Sommaire
Comme expliqué dans le dernier article de ma série d'articles sur les entités et la sémantique dans la recherche, les bases de données de connaissances telles que le graphe de connaissances ont une tâche difficile pour maintenir l'exhaustivité et l'exactitude des informations. Une condition nécessaire pour être complet est que Google puisse identifier, interpréter et extraire des informations dans des sources de données non structurées. Plus à ce sujet dans ce post.
Le parcours de Google vers la compréhension sémantique
Le souci d'extraire des informations sémantiques sur des objets ou des entités à partir de documents non structurés préoccupe Google depuis la fin des années 90. Ainsi, il existe un brevet Google de 1999 intitulé Extraction de schémas et de relations à partir de bases de données dispersées. Effectuez une recherche sur le World Wide Web (pdf). Il s’agit de l’un des premiers brevets Google sur des questions sémantiques.
Lire la suite dans l'article Quelle est l'intelligence de Google? Une véritable compréhension sémantique ou juste des statistiques? ,
La première étape des premières années du Knowledge Graph consistait à extraire des données structurées et semi-structurées. Ici, Google est déjà assez doué pour contenir des informations provenant, par exemple, de Extraire et traiter Wikipedia ou Wikidata. En savoir plus à ce sujet dans les articles Comment Google traite-t-il les informations provenant de Wikipedia pour Knowledge Graph? et tout ce que vous devez savoir sur les types d'entité, les classes et les attributs.
Mais cela ne peut être que le début, car les limites d'une telle méthodologie sont évidentes.
Le problème des bases de connaissances telles que Wikipedia et Wikidata
Puisque Wikidata et Wikipedia ne couvrent qu'une fraction de toutes les entités du monde réel, la tâche la plus difficile pour Google consiste à extraire des informations sur les entités et les types d'entités d'autres sites que ceux mentionnés ci-dessus. La plupart des sites Web et des documents sont tous différents et ont i.d.R. pas de structure uniforme. Google a donc encore beaucoup à faire pour développer davantage le graphique de connaissances.
Informations structurées et semi-structurées provenant de sources de données gérées manuellement, par ex. Wikipedia ou Wikidata sont souvent examinés et préparés afin que Google puisse facilement les extraire et les inclure dans le graphique de connaissances. Mais ces sites et bases de données ne sont pas non plus parfaits.
Le problème des bases de données gérées manuellement et des sites Web semi-structurés tels que Wikipedia est celui qui n'existe pas. état completcela validité et actualité les données.
- état complet des moyens basés sur les entités détectées dans une base de données en soi, ainsi que sur leurs attributs et types d'entités associés.
- validité fait référence à l'exactitude des attributs, déclarations ou faits enregistrés
- actualité fait référence aux attributs des entités détectées
Surtout la validité et l'exhaustivité sont en conflit. Si Google s'appuie uniquement sur Wikipedia, la validité des informations est très élevée en raison des tests rigoureux menés par des Wikipédiens enthousiastes. Quand il s'agit d'être à jour, cela devient plus difficile et la complétude des informations ne suffit tout simplement pas, car Wikipedia ne cartographie qu'une fraction de la connaissance du monde.
Pour atteindre l'objectif de complétude approximative, Google doit pouvoir extraire des données non structurées de sites Web tout en s'assurant de leur validité et de leur actualité. Par exemple, les articles dans Google Actualités constituent une source d'informations très intéressante pour garantir la mise à jour des entités déjà présentes dans le graphique de connaissances.
Google possède un vaste réservoir de connaissances sur les milliards de contenus ou de documents indexés. Il peut s'agir de pages d'actualités, de blogs, de magazines, de critiques, de boutiques, de glossaires, de dictionnaires …
Mais toutes les sources d’information ne sont pas suffisamment valides pour être utiles en tant que source d’information. Par conséquent, dans la première étape, le domaine correct doit être identifié comme source.
En identifiant les mentions d'entités déjà stockées dans le graphe de connaissances, les documents pertinents pour les entités peuvent être identifiés dans une première étape.
Les termes utilisés dans le voisinage immédiat desdites entités en tant que co-concurrents peuvent être liés à celles-ci. À partir de cela, des attributs ainsi que d'autres entités de l'entité principale peuvent être extraits du contenu et stockés dans le profil d'entité respectif. La proximité entre les termes et l'entité dans le texte, ainsi que la fréquence des paires d'attributs d'entité majeures ou des paires d'entités sous-entités principales peuvent être utilisées à la fois comme validation et comme pondération.
Ainsi, Google peut constamment enrichir les entités du graphe de connaissances avec de nouvelles informations.
Dans ce qui suit, j'ai effectué des recherches sur les brevets et d'autres sources dans Google pour trouver des moyens de rendre justice, de rappeler, de valider et de respecter les délais.
Avant d’entrer dans les approches concrètes, j’aimerais aborder brièvement les deux méthodes d’extraction brutes. Extraction ouverte et fermée. Avec l'extraction fermée, la condition préalable est que les entités avec un URI soient déjà capturées et complétées ou mises à jour pour les nouveaux attributs et les relations avec d'autres entités. L'extraction ouverte consiste également à identifier et à capturer des entités précédemment inconnues ou non enregistrées et leurs attributs. Cela concerne l'intégralité de l'ensemble des bases de connaissances, et pas seulement l'intégralité des attributs et des relations par entité.
