Sommaire
Il existe peu d'informations sur les éléments importants du graphe de connaissances Google, tels que les types d'entité, les classes et les attributs, ainsi que sur l'analyse des relations entre ces éléments. Une raison plus dans le contexte de ma série d'articles sur l'optimisation des moteurs de recherche sémantiques pour répondre.
Du catalogue d'entités au graphe de connaissances
Le graphe de connaissances est basé sur trois niveaux:
- Le catalogue des entités: Toutes les entités qui ont été identifiées au fil du temps sont stockées ici.
- Référentiel de connaissances: Les entités sont fusionnées dans un référentiel de connaissances avec les informations ou les attributs des différentes sources. Le référentiel de connaissances concerne principalement la fusion et le stockage de descriptions et la formation de classes ou de groupes sémantiques sous la forme de types d'entité. Le référentiel de connaissances de Google est actuellement le Coffre de connaissances,
- Graphique de connaissancesLe graphe de connaissances ajoute des attributs aux entités et établit des relations entre les entités.
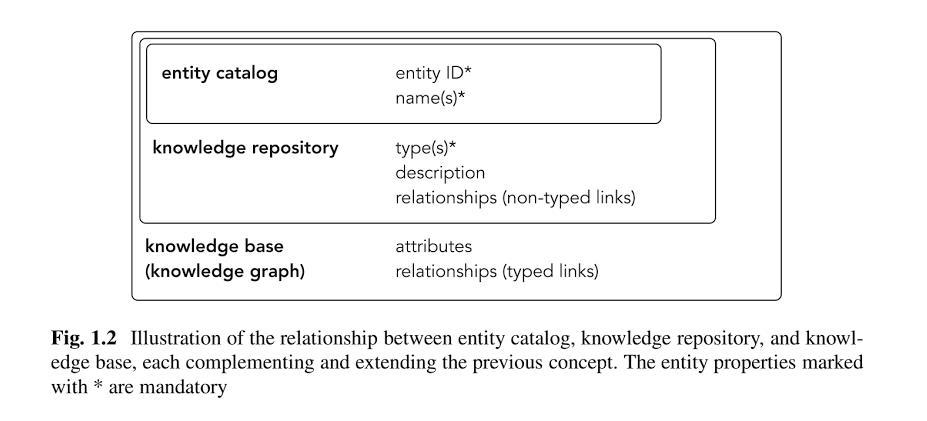
Source: Recherche axée sur les entités – Krisztian Balog
Que sont les attributs d'entité?
Les attributs décrivent les propriétés d'une entité. Dans Wikidata, ces attributs sont sous témoigner résumé. Donc, il y a l'entité Larry Page u.a. les attributs suivants sont attribués:
- Sexe: mâle
- Pays de nationalité: États-Unis
- Prénom: Larry
- Nom de famille: Page
- Images de Larry Page
- Date de naissance: 26 mars 1973
- Lieu de naissance: East Lansing
- Conjoint: Lucinda Southworth
- Nombre d'enfants: 2
- langue parlée ou publiée: anglais
