
Sommaire
Suite à son annonce en juillet, Google n'utilise plus la directive Noindex dans le fichier robots.txt depuis le 1er septembre 2019. La question la plus récente est la suivante: Google indexe-t-il maintenant moins les URL verrouillées avec l'URL interdite que par le passé?
Comment en est-il arrivé à l'introduction de Noindex dans le fichier robots.txt
Mais revenons au début. En 2008, Matt Cutts, ancien responsable de l'équipe de spam sur le Web de Google, a mentionné pour la première fois la déclaration Noindex dans le fichier robots.txt. Cette directive était une option utile – même si elle était la plus inconnue – et donc une solution non utilisée dans le contexte de l'inclusion par Google d'URL verrouillées dans l'index, par opposition à de nombreux autres moteurs de recherche dans le fichier robots.txt. Mais elle a travaillé!
Certes, il reste à se demander aujourd'hui pourquoi Google n'a pas simplement utilisé l'indication interdire comme un signal de non-indexation ou de désindexation des URL. Mais après tout, ils ont proposé une alternative et ont soutenu le Noindex – même officieusement – et les ont soutenus.
SEO est sur le bon pied de l'exploration et de contrôle d'index
Mais les jours où Matt Cutts avait quelque chose à dire sur Google sont loin derrière. Même s'il n'y avait aucun changement dans l'utilisation de robots.txt, même des années plus tard, en avril 2019, Gary Ilyes, analyste des tendances pour les webmasters de Google, laissait entendre que cela changerait bientôt. Sa raison:
- "Techniquement, le fichier robots.txt sert à l'exploration. Les balises méta sont pour l'indexation. Lors de l'indexation, ils seront au même stade, il n'y a donc aucune bonne raison de les avoir tous les deux. "
En principe, personne ne contesterait avec Gary que le fichier robots.txt est un instrument de contrôle de l'analyse et que la balise Meta-Robots est un outil de contrôle d'index. Mais dans de nombreux cas, un SEO veut atteindre la cible idéale des deux mondes. Pourquoi, faut-il demander, faut-il choisir l'une ou l'autre? Un propriétaire de site qui empêche l'exploration des URL dans le fichier robots.txt ne veut pas non plus qu'elles soient indexées.
Une déclaration de Google donne de l'espoir
En juillet 2019, ce qui a été suggéré en avril a été confirmé. Google a annoncé via son blog Webmaster Central qu'ils n'interpréteraient plus le Noindex dans le fichier robots.txt en septembre. Ici, ils ont fourni la déclaration suivante dans de nombreux référenceurs pour discussion:
- "Alors que le moteur de recherche peut indexer une URL en fonction d'autres pages, sans voir le contenu lui-même, nous visons à rendre les pages moins visibles à l'avenir."
Bien que cette déclaration soit tout sauf claire et sûre au sens de "notre objectif est" ou "moins visible", elle laissait en quelque sorte espérer qu'à l'avenir Google n'inclura plus d'URL bloquées dans l'index en raison de la déclaration non autorisée.
Un inventaire initial: à quel point les URL précédemment bloquées avec la spécification Noindex sont-elles moins visibles?
Un peu plus d'un mois s'est écoulé depuis la transition de Google vers l'interprétation de la directive noindex dans le fichier robots.txt. Cela laisse suffisamment de temps maintenant pour voir comment l'état d'indexation des URL bloquées par l'instruction non autorisée a effectivement diminué.
Pour analyser cela, nous avons examiné les domaines de clients qui avaient prématurément remplacé la directive "no index" par une interdiction en juillet – mais qui ont été inversés peu de temps après en raison d'une forte augmentation de l'indexation (voir notre article dans le numéro de juillet du magazine SEO Expertise) 2019). Comme il ne restait plus assez de temps pour effectuer une désindexation complète jusqu'au 01 septembre, les quatre projets avaient toujours suffisamment d'URL bloquées dans l'index.
Voyons donc dans les captures d'écran suivantes, si dans les semaines qui ont suivi le 1er septembre, le nombre d'URL indexées a encore diminué (comme on pouvait s'y attendre au sens de la déclaration de Google):
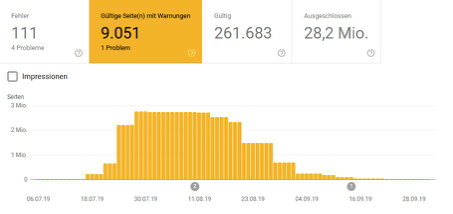
Cas 1: Grand magasin en ligne de mode
Cas 2: Boutique en ligne de pêche spécialisée
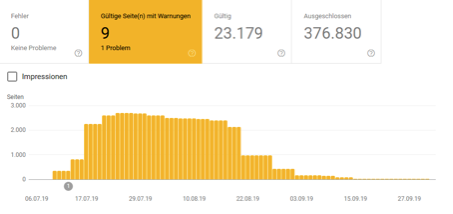
Ici, on peut voir que la tendance à la désindexation des URL bloquées par le fichier robots.txt (par le biais des options interdire et noindex) pourrait être poursuivie. La question ouverte est certainement de savoir s'il s'agit toujours d'effets en aval. Parce que supprimer les URL correspondantes de l'index nécessite bien sûr que les URL respectives soient ré-analysées en conséquence. Que la tendance se maintienne ou non avec le Disallow, on ne peut donc rien affirmer sur la base de ces deux cas.