Exemple de processus d'extraction fermée de faits / d'informations
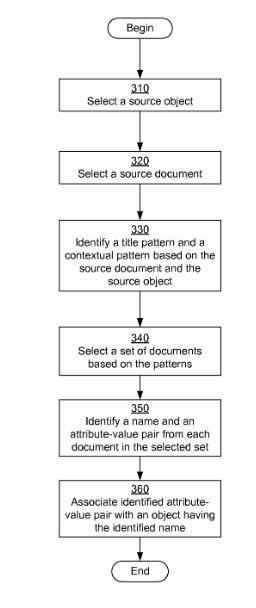
Source: brevet Google US8812435B1
Le document Google Objets de formation et Faits tirés de documents explique comment Google peut capturer de nouvelles informations sur des entités / objets déjà détectés sans intervention humaine.
abstrait
Système, procédé et programme informatique pour l'apprentissage d'objets et de faits à partir de documents. Un objet source et un document source se trouvent sur l'objet source et le document source. Un ensemble de documents correspondant au modèle de titre et au modèle contextuel est sélectionné. Pour chaque document de l'ensemble sélectionné, un nom et un ou plusieurs faits sont identifiés en appliquant le modèle de titre et le modèle contextuel au document. Les objets sont identifiés ou créés en fonction des noms identifiés et associés aux faits identifiés.
Dans ce processus, les documents sont extraits d'un index, où le nom de l'entité ou le nom de l'objet dans le titre est appelé et où une paire d'attribut et de valeur d'attribut déjà enregistrée se produit. Cela pourrait par exemple contribuer à Angela Merkel, dans laquelle sa profession est mentionnée dans le Bundesklanzler. À l'étape suivante, un modèle contextuel est attribué au document. Cela pourrait par exemple sa "réunion d'hommes politiques". Maintenant, d'autres documents seront complétés avec les mêmes caractéristiques de modèle contextuel et de titre. À partir de ce document, vous pouvez extraire de nouveaux objets / entités avec les paires attribut-valeur-attribut correspondantes (voir l'organigramme à gauche).
La condition préalable est qu'une entité soit déjà enregistrée dans un référentiel de faits ou un graphe de connaissances à partir d'un contexte spécifique. Dites que ce n'est pas une forme d'extraction complètement ouverte.
Les méthodes les plus intéressantes sont l'extraction ouverte. Les concepts d'entités qui sont couverts sur des sites Web tels que Wikipedia sont déjà bien sur Google dans le panneau de connaissances des SERP. Par conséquent, la question de savoir comment Google peut traiter à l'avenir des entités moins pertinentes est bien plus intéressante.
Détection d'entités de queue
En principe, les entités de Google Tail peuvent détecter et capturer de trois manières. L’itinéraire précédent via des données structurées, par ex. depuis Wikidata ou l'extraction du contenu en ligne de divers blogs, sites Web, réseaux sociaux … ou manuellement via des données structurées au format Json-ld ou à microdonnées.
