébergement de site Web
Via la page Web suivi
Si vous travaillez dans de grandes entreprises ou pour des clients, le service informatique ne pourra souvent pas ou ne voudra pas vous donner accès à ces systèmes sensibles. Ensuite, vous n'avez pas d'autre choix que de consulter le site Web de l'extérieur.
Ça vaut le coup de regarder le vôtre Suivi du site jeter. Puisque nous recherchons des doublons de sites Web auto-infligés qui sont 100% identiques à notre version principale, le même pixel de suivi est également installé sur tous. Nous en profitons.
C'est particulièrement facile si vous utilisez Google Analytics. Configurez le filtre suivant pour vous montrer non seulement le chemin de l'URL, mais également le nom de l'hôte. Ensuite, vous laissez Google Analytics suivre les visites sur le site Web pendant un mois (comme d'habitude dans Google Analytics, le filtre affecte uniquement les nouvelles données, pas les données collectées jusqu'à présent).

Figure 2: Avec ce filtre, vous pouvez voir le nom d'hôte de l'URL dans Google Analytics.
Une fois que Google Analytics a collecté de nouvelles données, vous pouvez rapidement visualiser dans le rapport Comportement -> Contenu du site -> Toutes les pages si votre suivi a été déclenché sur des URL différentes de votre domaine avec le protocole et le préfixe corrects.
Figure 3: Cela pourrait masquer une copie de la page Web.
Via un robot externe
En outre, il est avantageux d’envoyer un robot externe via votre site Web. Par exemple, les offres de SEO Expertise. Définissez le robot d'exploration pour analyser également les sous-domaines. Ensuite, vous vérifiez les résultats pour voir si de nombreuses URL ont un préfixe ou un protocole incorrect provenant d'un sous-domaine ou d'un sous-dossier.
Il convient également de jeter un coup d'œil aux liens externes. Trouvez-vous des domaines remarquablement similaires à la version principale?
Vérifiez tous les suspects au hasard pour voir s’ils sont en fait des doublons.
Pro-Tip: Il ne fait pas de mal de vérifier auprès des agences et prestataires de services anciens / actuels s'il existe des doublons de sites Web. En fait, on rencontre parfois des fournisseurs de services qui considèrent comme une bonne idée de mettre en ligne des doublons à 100% des sites Web de leurs clients. Ces agences considèrent alors le "référencement" comme le prénom d'une femme coréenne plutôt que du marketing en ligne …
Coupe rugueuse – attraper les mauvaises herbes à la racine
Maintenant que nous avons tiré les bords de notre site Web et éliminé tout ce qui y règne, nous nous consacrons maintenant à leur intérieur.
La première tâche consiste à vérifier toutes les zones de la page Web et à tout supprimer.
- Ne pas servir l'objectif commercial.
- Nous empêche d'obtenir les meilleurs résultats possibles dans les moteurs de recherche.
Les URL qui servent l'objectif commercial sont des actifs. Les URL qui ne le font pas sont en déséquilibre et nous empêchent de rendre notre site Web facile à utiliser, convivial et optimisé pour les moteurs de recherche.
« URL de service »
Les candidats les plus évidents sont les "URL de service", telles que je les appelle (mentions légales, politique de confidentialité, conditions générales, conditions d'expédition, etc.). Ces URL sont nécessaires pour des raisons juridiques afin de gérer un site Web (ou une boutique en ligne), mais elles nous en rapportent peu. Puisque nous ne pouvons pas les supprimer, nous mettons noindex dans la balise META des robots et nous n'y pensons plus.
Résultats de recherche internes et URL de filtrage
Les pages de résultats de recherche internes sont également des candidats récurrents qui gonflent votre propre index de moteur de recherche. Malheureusement, nous ne pouvons pas les supprimer aussi (car ils sont générés dynamiquement), nous réintroduisons donc la méta-balise robots noindex.
En outre, les filtres dans les boutiques en ligne ont tendance à produire un nombre infini d'URL inutiles en les définissant comme des URL avec des paramètres de filtre attachés. Pour éviter cela, les filtres sont idéalement mis en œuvre avec AJAX et des produits de tri ou similaires. directement sur la page, sans la recharger ni changer l’URL. Si cela n’est pas possible (donc pas de budget pour IT Free), alors au moins un Canonical peut s’assurer que les pages de filtres ne se retrouvent pas dans l’index (devrait).