- Activité: entrepreneur, informaticien, ingénieur
- Employeur: Google
- Fonction ou poste public: directeur général
- Membre de: Académie américaine des arts scientifiques, Académie nationale d'ingénierie
- Résidence: Palo Alto
- Actif: 30 000 000 000 dollars américains
- …
Voici à quoi ressemble l'enregistrement dans Wikidata:

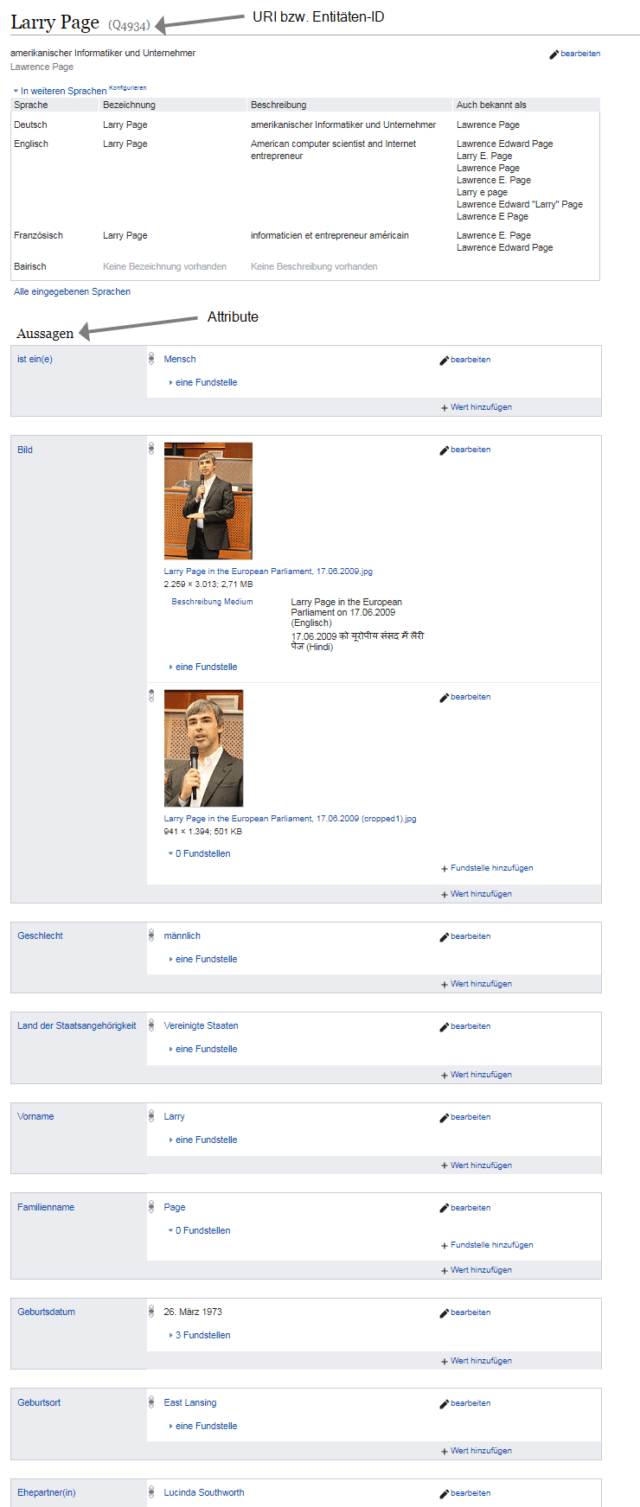
Le panneau de connaissances affiche les informations suivantes:
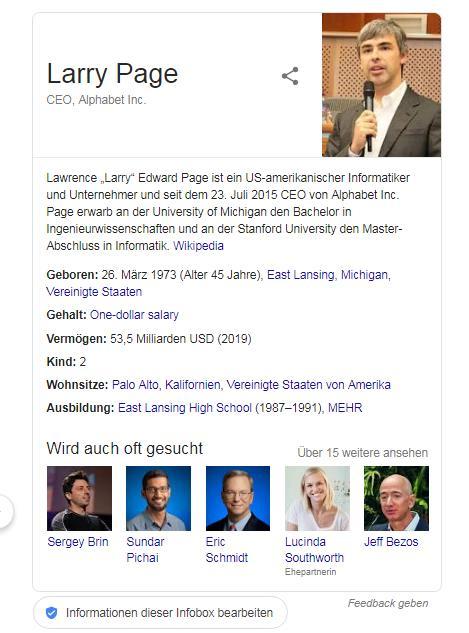
On peut constater que toutes les informations de Wikidata ne sont pas diffusées et que des informations supplémentaires, telles que Wikipedia, sont également ajoutées. Il existe également des différences telles que le salaire, bien que dans la Wikidata une référence pour cette déclaration soit déposée. La formation d'attribut est jouée bien qu'aucune référence pour la vérification ne soit stockée. On peut en conclure que l’emplacement des attributs dans le panneau de connaissances n’a rien à voir avec la validation.
L'obtention de l'entité Larry Page via l'API Knowledge Graph fournit les informations suivantes:
{
"@Type": "EntitySearchResult",
"Résultat": {
"@Id": "kg: / m / 0gjpq"
"Nom": "Larry Page"
"@Type": (
« Personne »
« Chose »
)
"Description": "Directeur général de Alphabet"
"Image": {
"ContentUrl": "http://t2.gstatic.com/images?q=tbn:ANd9GcQRfAXPOVZYyyTQXdos1xYsjQx6Q6MbR4GRc9lzreCuMHevp1NT",
"URL": "https://commons.wikimedia.org/wiki/File:Larry_Page_laughs.jpg"
},
"URL": "http://www.google.com/corporate/execs.html"
},
"ResultScore": 676.908813
},
Seuls le nom, la description, l'ID de graphe de connaissances, une source d'image et un lien vers une source Google officielle sont indiqués.