Je pense que Google avait pour objectif d'étendre le graphe de connaissances des entités secondaires via Google+ et les annotations de l'auteur. Nous savons comment cela s'est terminé au plus tard avec la fermeture de Google+ en avril 2019.
Actuellement, de nombreux référenceurs essaient déjà de créer leurs propres profils d'entité, comme je le fais moi-même. Dans certains cas, il est possible d’obtenir les premières informations du Knowledge Panel dans les SERP.
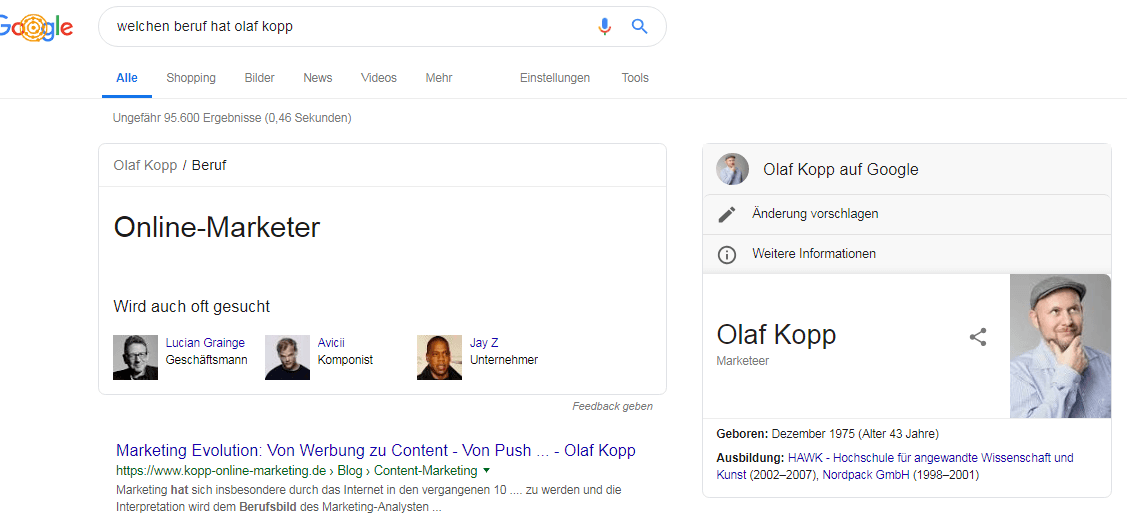
Panel de connaissances Olaf Kopp
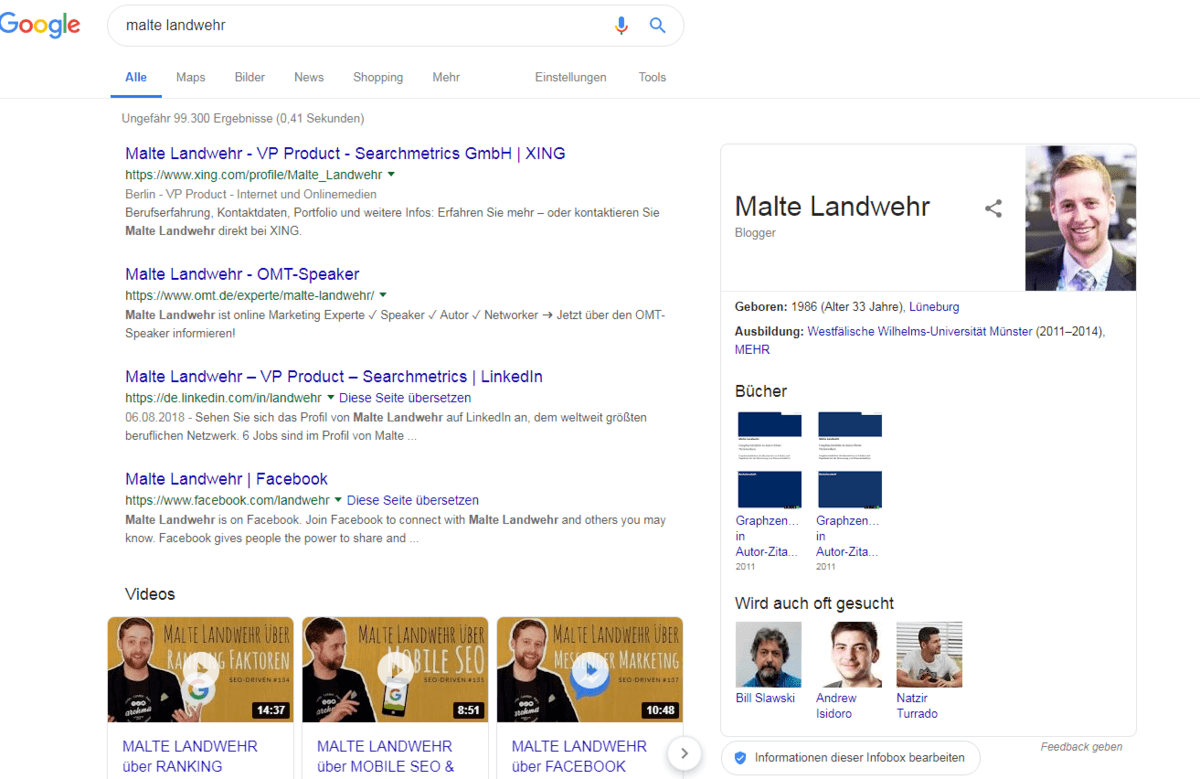
Panneau de connaissances peint Landwehr
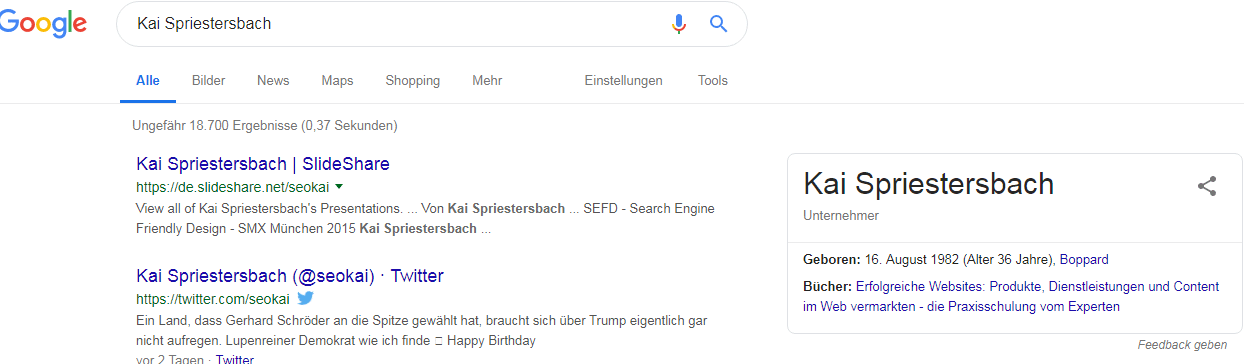
Panneau de connaissances Kai Spriestersbach
Mais je pense que ces manières ne sont qu'une solution provisoire, car le système et le test doivent continuer à être effectués manuellement. Ce n’est donc pas une solution évolutive que Google préférera. Ces dernières années, Google a tenté de promouvoir l'attribution de données structurées par les webmasters et les référenceurs. Cela n'a qu'une raison pour moi: Ils souhaitent fournir à leurs algorithmes d'apprentissage automatique autant de données structurées validées par l'homme que de données d'apprentissage., L'objectif est de ne plus avoir besoin de données structurées à un moment donné. Plus dans ma contribution Pourquoi les données structurées pour Google pourraient-elles devenir redondantes à l'avenir.
L’un des moyens pour que Google soit dans l’avenir consiste à identifier automatiquement les nouvelles entités à partir de documents librement disponibles, à les interpréter et à les créer dans le graphe de connaissances. Les étapes suivantes peuvent être effectuées pour cela:
- Identification d'entités potentielles (reconnaissance d'entité nommée)
- Extraction de classes et de types: Affectation de l'entité à une ou plusieurs classes et types sémantiques en fonction du contexte dans lequel l'entité est appelée à plusieurs reprises. Cela pourrait être les premiers jeux d'attributs déposés, qui sont progressivement complétés par des valeurs.
- Extrait des relations: Établissez des relations avec d'autres entités déjà identifiées avec des modèles similaires ou similaires ou dans des contextes similaires.
Dans certains brevets Google, vous pouvez trouver des indices sur la manière dont Google pourrait résoudre ce problème à l'avenir. Par exemple, les systèmes et procédés informatisés de brevets pour l'extraction et le stockage d'informations concernant les entités fournissent l'approche suivante pour extraire de nouvelles documents, y compris des attributs et des classes d'entités associées.