Les URL de l'image WordPress
Est-ce que vous utilisez WordPress? Ensuite, cliquez une fois sur l'une de vos images et vérifiez si elle s'ouvre avec une nouvelle URL. Si oui, félicitations, vous avez trop (URL) sur le site. Malheureusement, c'est le paramètre par défaut de WordPress. Si vous maîtrisez MySQL, vous pouvez le corriger directement pour l’ensemble du site avec une instruction REPLACE dans la base de données. Sinon, vous devez le corriger manuellement pour chaque image.
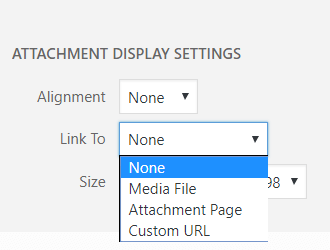
Figure 4: "Aucun" est le paramètre que nous recherchons.
Après tout: WordPress garde en mémoire la dernière sélection de ce menu. Donc, une fois que vous avez sélectionné "Aucun", ce paramètre est également présélectionné sur la photo suivante.
Zones mortes du site
Les «fonctionnalités» du site Web que vous trouvez (en fait) régulièrement sur des sites Web ayant une histoire plus longue sont particulièrement excitantes: un livre d'or du début du millénaire, un forum de spam spam ou un blog avec quelques mauvaises publications. à partir d'un projet de contenu à court terme puis oublié (avec le commentaire spam, bien sûr) .Dans ces zones d'une page Web, il est facile de décider quel hache utiliser – les URL qui accrochent le site comme une pierre Une optimisation après cela ne coûte plus que du temps supplémentaire: partez!
(Vous avez besoin d'aide pour les arguments contre votre patron?) Regardez les pages vues de ces zones dans le suivi du site Web, ce qui vous aidera à prouver qu'il s'agit vraiment d'un poids mort.)
Les URL de précision ne sont nécessaires qu'une fois
Une fois que les zones apparemment mortes du site Web ont été supprimées, les URL individuelles sont maintenant affichées. Premièrement, nous les vérifions également pour les doublons.
Les produits sont affectés à différentes catégories dans une boutique en ligne, chacun générant une URL individuelle? Votre article comporte différentes balises et votre CMS installe la balise à chaque fois dans l'URL, ce qui la rend unique? Le même contenu de votre page Web peut être atteint à partir de plusieurs URL de plusieurs façons. Presque toujours, cela est inutile et en raison du logiciel de votre site Web.
Comment trouvez-vous les doublons d'URL?
C’est là que le robot d'exploration de site Web fiable intervient à nouveau. Vérifiez le rapport de contenu dupliqué dans Réussite de site Web. Il vous montre de manière fiable les doublons possibles de votre site Web. Je vérifie également le nombre de mots des URL. Un nombre de mots identique est un signal fort pour un doublon.
Souvent, les structures claires peuvent être identifiées rapidement. Les produits, qui sont attribués à plusieurs catégories et produisent chacun une URL individuelle, sont le classique dans 95% des magasins en ligne.
Comment gérer les doublons d'URL
Il existe deux manières de gérer les doublons: supprimer ou mettre un texte canonique. Les balises méta des robots noindex ou crawl ban via robots.txt ne sont pas des options, pas. u. pourquoi.
supprimer
Idéalement, vous éliminez la cause d'un doublon. Car les URL qui n'existent plus ne peuvent plus causer de problèmes à long terme. Pas toujours sans développeur, car la boutique / le CMS a prévu ce cas, une fois que les URL individuelles et votre logiciel informatique doivent d'abord être enseignés, sans quoi.
Cette solution est de loin le moyen le plus durable et le plus sûr d’éviter les doubles emplois à l’avenir. Aucun stagiaire ne peut oublier votre protocole d’évitement des doublons, interministériel et répété depuis longtemps. Personne ne peut publier accidentellement votre article Premium sur une douzaine d'URL (au revoir, classement élevé et augmentation du trafic). Et personne ne doit être obligé de cliquer sur le site Web pour obtenir des doublons à intervalles réguliers.
N'oubliez pas les redirections 301 lorsque vous supprimez les doublons qui reçoivent un nombre important de pages vues.
canonique
Si un retrait n'est pas possible, on recourt généralement au Canonical. Avec le paramétrage de Canonicals, on explique aux moteurs de recherche que cette URL n’est qu’une copie et vous devez inclure la version canonique dans leur index.
