Sommaire
L’optimisation des moteurs de recherche est une question de visibilité dans les résultats de recherche. Et il se passe beaucoup de choses depuis quelques années maintenant. Panda et Penguin ont changé les règles du classement et le graphe de connaissances nous a apporté le concept d'entités.
Dans l'article d'aujourd'hui, je voudrais montrer comment ils sont présentés dans les résultats de recherche sans quitter l'écosystème de Google. C'est ce que j'appelle la boîte à entités.
Depuis l'annonce du colibri, je ne pouvais rien faire de plus toute la journée que d'entrer des recherches sur Google et de voir ce qui se passe dans les résultats de recherche. J'utilise généralement Google.com car, aux États-Unis, les mises à jour du géant des moteurs de recherche sont mises à jour plus rapidement et de manière plus approfondie. Un exemple sont les articles de fond, que j'ai décrits ici comme une page de fonctionnalité des résultats de la recherche et qui n'ont jamais été découverts sur Google.de.
Les résultats de recherche sont plus dynamiques que jamais
Avant de commencer, je voudrais dire brièvement que les résultats de recherche de Google ne sont plus des classements statiques, neutres ou cohérents. Le temps est révolu depuis longtemps par des éléments personnalisés tels que l'emplacement, l'historique des recherches ou Rechercher + votre monde pour les utilisateurs connectés. Cela ne signifie rien de moins que vous et moi pouvons obtenir des résultats très différents sur la même demande.
De plus, Google a changé sa propre compréhension de la langue en comparant non seulement les mots-clés, mais en comprenant les termes comme des entités. En conséquence, Google apprend le sens des mots par le biais de connexions sémantiques. Avec le Knowledge Graph, Google développe une sorte de cerveau qui ajoute encore plus de dynamisme aux résultats de recherche dynamiques. L'élan provient principalement du fait que Google a constamment évolué et est devenu adaptatif. Celui qui apprend fait des erreurs. Les erreurs sont des expériences, et les expériences donnent lieu à de nouvelles idées et perspectives qui peuvent vous rendre plus intelligent si vous le souhaitez.
Même si Google peut modifier des schémas bien établis, la suppression des images de l'auteur des résultats organiques a récemment montré. Il va sans dire que, du point de vue de Google, cette solution est "plus intelligente", dans la mesure où elle crée le potentiel de clics encore plus lucratifs sur AdWords. Le fait que cela semble plutôt préjudiciable et gênant pour les auteurs est une autre perspective à laquelle Google ne semble pas se soucier du tout.
Les entités comprennent Google grâce à des données structurées
Google aime le contenu de manière structurée. Cela signifie qu'ils obtiennent des méta-informations et que plus l'ensemble est cohérent, plus l'algorithme peut les gérer facilement. Il existe deux manières de fournir des données sous forme structurée:
- Entrées dans des bases de données de métadonnées telles que Freebase, des moteurs de recherche de niche ou d'autres annuaires professionnels tels que Google Business (aka Branchencenter, aka Places, ou encore Local, ou confusion inutile)
- Structurez le contenu sur votre propre page. Cela est possible grâce à une mise en forme simple telle que des sous-titres, des listes, des tableaux ou via Schema.org, un langage de balisage normalisé sur lequel les «grands» moteurs de recherche ont convenu.
Rien ne garantit si et quelles données Google utilise pour les afficher sur les pages de résultats. Ne pas jouer par principe parce que vous ne voulez pas rendre les choses encore plus faciles pour Google, cependant, est synonyme de vous mettre à l'épreuve. Néanmoins, se pose la question importante et légitime de savoir quelles données une entreprise veut distinguer et donc révéler.
Pour des réponses spécifiques, le cas individuel doit être pris en compte, mais une recette de brevet fondamentale est la suivante: Bien entendu, les secrets commerciaux et commerciaux ne font pas partie des résultats de la recherche et doivent être protégés. Les données accessibles au public, telles que le nom de la société, le logo, l'adresse, les coordonnées, le secteur ou les heures d'ouverture, c'est-à-dire les données dans lesquelles il est dans l'intérêt de la société qu'elles soient trouvées et correctes, appartiennent à d'excellentes ou à d'autres bases de données (!) Pertinentes enregistrées!