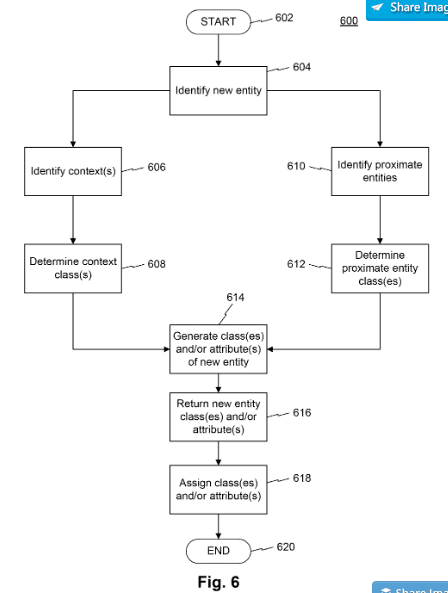
Source: brevet Google US10198491B1
La première étape consiste à vérifier si un document contient une ou plusieurs entités connues ou nouvelles. Si les entités sont déjà connues, il est vérifié si le contenu répertorie actuellement les attributs non associés à l'entité. Si ceux-ci sont considérés comme appropriés, l'entité déjà stockée est mise à jour avec les nouveaux attributs.
Lorsque de nouvelles entités potentielles sont découvertes, elles sont placées dans le contexte du contenu. Afin de classer l'entité précédemment inconnue en une ou plusieurs classes d'entités, une recherche est effectuée dans le contenu pour les entités connues qui possèdent des attributs similaires ou apparaissent adjacentes. Le contexte et les classes d'entités ou leurs attributs donnent une image plus claire du contexte sémantique de la nouvelle entité.
Une notation de relation peut être utilisée pour déterminer une affiliation hiérarchique à une classe.
Cela peut ensuite être stocké dans le graphique, y compris les premiers attributs, les relations avec d'autres entités et les classes ou types d'entités.
Le brevet a été mis à jour en février 2019 et est valable jusqu'en 2037, ce qui indique que Google travaille avec ce dernier.
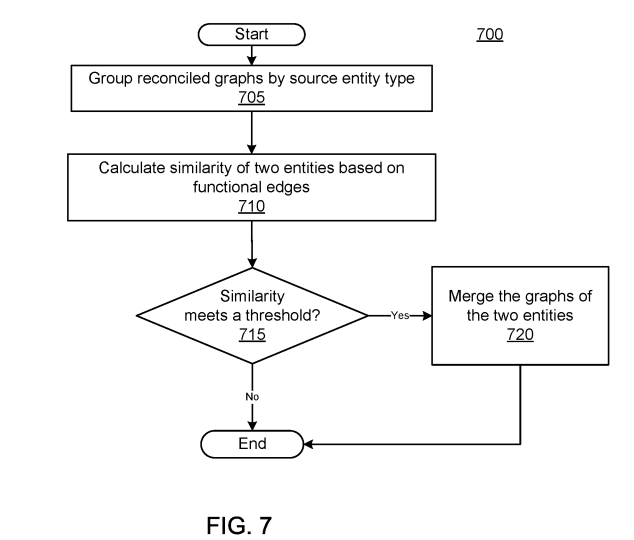
Source: Google Patent – Découverte automatique de nouvelles entités par rapprochement de graphes, US10331706
Un autre brevet Google 2019 intitulé "Découverte automatique de nouvelles entités à l'aide de la réconciliation de graphes" décrit une autre méthode d'extraction et de vérification de nouvelles entités, y compris des attributs et des types de relation, à partir de sources en ligne non structurées.
La méthode décrit comment Google pourrait extraire des graphiques d'entités individuelles à partir d'entités soumises, d'objets et d'expressions de prédicats découverts à partir du contenu du site. Ces graphiques individuels sont regroupés par type d’entité afin de mieux les comparer.
En comparant les différents graphiques d'entité, les faits peuvent être vérifiés. Les nuplets ou les faits, qui apparaissent souvent dans les graphiques individuels, sont plus crédibles que les faits qui ne se produisent qu'occasionnellement. Dès que le nombre d'entrées identiquement identiques dépasse un seuil, elles sont vérifiées comme étant correctes. Tous les faits vérifiés concernant l'entité sont fusionnés dans un nouveau graphe d'entité et stockés dans le graphe de connaissances.
Reconnaissance d'entité nommée
Reconnaissance des entités nommées (pour en savoir plus sur Qu'est-ce qu'une entité?) Dans les phrases, les paragraphes et les textes entiers, il s'agit de la toute première étape du processus de génération d'informations pour un graphe de connaissance. La méthode la plus courante est l’apprentissage automatique supervisé et semi-supervisé. L'apprentissage automatique assisté en machine peut fournir une valeur acceptable en termes de degré de complétude des entités dans un graphe de connaissances, mesuré par rapport à la totalité des entités. Les meilleures données de formation pour les entités d'une ontologie particulière, par ex. Les gens, les organisations, les événements … commentés ou marqués sont le meilleur résultat. Ce prix est le support manuel de l'algorithme. Des expériences scientifiques ont montré qu'un ensemble de semences de seulement 10 faits saisis manuellement avec un corpus de plusieurs millions de documents peut donner une précision de 88%.
Pour la reconnaissance des entités nommées, des caractéristiques typiques telles que, par exemple, Partie du discours (nom, objet, sujet) ou co-compétitions avec aide spécifique.
Ainsi, une entité de la classe acteur est souvent associée à des phrases telles que celle qui a remporté le Golde Globe, est une star de cinéma, est nominée pour la Golden Camera, a joué dans le film xy … appelé. En outre, les propriétés de mot telles que le type de caractère et le numéro ou la fin de mot peuvent au moins être des références à une classe d'entité, un type d'entité ou une valeur d'attribut. Ainsi, les langues se terminent généralement par "isch" ou le numéro de l’année est composé de 4 chiffres.
D'autres caractéristiques peuvent être la comparaison avec les dictionnaires de noms ou la cooccurrence avec certains termes. Ainsi, une co-concurrence immédiate avec le terme GmbH indique qu'il pourrait s'agir d'une société. Le terme combinaison "FC + ville" suggère qu'il s'agit d'un club de football.
Cependant, une propriété en soi n’est souvent ni une indication ni même une preuve. Seule la combinaison de différentes caractéristiques donne une certitude.