Malheureusement, le canonique de Google est uniquement considéré comme un indice, et non comme une règle. Il est donc fréquent que votre version canonique n'apparaisse pas (uniquement) dans les résultats de la recherche, mais également dans les doublons.
L’effet positif est (ou devrait être) que tous les PageRank et tous les signaux utilisateur des doublons soient ajoutés à la version canonique et ainsi renforcés.
noindex
La possibilité de définir une méta-balise de robot noindex n'est pas vraiment une alternative.
avantage: Les moteurs de recherche reconnaissent noindex en tant que règles fixes, i. une URL avec un noindex n'apparaîtra certainement pas dans les résultats de la recherche.
inconvénient: L'effet de focalisation des Canonicals (tous les signaux PageRank et utilisateur des doublons sont ajoutés à la version canonique) n'existe pas lors de l'utilisation du noindex. Le PageRank est distribué via le lien interne sur le site internet, mais malheureusement non ciblé. Les signaux de l'utilisateur expirent complètement.
rampent interdiction
La dernière chance d'imposer une interdiction d'analyse sur robots.txt n'est également pas la meilleure idée.
L'avantage: Cela permet d'économiser le budget d'analyse.
Les inconvénients: Google n'aime pas les interdictions d'exploration, car Google ne sait pas ce qu'il y a sur l'URL. Google ne peut donc pas garantir à ses utilisateurs que la visite est sécurisée. Dans le pire des cas, cela affecte la note du reste du site. En outre, une interdiction d'analyse ne constitue pas une interdiction d'indexation. C'est-à-dire qu'une URL qui ne peut pas être explorée peut toujours être indexée, et uniquement avec les informations minimales que Google reçoit sur les liens internes ou externes via cette URL. Cela semble dans les SERP jamais bons et enlacés en conséquence mauvais.
Raffinage – Ce qui ne fleurit pas doit disparaître
Souvent, des sections entières d'une page Web ne fonctionnent pas mal, mais il existe quelques URL qui réduisent les performances globales d'une section de page Web. Les URL sans contenu, les produits jamais achetés ou les articles non lus en sont des exemples. Encore une fois, cela vaut la peine de faire le tri afin que les utilisateurs et les moteurs de recherche ne contiennent que du contenu de haute qualité et cette récompense avec de bons signaux et un meilleur classement.
Pour savoir quelles URL sont particulièrement bonnes ou particulièrement mauvaises pour les utilisateurs et les moteurs de recherche, consultez le suivi du site Web et la console de recherche Google.