Le score de résultat représente la proximité ou la correspondance de l'entité avec la requête de recherche dans l'API Knowledge Graph et décide des noms d'entités ambigus pour lesquels Knowledge Panel est priorisé pour les requêtes relatives à l'entité. Donc, il y a aussi une entité Larry Page, qui représente un chanteur. Mais cela a seulement un résultat inférieur.
Quelles sont les sources pour les attributs?
Les informations sur les entités et leurs relations entre elles peuvent être obtenues de Google à partir des sources suivantes:
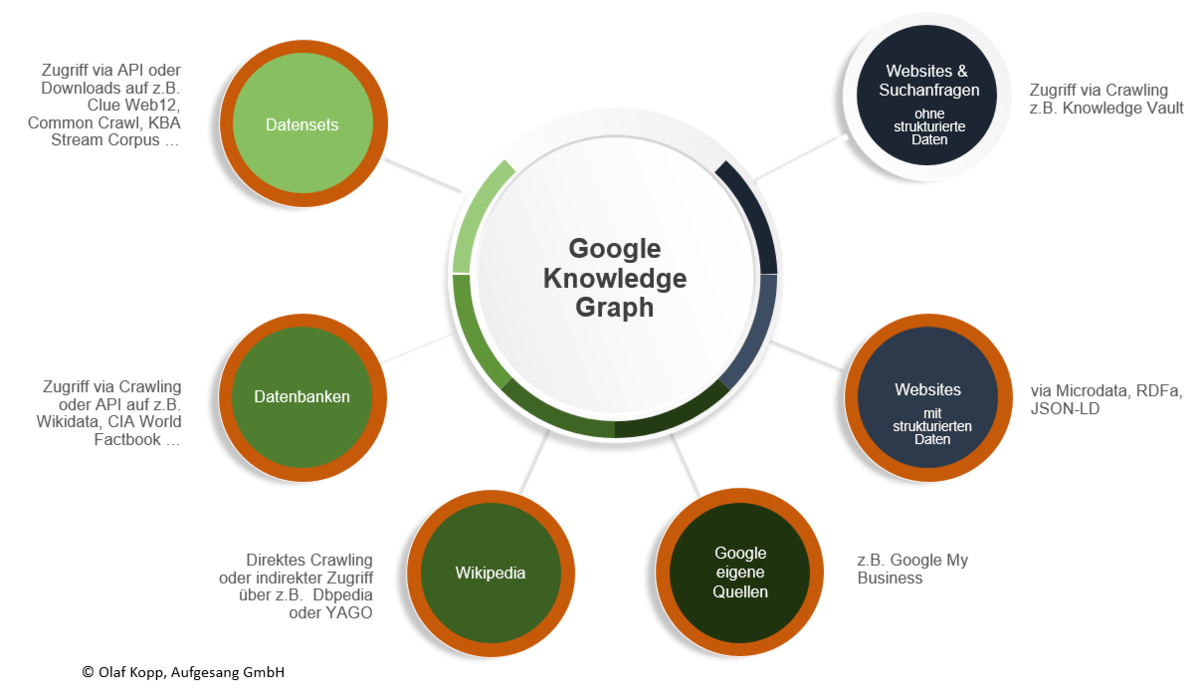
Sources de données pour le graphe de connaissances
Sources de données non structurées
Sources à partir desquelles Google peut extraire des informations théoriques non structurées sur les entités
- Pages Web normales via l'exploration
- recherches
- bases de données et ensembles de données non structurés
La base de connaissances joue ici un rôle particulier. Dans une contribution de suivi plus.
Sources pour données semi-structurées
Des informations semi-structurées peuvent être récupérées à partir d'encyclopédies telles que Google. Wikipedia, qui ont une structure systématique. J'y reviendrai plus en détail dans une contribution de suivi.
Sources de données structurées
À l'aide de bases de données sémantiques et d'ensembles de données, Google peut fournir directement des données structurées, par exemple. via API et utilisation pour le graphe de connaissances. Les bases de données suivantes sont possibles:
- Wikidata (anciennement Freebase)
- Google My Business
- CIA World Factbook
- DBpedia
- YAGO
- Sites Web contenant des données structurées via Microdata, RDFa et JSON-LD
- Données sous licence
- CIA World Factbook
- ensembles de données
Le traitement des données structurées pour le graphe de connaissances
Le numéro un des contacts de Google pour obtenir des informations sur les entités est les sources qui fournissent des données structurées.