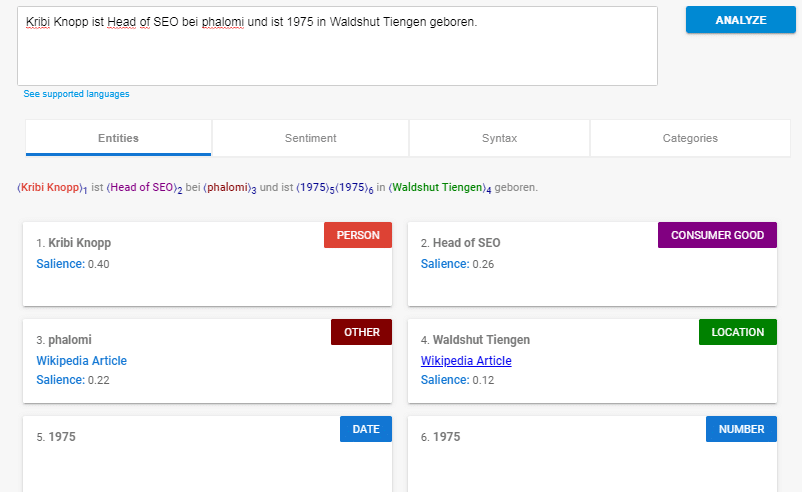
Pour expliquer un exemple de phrase:
Olaf Kopp est responsable du référencement chez Aufgesang et est né en 1975 à Waldshut Tiengen.
Les informations suivantes sont connues:
- Chef de référencement (occupation de classe d'entité)
- Waldshut Tiengen (ville de type entité)
- né (appartenant au mot naissance)
Ce n'est que sur la base de ces informations que i.a. les choses suivantes sont assez valables:
- Olaf Kopp est une entité du type entité Person
- Aufgesang est une entité de type organisation qui traite avec le référencement
- Le lieu de naissance d'Olaf Kopp est Waldshut Tiengen
- Olaf Kopp est né en 1975
- …
Si vous analysez cette phrase avec l'API en langage naturel, vous obtiendrez ce qui suit:
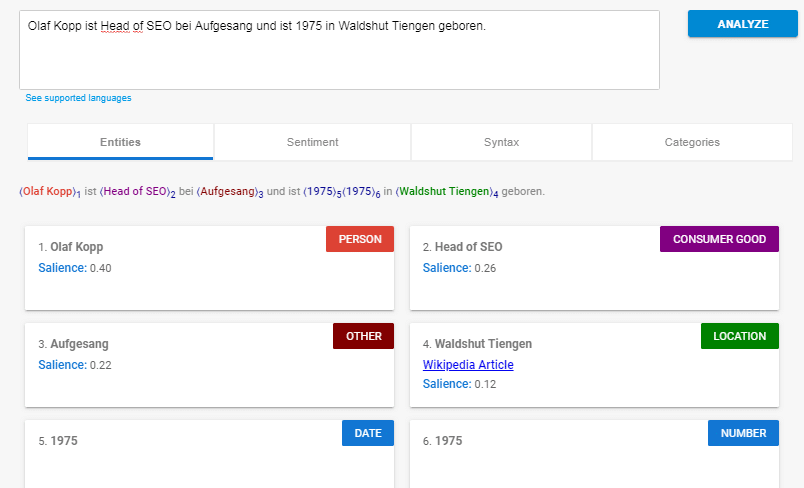
Source: https://cloud.google.com/natural-language/
Google reconnaît en tant qu'entités:
- Olaf Kopp (personne)
- Responsable SEO (biens de consommation)
- Aufgesang (Autre)
- Waldshut Tiengen (Lieu)
- 1975 (date / numéro)
Qu'est-ce que cela nous dit?
En raison de la sémantique de cette phrase, Google peut extraire diverses entités. Ces entités ne sont que partiellement couvertes dans le graphe de connaissances. Par exemple, une requête à l'API Knowledge Graph de l'entité indique que "chanté" n'est pas capturé en tant qu'entité.
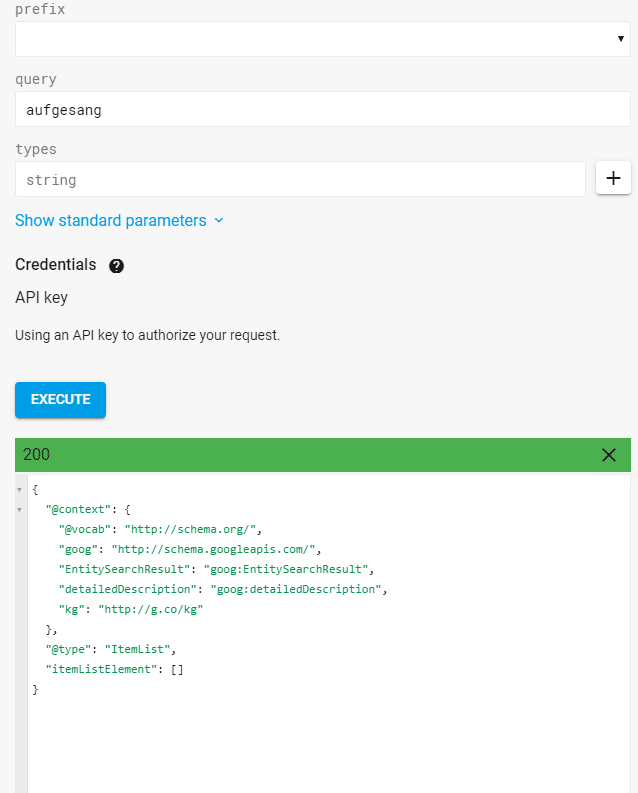
Résultat Requête pour l'entité "Aufgesang" via l'API Knowledge Graph
Google reconnaît les entités uniquement via le traitement du langage naturel (NLP) en fonction de la structure de la phrase, sans accéder à un graphe de connaissances. Je remplace, par exemple l'entité Aufgesang ou Olaf Kopp avec un terme imaginaire reconnaît néanmoins Google comme entités, ce qui corrobore cette thèse. Les termes fantastiques "kribi knopp" et "phalomi" sont des termes sans signification et non couverts dans le graphique de connaissances.