Sources des valeurs de données des propriétés de l'entité
De moteur de recherche, Google est devenu une machine à répondre et à découvrir, et les méta-informations dans les résultats de recherche sont devenues de plus en plus détaillées, complètes et colorées ces dernières années. Auparavant, Wikipedia était utilisé comme une ressource pour les données, ce qui signifie que les résultats de recherche au-dessus du pli étaient en partie très, très Wikipedialastig et le sont toujours. Les relations publiques Wikipédia sont bien plus qu’un thème «sympa à avoir».
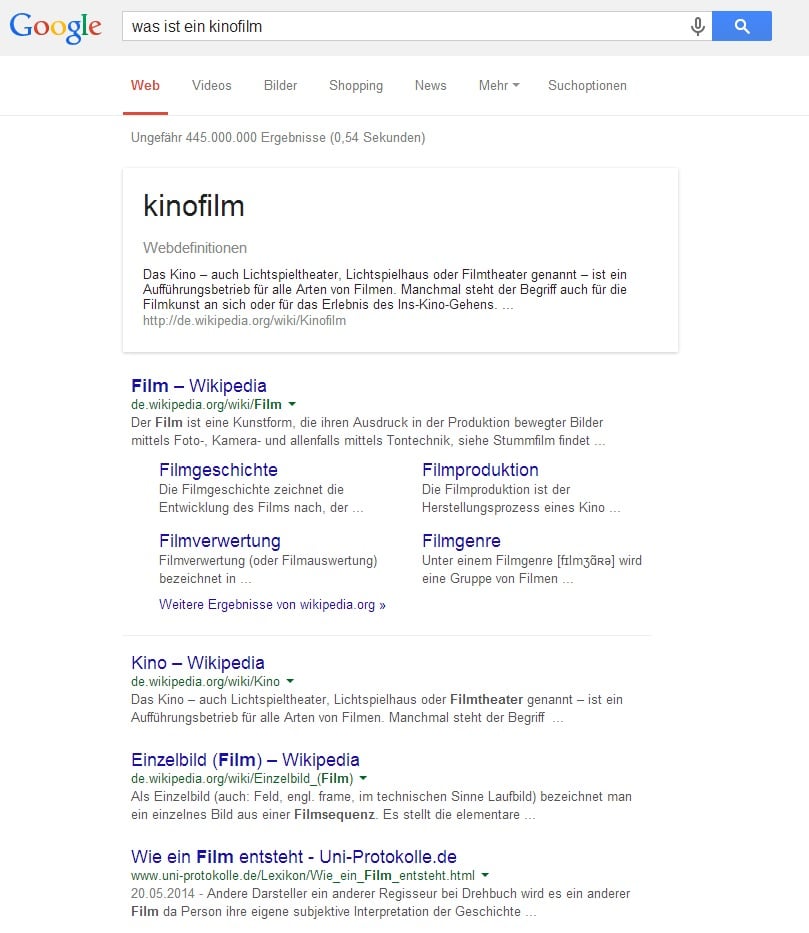
En particulier pour les recherches dont l’intention est probablement une définition ou une information générale, Wikipedia est très populaire et ne changera pas aussi vite. Lorsqu'on lui demande "Qu'est-ce qu'un film?", Le résultat suivant apparaît:
Google recherche également d'autres sources précieuses pertinentes pour différents types de requêtes. Je ne peux pas juger si cela est toujours juste, si c'est une question ouverte et dans quelle mesure il existe une coopération et un accord, mais je voudrais donner trois exemples:
Information nutritionnelle
Les informations nutritionnelles proviennent de la base de données américaine USDA:

univers
En réponse à ma question, "À quelle distance se trouve Mars?", Google a utilisé un extrait de texte d'Univers Today, un site d'informations astronomique établi aux États-Unis:

Coupe du monde de football
Au cours de la Coupe du Monde, des boîtes de réponses dans le style suivant ont été affichées pour des requêtes telles que "Game Today" ou "World Cup 2014". La source était la FIFA, ce qui a beaucoup de sens en tant qu'hôte de la Coupe du monde.