Dans ce post, je ne traiterai que de ces types de sources de données. Pour la méthodologie beaucoup plus complexe, les données non structurées et les données semi-structurées telles que, par exemple, pour extraire de Wikipedia, je vais aller dans des contributions ultérieures.
Les données structurées peuvent Google grâce à la structure de description de ressources brièvement capturer RDF. Une entité est un résumé de diverses instructions RDF en fonction du sujet du prédicat de l'objet modèle. Une déclaration serait par exemple "Canberra est la capitale de l'Australie."

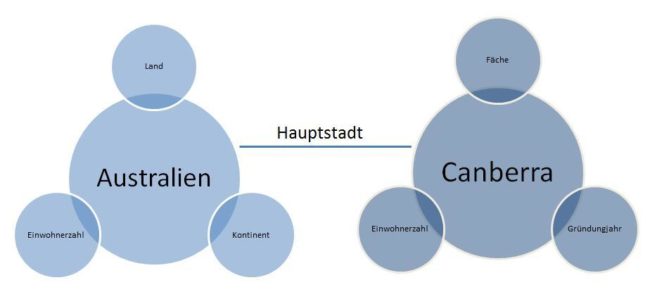
On peut aussi représenter cette connexion en termes grammaticaux. Canberra est-ce sujet, Australie que propriété et (est) la capitale est que prédicat, Le type de relation peut également être décrit par un verbe du type "Thomas Müller joue pour Bayern Munich. "Objet et sujet sont donc toujours des entités. Le prédicat peut être un type d'entité ou une classe, un attribut, un verbe ou une combinaison de tous.
La plupart des bases de données structurées fournissent les informations au format RDF lisible par machine ou permettent la traduction dans ce format. Google accède à des bases de données en lesquelles ils ont confiance, telles que Wikidata, CIA World Factbook …, des ensembles de données structurés ou des bases de données de traduction telles que DBpedia ou YAGO traduisant les informations de Wikipedia en données lisibles par machine.
Étant donné que les bases de données et les ensembles de données contenant des données structurées grandissent et se mettent à jour assez lentement, il n’est pas surprenant que les webmasters de Google les incitent constamment à utiliser des données structurées sur leurs sites Web. Plus Google collecte et traite des données structurées, plus il se rapproche du traitement de données non structurées. Les données structurées fonctionnent comme des données d'apprentissage pour l'apprentissage automatique.
Pour en savoir plus sur ma contribution, pourquoi les données structurées pour Google pourraient-elles devenir redondantes à l’avenir.
Que sont les types d'entité et les classes d'entité?
Dans divers brevets Google, vous pouvez trouver les termes types d'entité et classe d'entité. Certains types d'entités et classes d'entités possèdent un ensemble d'attributs similaire, formant un groupe. Par exemple, la classe d'entité peut-elle "personne"Ou"homme"Toujours des attributs comme lieu de naissance. résidence. date de naissance … sont assignés. Ceci définit clairement le type d'entité.
Un type d'entité et une classe d'entités décrivent un groupe d'entités pouvant être décrites à l'aide d'attributs similaires. Dans l'exemple ci-dessus de Larry Page, un type d'entité pourrait être PDG ou Entrepreneur.
Dans le très bon livre Recherche par entité de Krisztian Balog, vous trouverez la description suivante pour les types d’entité:
Les entités peuvent être classées en plusieurs types d’entités (ou types en abrégé). Les types peuvent donc être considérés comme des conteneurs (catégories sémantiques). Une analogie peut être faite avec la programmation orientée objet, qui est une entité d'un type.
Je ne pouvais pas savoir exactement où se situe la différence entre les types d'entité et les classes d'entités. Je suppose que la classe d'entités est une forme de groupement légèrement plus grossière, alors que les types d'entités sont définis plus clairement.
Relation entre les classes d'entités dans les ontologies
Il existe des bases de données telles que Les ontologies YAGO ou DBpedia, qui représentent respectivement les relations entre les classes d'entités et les types d'entités. Chez DBpedia Ontology, la base est Wikipedia. Dans l'extrait suivant de DBpedia Ontology, les types d'entité (rectangles arrondis) sont liés aux classes d'entité parent via des flèches ascendantes. Par exemple, Les types d'entité Athlètes et Coureurs sont affectés à la classe d'entités "Personne". Les attributs de type et de liaison de classe sont indiqués par les flèches en pointillés.