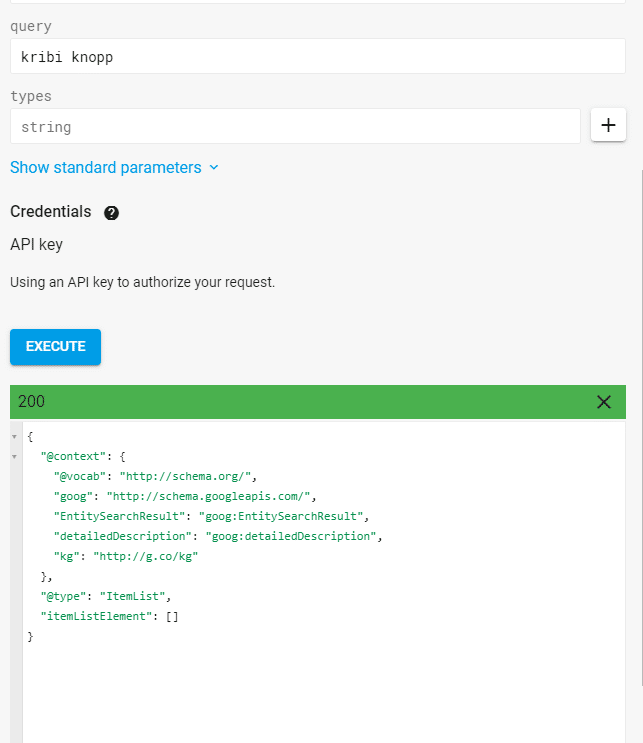
Requête de résultat pour l'entité kribi knopp "via l'API Knowledge Graph
Google ne les reconnaît que comme des entités basées sur la structure de la phrase:
Le traitement du langage naturel est une méthode importante pour détecter des entités potentielles. Même les types d'entité grossiers ou les classes peuvent être assignés à l'entité via NLP. Plus d'informations sur ce sujet et l'API de langage naturel de Google dans le prochain article de cette série.
Extraire des événements consiste à identifier les événements actuels et leur signification. En particulier pour Google Actualités et leur diffusion dans les SERP normaux ainsi que dans la détection d'événements saisonniers joue un rôle majeur.
D'une part, Google peut détecter les événements en cours au moyen d'une augmentation soudaine du nombre de recherches d'une entité et / ou d'une combinaison d'entités et de termes déclencheurs d'événements. Ou bien, Google détecte un événement sur la co-occurrence de ces fonctionnalités dans des rapports récents dans des magazines d'actualité, des blogs …
Les événements et les entités sont étroitement liés. Les entités sont souvent des acteurs ou des participants à des événements ou des événements, et les événements sans entités sont rares. L'interprétation des événements et des entités dépend fortement du contexte. Pour cette raison, les méthodes modernes d'interprétation des événements sont toujours basées sur les entités immédiatement mentionnées et les termes de déclenchement d'événements typiques. De tels termes de déclenchement peuvent par exemple ses "tirs", "bombes", "morts", "attaques", "victoires", "gagnés", tremblements de terre "," catastrophes "…
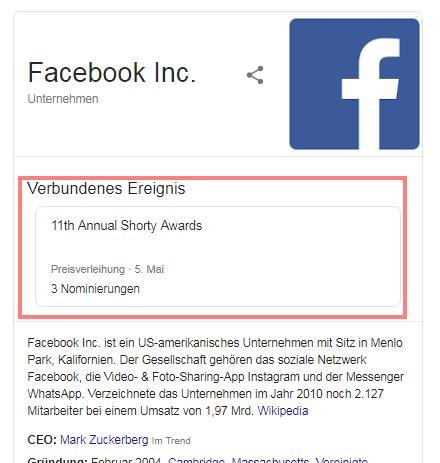
Voici un exemple d'événement lié à l'entité Facebook sur Google:
Apprentissage automatique en tant que technologie centrale pour le traitement de données non structurées
Une technologie centrale pour l'extraction de l'information et le traitement du langage naturel est l'apprentissage automatique sous diverses formes. Plus dans l'article Importance de Machine Learning, AI et Rankbrain pour le référencement et Google.
Les tâches principales du traitement des sources de données non structurées incluent, sans toutefois s’y limiter:
- Extraire des informations de sites Web
- Reconnaissance de reconnaissance d'entités nommées
- Extraire les relations (extraction de relation)
- Extraction d'événements (Extraction d'événements)
- Détection et extraction de types et de classes et affectation d'entités
Pour affiner la tâche et la formation, des méthodes telles que, par exemple, Lemmatisation et décomposition composite appliquées.
Affectation de nouvelles entités à des classes et à des types via un apprentissage automatique non supervisé
La mise en cluster est une méthode permettant de mettre en contexte des entités précédemment inconnues ou de les affecter à des classes d'entité ou à des types d'entité. Cela peut être fait à l'aide d'algorithmes d'apprentissage automatique non supervisé.
Dans ce contexte, les termes reconnus comme des entités potentielles dans un texte sont affectés à des types ou à des classes en ce qui concerne l'environnement des termes indirect ou immédiat dans lequel ils sont appelés. Cela est effectué en comparant les modèles de co-occurrence identifiés par l'algorithme pour certaines classes à partir de l'analyse. À cette fin, on peut également utiliser des analyses spatiales vectorielles dans lesquelles l'angle des vecteurs est déterminé en fonction de la proximité des termes avec l'entité recherchée.