Passionnant est également le cas suivant. Ici, le fichier robots.txt a été modifié quelques heures avant le 1er septembre, de sorte qu'au lieu de Noindex, seules les informations non autorisées ont été intégrées. Le résultat est assez surprenant:
Cas 3: Boutique en ligne multimédia spécialisée
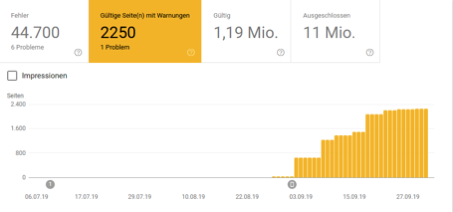
Le nombre d'URL bloquées malgré leur interdiction a considérablement augmenté depuis le basculement. Cependant, pour être honnête, il faut ajouter que les premières URL bloquées avaient déjà été indexées avant la conversion de robots.txt, et la console de recherche Google indique que le domaine a été remplacé par le premier index mobile depuis le 1er septembre. En principe, ces derniers ne devraient en réalité avoir aucune influence sur cette question ici, mais néanmoins cela ne devrait pas être mentionné sur le point.
Examens supplémentaires: Comment l’état d’indexation a-t-il évolué pour les sites Web qui se sont toujours fiés à la déclaration non autorisée?
Nous avons également examiné quelques projets supplémentaires qui n'avaient jamais auparavant utilisé l'instruction Noindex dans le fichier robots.txt, mais dont certaines URL étaient bloquées dans l'index. Nous espérons que Google tiendra ses promesses. La tendance actuelle est de voir ces URL "moins visibles".
Dans les captures d'écran ci-dessous, examinons le résultat des statistiques de la console de recherche Google "Indexées, mais bloquées par le fichier robots.txt":
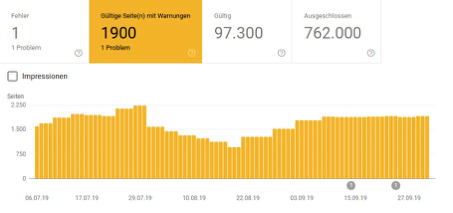
Cas 4: Magasin en ligne spécialisé de quincaillerie
Cas 5: Marque du fabricant avec la boutique en ligne
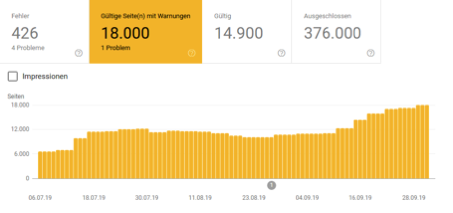
Les deux projets présentés, ainsi que de nombreux autres que nous avons examinés, ne donnent pas l'impression que la directive Disallow (interdire) depuis septembre a permis de réduire le nombre d'URL bloquées dans l'index Google. Les deux courbes ci-dessus sont plus susceptibles de donner l’impression opposée, mais ne vous y trompez pas. Il y a aussi des exemples où le cours est cohérent ou même en déclin. Mais il semble que ce soient davantage les fluctuations naturelles qui existaient auparavant.
conclusion
Dans les cinq cas, on peut constater que l'indication de non-autorisation actuelle ne conduit pas à la désindexation des URL autant qu'on l'aurait espéré. Bien sûr, après seulement un mois, il est prématuré de procéder à une évaluation finale des nouvelles dispositions de robots.txt. La condition pour influencer l'indexation est toujours une exploration précédente et voici 4-5 semaines peut ne pas être suffisant. Parce que ces adresses ont été exclues de l'analyse, car la fréquence de test de Google est donc logique. Nous voudrions également nous référer à Boosting 55, l'article de Stephan Czysch, directeur général du département, sur la réindexation du contenu, qui l'explique plus avant.
Néanmoins, le statu quo actuel donne à réfléchir. L'hypothèse est évidente que Google, dans sa déclaration sur la nouvelle gestion de robots.txt avec "moins visible", ne signifie pas l'indexation réelle des URL bloquées, mais le rendu de ces pages pour les requêtes de recherche pertinentes, c'est-à-dire les requêtes en dehors des requêtes du site. Dans ce cas, aucun changement dans l'état d'indexation n'est attendu dans les mois à venir. Au contraire, les statistiques pourraient augmenter à nouveau.
Il est avancé que l'indexation des URL bloquées robots.txt n'est pas problématique et a une incidence négative sur les performances réelles de la recherche Google organique. Cela est certainement vrai aussi dans la plupart des cas. Néanmoins, il est surprenant de la part de Google. Pourquoi alors jouer ce fait comme un avertissement dans la console de recherche Google et ne propose plus de solutions où le contrôle de l’exploration et de l’indexation peut être optimisé en même temps. Le fait que Google inclue même ces pages dans l'index des moteurs de recherche n'a aucun sens.
Dans tous les cas, nous garderons un œil sur le sujet et répéterons le même test dans quelques mois. Quelles sont vos observations concernant l'indexation des URL bloquées dans le fichier robots.txt? S'il vous plaît laissez-nous votre avis ici!