Zone Entités: vous restez dans l'écosystème de Google
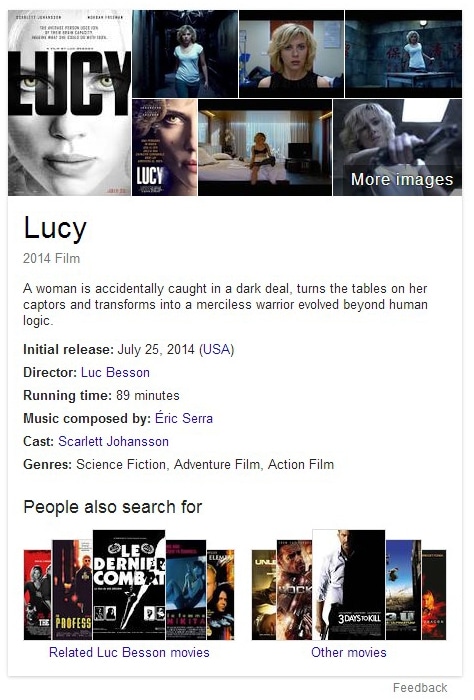
Quand je voulais me renseigner la semaine dernière sur le film "Lucy", j'ai remarqué pour la première fois un répondeur sans référence Wikipedia. Bien sûr, l'article de Wikipedia sur le film était le premier résultat de recherche organique, mais dans la boîte, aucun lien Wikipedia ne peut être trouvé, j'ai trouvé cela étonnant. Au lieu de cela, il y avait un certain nombre de liens menant vers d'autres pages de résultats de recherche Google sémantiquement pertinentes. Donc, vous restez dans l'écosystème de Google.
Globalement, le concept de Knowledge Graph est très facile à reconnaître. Il s'agit de présenter une entité (le film Lucy) à laquelle des caractéristiques spécifiques ont été assignées (un film a un réalisateur, un acteur principal, la durée de la pièce, etc.) et ces qualités ont des valeurs spécifiques (réalisateur = Luc Besson, acteur principal = Scarlett Johannson, temps de jeu = 89 minutes). L'ensemble cherche alors la requête "Lucy Movie" comme ceci:
L'aspect du moteur de découverte devient de plus en plus intéressant, car la zone d'entité favorise la recherche de résultats de recherche sémantiquement pertinents. Cela signifie que toute personne qui travaille bien pour la clé "date de sortie initiale du film Lucy" a également une chance d'être trouvée pour "film Lucy". Dans ce qui suit, j'ai grossièrement démoli la zone Entités:
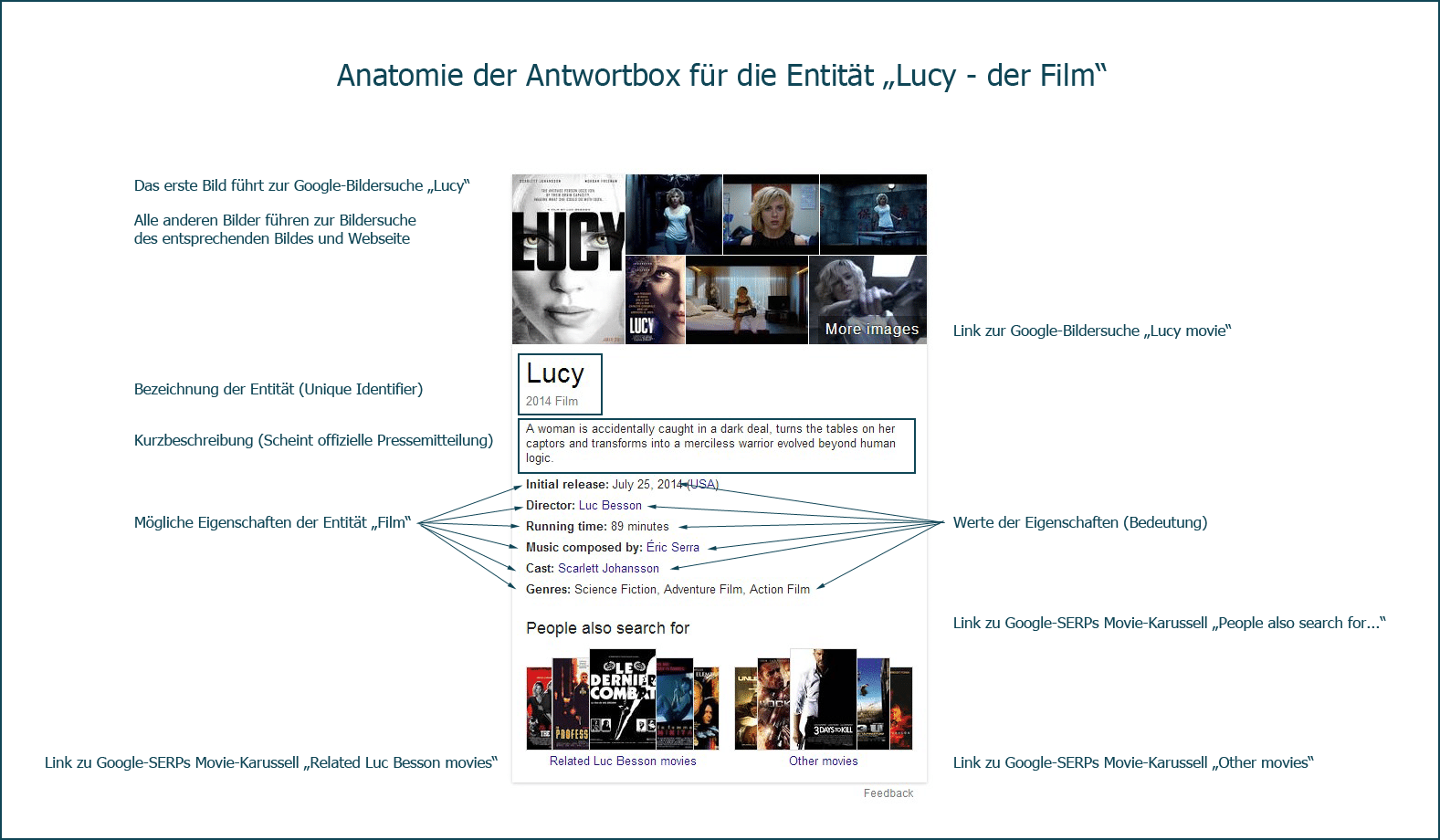
Constatations relatives à l'optimisation des entités