En utilisant cette méthode, des entités précédemment non reconnues peuvent être identifiées. Donc on pourrait par exemple à partir d'un flux de messages tels que Google Actualités introduit les co-créations d'entités nommées déjà identifiées dans un contexte thématique avec des entités potentielles auparavant inconnues et attribue automatiquement des types et des classes.
La chose complexe ici est de trouver un seuil correspondant auquel une entité ressemble tellement ou se rapproche tellement d'une autre (par exemple, dans un espace vectoriel -> incorporation de mots) jusqu'à ce qu'elle soit considérée par Google comme un membre. L'utilisation d'un seuil généraliste est également improbable et peut même être aussi granulaire que des entités. Philip Ehring, ingénieur de données / scientifique dans l’équipe d’exploration de texte d’Otto Business Intelligence.
Si par exemple une marque de voiture neuve jusqu'alors inconnue est mentionnée à maintes reprises dans l'actualité aux côtés d'entités connues telles que VW, Mercedes et Toyota, il est évident qu'il s'agit de la catégorie Entity ou du type constructeur automobile et associent ainsi cette nouvelle entité aux attributs communs pour cette classe. peut être amené. Cela peut également modifier les modèles pour la validation et les seuils de nouvelles entités.
Méthodes pour assurer la ponctualité
La mise à jour n'est pas un gros problème pour certaines entités et certains concepts car les faits ou les attributs n'ont pas changé depuis des décennies ou des siècles, tels que bâtiments, événements du passé, personnalités historiques … Mais il existe des entités en constante évolution, telles que personnes actuellement vivantes, bureaux politiques …
Ici peut soi-disant Systèmes d'accélération de la base de connaissances court systèmes KBA permettre une mise à jour rapide des enregistrements.
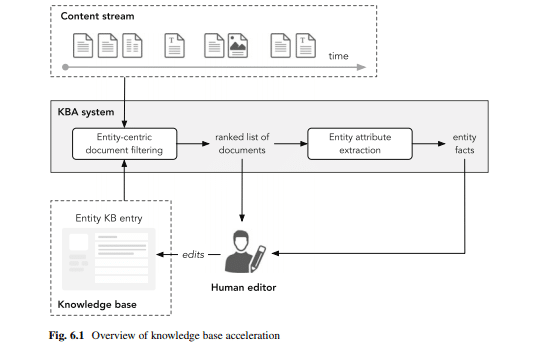
Source: Recherche par entité par Krisztian Balog
A partir d'un flux de contenu cohérent de contenu référençable nouvellement publié, tel que: Les articles de presse, les articles de blog ou les tweets sont importés dans un système KBA pour une analyse en temps réel du contenu lié à l'entité. Ces documents sont soit directement transmis aux éditeurs de la base de données, soit les faits sont extraits, puis transmis aux éditeurs.
Bien que l'identification des documents pertinents soit un processus simple de récupération d'informations par nom d'entité, y compris les synonymes, le processus d'extraction automatisé est un peu plus complexe.
Voici la méthodologie de Extraction d'informations fermée être utilisé. Cette méthodologie se limite à détecter les changements dans les faits des enregistrements déjà collectés.
À la Extraction d'informations fermée peut être démarré hiérarchiquement de haut en bas, c'est-à-dire en commençant par la classe sémantique ou le type d'entité avec l'extension ou la mise à jour ou inversement du bas en haut en commençant par l'entité.
Le brevet Google Extraction d'informations d'un texte non structuré à l'aide de modèles d'extraction généralisés décrit une méthode permettant de développer en continu une base de données avec de nouvelles informations à partir de textes non structurés basées sur des faits de base extraits de phrases individuelles. Le brevet n'est pas décrit en termes d'entités mais peut également être utilisé pour compléter les attributs et les relations d'entités.
abstrait
L'invention concerne des procédés, des systèmes et des appareils, y compris des produits de programme informatique, permettant d'extraire des informations d'un texte non structuré. Les paires de faits sont utilisées pour extraire des modèles de base d'un corps de texte. Les modèles sont généralisés en remplaçant les mots par des classes de mots similaires. Des modèles généralisés sont utilisés pour extraire d'autres faits du corps du texte. Le processus peut commencer par des paires de faits, des modèles de base ou des modèles généralisés.
Le coffre du savoir en tant que graphe de connaissances 2.0
La base de connaissances est une base de connaissances qui combine des extractions de contenu Web (analyse de texte, de tableaux, de structures et d'annotations humaines via Json-LD, Microdata, par exemple) et des informations provenant de bases de connaissances existantes telles que Wikidata, YAGO, DBpedia, etc.
De nombreuses personnes ont émis l'hypothèse que le coffre-fort de connaissances de Google remplacera éventuellement le graphe de connaissances. Je vois Knowledge Vault comme Knowledge Graph 2.0.
Knowledge Vault utilise des sources de données structurées telles que Wikidata (anciennement Freebase), des sources de données semi-structurées telles que Wikipedia, ainsi que du contenu Web non structuré pour extraire les informations. Via un module de fusion, ces données sont fusionnées et traitées via un apprentissage automatique supervisé, puis transférées vers Knowledge Graph / Knowledge Vault.
Alors que les graphes traditionnels de Knowlede tirent principalement des informations uniquement de sources de données structurées ou au moins semi-structurées, Knowledge Vault est capable de traiter les informations de manière évolutive, indépendamment des informations stockées à la main. Un extrait de l'article scientifique Knowledge Vault: Une approche Web de la fusion probabiliste des connaissances.
Ici, nous présentons Knowledge Vault, une base de connaissances probabiliste à l'échelle Web qui combine des extraits de contenu Web (obtenus via l'analyse de texte, de données tabulaires, de structure de page et d'annotations humaines) avec des connaissances antérieures issues des référentiels de connaissances existants. Nous employons des méthodes d'apprentissage automatique supervisées pour fusionner ces sources d'informations distinctes. Le référentiel de connaissances est plus récent que tout référentiel de connaissances structuré précédemment publié et dispose d'un système d'inférence probabiliste qui calcule les probabilités calibrées de l'exactitude des faits.