S'il vous plaît noter: Sur les grands sites Web en particulier, toutes les URL n’ont pas les mêmes tâches. Il est donc judicieux de comparer les performances des URL avec celles d’autres URL exécutant la même tâche, plutôt que les valeurs moyennes de l’ensemble du site Web. Google Analytics offre la possibilité de regrouper les URL en zones à l'aide de groupes de contenu.
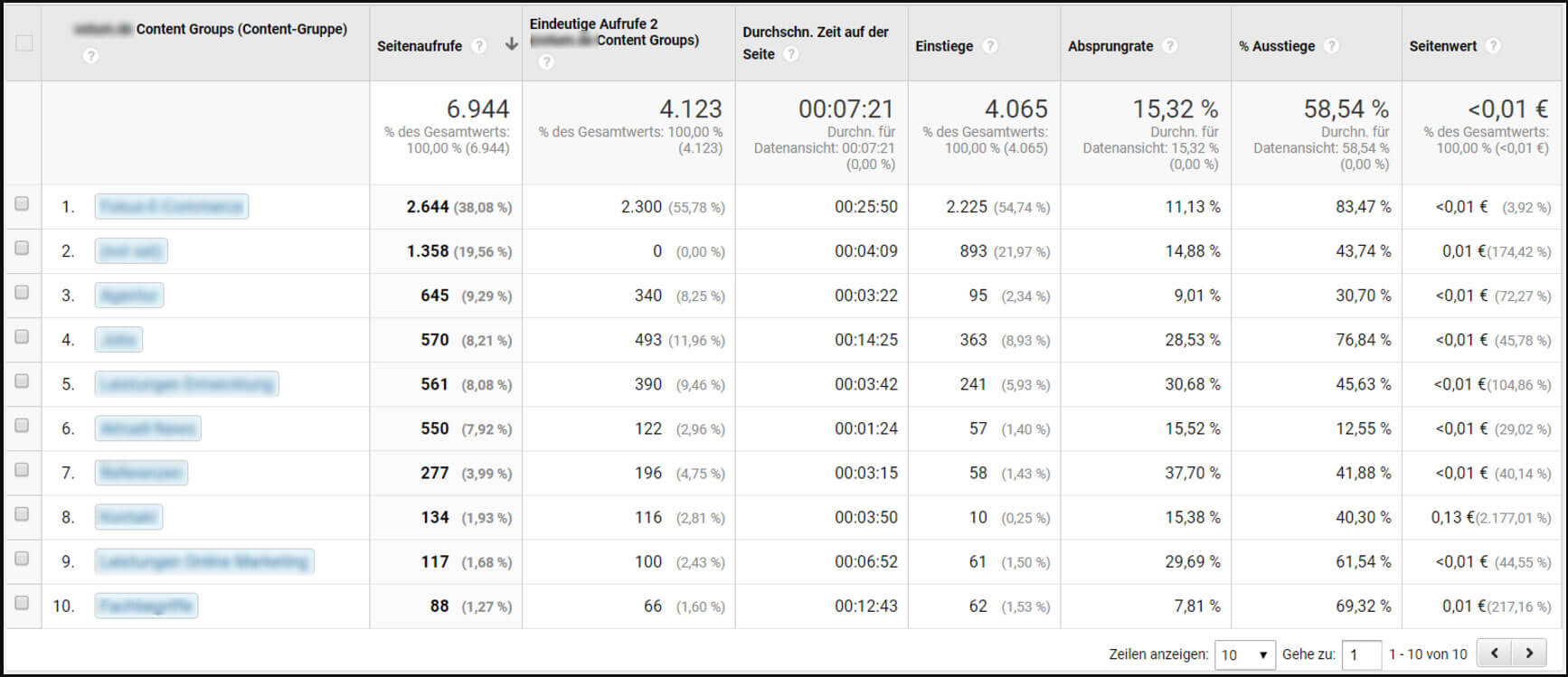
Figure 5: Évaluation des groupements de contenu dans Google Analytics
Les indicateurs suivants permettent d’évaluer les performances des URL:
Google Analytics
- Nombre et nombre de conversions (URL du produit)
- Nombre et nombre d'objectifs atteints
- visites de page
- durée du séjour
- Taux de rebond
- Entrées et sorties
Console de recherche Google
- Nombre et pertinence du classement
- position de rang
- impressions
Plus une URL est métrique, plus les signes de suppression d'URL sont évidents. Bien que cela aide de mettre un noindex en premier, nous sommes convaincus d’optimiser l’URL plus tard. Cependant, d'après notre expérience, "j'optimiserai cela plus tard" est l'excuse la plus courante pour oublier le trafic des moteurs de recherche pendant longtemps. Il est préférable de prendre la bonne mesure tout de suite.
Bien sûr, il est nécessaire d’être (auto) critique même si cela fait parfois mal. Les pages Web grouillent de "contenu est roi" sur le mauvais contenu. Soyez honnête avec vous et votre entreprise. Voudriez-vous vraiment lire cela vous-même? Voulez-vous vraiment que votre entreprise soit associée à du mauvais contenu plus longtemps encore? Bien alors!
Si votre patron regarde le visiteur et les chiffres des ventes dans trois mois, il vous remerciera d'avoir le courage de lui dire en face: "Cela nous nuit, il faut y aller!"
Conclusion – attribution de votre site Web
Nous sommes maintenant passés du plus extérieur au plus petit du site Web et avons éliminé les sources d’URL inutiles. En pratique, cela peut entraîner des changements spectaculaires dans le nombre d'URL existantes.
Exemple: après l'analyse complète du site Web d'un client (fournisseur de services doté d'un petit magasin en ligne de 50 produits), nous avons trouvé plus de 180 000 URL. Google venait d'indexer 3 000 URL. À la fin de notre optimisation, il ne restait que 2 420 adresses URL, dont 1 490 ont été répertoriées par Google jusqu'à présent. Depuis, le site Web a considérablement gagné en classement et en trafic.
Nous travaillons actuellement pour un client dont le magasin en ligne a trouvé plus de 3 000 000 d’URL (moins de 5 000 sont indexées). Après optimisation, il restera environ 100 000 URL. Nous sommes impatients de voir l'optimisation dans Google.