Le graphe de connaissances permet d’obtenir une vue globale des entités et d’optimiser pour une entité une compréhension globale de ces entités. Dans le cas d'un film, il est donc important de déterminer quelles qualités un film peut avoir. Ces propriétés sont définies dans l'ontologie. Il est donc important que l'optimisation des entités comprenne les notions ontologiques sous-jacentes, qui sont d'ailleurs très naturelles pour nous, les humains.
Donc, pour bien classer avec un article ou une page Web sur un film, cet article devrait couvrir un ou plusieurs niveaux de l'entité. Pour la planification de l'article, il est judicieux de consulter le site Web de Schema.org et de voir quelles fonctionnalités il existe. Pour les films, les propriétés suivantes s'appliquent:
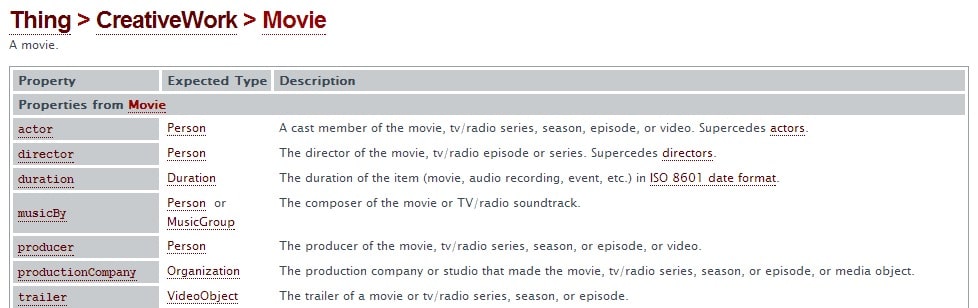
Schema.org comme outil de planification de contenu précieux
Schema.org peut être vu comme la réponse à la question ennuyeuse "sur quoi dois-je écrire?!?" Cela définit les niveaux considérés comme pertinents pour une entité particulière. Mais cela ne signifie pas que la créativité est morte. Après tout, il s’agit d’une base de données accessible au public et ne doit donc pas être considérée comme un avantage concurrentiel, mais comme un guide approximatif.
En règle générale, restez, devenez une marque, créez la confiance, faites preuve d’expertise et de passion et offrez ainsi une valeur ajoutée émotionnelle au groupe cible. Bien qu’ils ne soient certainement pas des facteurs de classement mesurables mais mesurables, les signaux d’amour (ou signaux sociaux) du public cible sont probablement les facteurs les plus durables et les plus durables de la présence SEOnline.