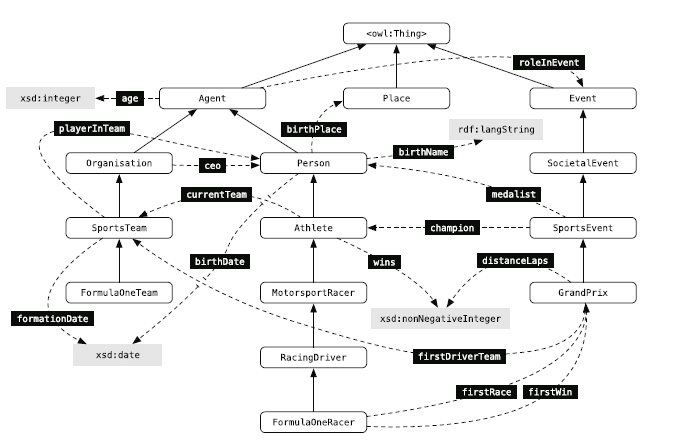
Extrait de DBpedia Ontology; Source: Recherche axée sur les entités – Krisztian Balog
Le tout représente alors une ontologie décrivant les relations entre les classes, les types et donc les entités.
Quelle est la pertinence d'un attribut pour une entité, un type d'entité ou une classe?
En pondérant les attributs par entité, Google peut déterminer la pertinence d'un attribut donné pour une entité. D'autre part, Google pourrait également déterminer la pertinence de l'entité pour une requête demandée pour cet attribut.
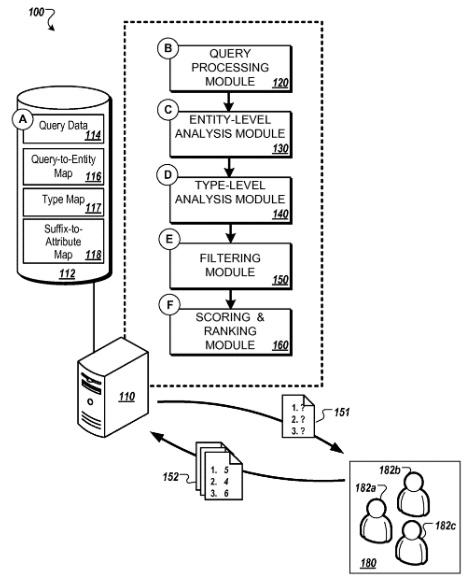
Sources: Brevet Google US9047278B1
Le brevet Google Identifier et classer les attributs d'entités montre comment cela pourrait fonctionner.
Selon ce brevet, des attributs peuvent être attribués et pondérés via les entrées de certaines combinaisons de termes de recherche.
Un aspect innovant du sujet décrit dans cette spécification est intégré dans des procédés qui incluent les actions consistant à: identifier des requêtes dans des données de requête; déterminer, dans chacune des requêtes, (i) une partie descriptive de l'entité qui est destinée à une entité et (ii) un suffixe; déterminer un nombre de fois où une ou plusieurs requêtes ont été soumises; estimer, sur la base du nombre, niveau au niveau de l'entité, le nombre de soumissions de requêtes qui incluent le suffixe particulier et sont considérées comme faisant référence à une première entité; déterminer que l'entité est un type particulier d'entité; déterminer un nombre de niveaux de type des soumissions de requête qui incluent le premier suffixe et dont on estime qu'ils font référence à des entités du type particulier d'entité; et attribuer un score au suffixe particulier en fonction du nombre d'entités et du nombre de types.
Google pourrait utiliser cette méthode pour spécifier quelles informations sur les entités d'un type d'entité particulier seront affichées dans le panneau de connaissances. En outre, cela pourrait être déterminé par des déclarations ambiguës, attribut le plus pertinent. Relatif à l'exemple ci-dessus.
Voici un exemple:
Larry Page est un entrepreneur, informaticien et ingénieur. Laquelle de ces trois déclarations est la plus pertinente?
Plus les gens recherchent "Larry Page Entrepreneurs", plus l'attribut "Entrepreneur" est approprié.
D'après les recherches et les réflexions sur ce billet, je me suis rendu compte que le plus grand défi de Google avec le graphe de connaissances consiste à extraire des informations ou des attributs concernant les entités, les types d'entités et les classes directement à partir de sources de données non structurées. Le graphique de connaissances est actuellement très fragmenté car les informations provenant des sources de données structurées mentionnées sont très incomplètes en ce qui concerne le nombre total d’entités dans le monde réel.
C'est pourquoi je souhaiterais examiner de plus près le sujet de l'extraction d'informations pour le graphe de connaissances dans les contributions suivantes à cette série de contributions.