La base de connaissances est en cours de développement en raison de la croissance des sources de données gérées par l'homme, telles que les ressources humaines. Wikipedia doit stagner et de nouvelles sources d’information doivent être exploitées afin d’atteindre l’objectif d’une base de connaissances presque complète, sans pour autant sacrifier la validité de l’information.
Par conséquent, nous croyons qu'une nouvelle approche est nécessaire. Rechercher une approche doit automatiquement extraire des faits de l’ensemble du Web, afin d’accroître les connaissances que nous collectons à partir de sources humaines et de sources de données structurées. Malheureusement, les méthodes standard pour cette tâche (cf. (44)) produisent souvent des faits très bruyants et peu fiables. Pour que les données soient lues automatiquement, la nouvelle approche doit être automatiquement utilisée. Source: https://www.cs.ubc.ca/~murphyk/Papers/kv-kdd14.pdf
Ainsi, la base de connaissances suit le principe de l'extraction ouverte.
L'algorithme de classement des chemins permet des modèles de relation typiques entre les entités dans des sources de données structurées, telles que Wikidata être identifié. Ainsi, par exemple Les entités associées au prédicat "marié à" sont souvent liées à la valeur parent du parent avec d'autres entités, et inversement. Ces relations communes peuvent ensuite être capturées sous forme de règles.
Knowledge Vault peut déterminer si les informations sont corrélées et comment la source détermine si les informations sont correctes ou non. De plus, la base de connaissances est bien plus vaste que les bases de données de connaissances traditionnelles en raison de l'extraction ouverte automatisée.
Pour créer un graphique de connaissances de cette taille, les faits sont extraits de diverses sources, notamment des données Web, notamment du texte libre, des arborescences DOM HTML, des tableaux Web HTML et des annotations humaines dans les pages Web. Les notes humaines sont via JSon-LD, schema.org … un excellent contenu.
Knowledge Vault se compose de trois composants principaux:
- : extracteurs Ce composant extrait les triplets ou déclarations RDF susmentionnés de l'objet, du prédicat et du sujet à partir de documents librement disponibles, en leur fournissant un indice de confiance permettant de mesurer la crédibilité des triples.
- Priors basés sur des graphiques: Ce composant vérifie la probabilité que cette instruction soit pertinente en raison de la fréquence des triplets RDF existants dans la base de données.
- Connaissance Fusion: sur la base des informations des étapes précédentes, il vérifie si l'instruction est correcte et stockée dans le graphe de connaissances ou non.
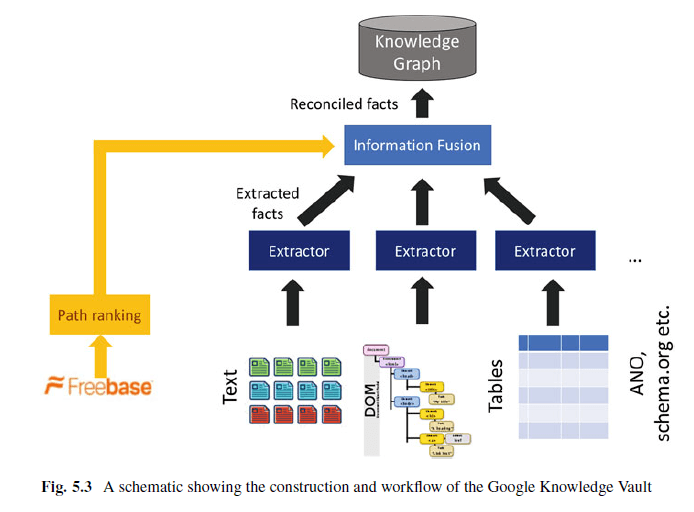
Source: Construction d'un graphe de connaissances spécifique à un domaine par Mayank Kejriwal
Les approches et méthodes d'extraction d'informations non structurées pour le graphe de connaissances décrit dans cet article sont déjà utilisées et le coffre-fort de connaissances joue ici un rôle central. Dans quelle mesure ils sont déjà utilisés reste la spéculation.
Toutefois, la pratique montre que jusqu'à présent, Google n'a qu'un accès très limité aux informations non structurées, du moins jusqu'à la diffusion dans les Knowledge Panels. Les premières applications pratiques se trouvent dans les extraits sélectionnés, bien que cela soit plus probable après l’utilisation directe de Traitement du langage naturel ressemble à après avoir utilisé le graphe de connaissances.
De plus, Google ne travaille actuellement que sur des entités non incluses précédemment dans le graphique de connaissances. PNL, pour les identifier, quel que soit le graphe de connaissances. Pour l’identification des entités et la classification thématique, le traitement du langage naturel sert bien. Cependant, cela ne garantirait que le critère de complétude, le cas échéant, d’actualité. La PNL à elle seule ne garantit pas la justesse.
Je pense que Google maîtrise assez bien le traitement du langage naturel, mais il n'obtient pas de résultats satisfaisants pour l'évaluation des informations extraites automatiquement. Ce sera probablement la raison pour laquelle Google agit toujours avec prudence, en ce qui concerne le positionnement direct dans les SERPs.
C'est pourquoi, dans le prochain article, je voudrais traiter plus en détail de la PNL et du traitement automatique du langage dans les recherches.
Crédits: Les liens vers les instructions pour les astuces de nerd proviennent de Philip Ehring, Bibliothécaire formé et étudié, Philip travaille dans le domaine de la sémantique, de la recherche d'informations et de l'apprentissage automatique en tant qu'ingénieur de données / scientifique de données au sein de l'équipe d'exploration de texte d'Otto Business Intelligence. L’évaluation pratique de Google et des différents composants du moteur de recherche en vue de son optimisation fait partie intégrante de sa carrière depuis son stage à Aufgesang.