Sommaire
Il s’agit de la quatrième partie d’une série de publications sur le référencement sémantique et aborde la question de savoir si Google comprend vraiment le sens des documents et des requêtes de recherche, ou s’il ne s'agit que d’une analyse statistique.
La compréhension sémantique comme objectif de Google
L'un des objectifs clés de Google a longtemps été d'acquérir une compréhension sémantique des termes de recherche et des documents indexés afin d'afficher des résultats de recherche plus pertinents. Une compréhension sémantique est donnée lorsque, par exemple comprendre clairement une question posée et les termes qui y figurent ou en reconnaître clairement la signification. L’interprétation claire est souvent compliquée par l’ambiguïté des termes, une terminologie auparavant inconnue, une formulation mal définie, une compréhension individuelle, etc.
Pour une meilleure compréhension, les mots utilisés, leur ordre ou le contexte thématique, temporel ou géographique peuvent y contribuer. En apprenant à la machine comme par exemple Chez Rankbrain, Google est désormais en mesure d'identifier rapidement les termes et les entités dans les requêtes de recherche et les documents, et de créer automatiquement de nouvelles classes de types d'entité via l'analyse de cluster. La création de nouveaux espaces vectoriels pour les analyses d'espace vectoriel est également possible. En outre, dans d'autres contributions de cette ligne cependant plus.
Cela garantit un niveau élevé de détails ainsi que l'évolutivité et les performances.
Ainsi, les statistiques associées à l'apprentissage automatique conduisent de plus en plus à une interprétation sémantique très proche d'une compréhension sémantique des requêtes de recherche et des documents. Google veut une recherche sémantique à l'aide de méthodes statistiques et d'apprentissage automatique "reconstruire».
En outre, un élément central du moteur de recherche Google actuel, le Knowledge Graph, repose sur des structures sémantiques.
Le chemin de Google vers la recherche sémantique
Google utilise la recherche sémantique sur le Graphique de connaissances et introduit en 2013 Mise à jour colibricela a ouvert la voie à la recherche sémantique. Mais l'intérêt de Google pour le développement d'un moteur de recherche sémantique remonte à plus de 10 ans. Déjà en 2007, Marissa Mayer, alors responsable de la recherche et de l'expérience utilisateur, avait commenté dans une interview avec IDG News Service:
"En ce moment, Google est vraiment bon avec les mots-clés et c'est une limitation. Les gens devraient être capables de comprendre leur signification ou de pouvoir parler de choses à un niveau conceptuel. Nous voyons beaucoup de questions basées sur des concepts – non pas sur les mots qui apparaîtront sur la page, mais plutôt comme 'qu'est-ce que c'est?'. Beaucoup de gens veulent utiliser le Web sémantique pour y répondre. "Source: http://www.infoworld.com/article/2642023/database/google-wants-your-phonemes.html
Dans la même interview, Marissa Mayer a également précisé que la sémantique n’était pas à la base du "moteur de recherche parfait".
"Cela dit, je pense que le meilleur algorithme de recherche est un mélange à la fois de calcul par force brute et d’exhaustivité totale, et donc de la composante humaine qualitative."
Mais l'accent mis sur la sémantique est visible sur Google bien avant 2007. Un coup d'oeil à la recherche de brevets de Google suggère cela. Par exemple, depuis 2000, Google rédige des brevets sur l'analyse sémantique de requêtes de recherche et de documents, tels que: Identification d'unités sémantiques à partir d'une requête de recherche (2000) ou classement des documents en fonction de la distance sémantique entre les termes d'un document (2004).
On peut supposer que Google s'occupe du développement d'un moteur de recherche influencé par la sémantique depuis sa création en 1998.
La première annonce officielle de Google concernant l'utilisation de technologies de type sémantique a été faite en 2009. Une recherche complètement sémantique n'a pas été possible en raison du manque de modularité. Une analyse sémantique des documents compromettrait la convivialité ou la rapidité de l'application. La sortie des résultats de recherche en temps réel n'aurait pas été possible.
Le graphe de connaissances en tant que base de données sémantique
En 2010, Google a acheté la base de connaissances Freebase, qui permettait de stocker des informations structurées sur des entités. J'aime aussi parler de Freebase comme d'un terrain de jeu grâce auquel Google a pu acquérir ses premières expériences avec des données structurées. Parallèlement, Google a développé avec le graphe de connaissances sa propre base de données sémantique.
En 2012, Google a lancé Knowledge Graph, qui incluait initialement i.a. a été alimenté par les données recueillies dans Freebase. Le projet ouvert Freebase a pris fin en 2014 et a été transféré au projet fermé Wikidata, qui constitue aujourd'hui une source d'informations importante pour Knowledge Graph.
En plus de Wikidata renvoie Google selon leurs propres données wikipedia, le CIA World Factbook, le rampant et Traitement du langage naturel de documents, Google My Business et données sous licence, Mais plus dans un autre article en détail.
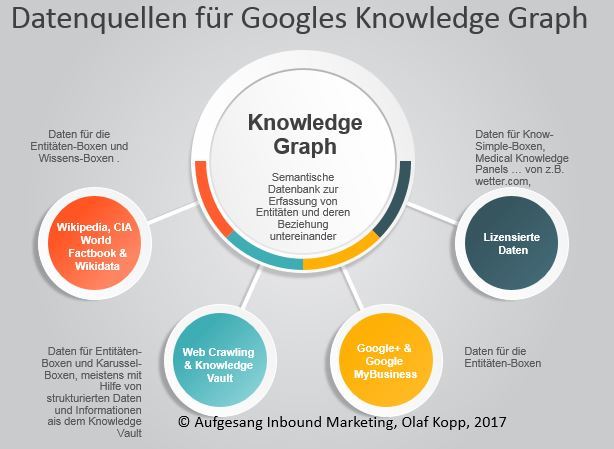
Sources de données pour le graphe de connaissances
En savoir plus sur le graphique de connaissances Google:
Qu'est-ce que le graphe de connaissances? Définition et fonctionnement
Google aujourd'hui – recherche sémantique ou récupération de données statistiques?
Que Google soit ou non vraiment un moteur de recherche sémantique de nos jours ou non est un bon argument.
Tout comme Google communique aujourd'hui les résultats aux utilisateurs, il semble que Google possède déjà une compréhension sémantique des requêtes et des documents de recherche. La manière de procéder repose en grande partie sur des méthodes statistiques. Pas sur une véritable compréhension sémantique – mais en raison de structures sémantiques combinées avec des statistiques et un apprentissage automatique, Google se rapproche d'une compréhension sémantique.
"Par exemple, nous trouvons que des relations sémantiques utiles peuvent être apprises à partir de la preuve accumulée de modèles textuels basés sur le Web et de tableaux formatés, les deux cas sans avoir besoin de données annotées manuellement." source: L'efficacité déraisonnable des données, IEEE Computer Society, 2009
Le problème principal dans le passé était le manque d’évolutivité, etc. dans la classification manuelle des requêtes de recherche. L'ancienne vice-présidente de Google, Marissa Mayer, dans une interview de 2009:
"Lorsque les gens parlent de recherche sémantique et de Web sémantique, ils veulent généralement dire quelque chose de très manuel, avec des cartes de diverses associations entre des mots et des choses du même genre. Données de correspondance de modèles, construction de systèmes à grande échelle. C'est comme ça que le cerveau fonctionne. C'est pourquoi vous avez toutes ces connexions floues, parce que le cerveau traite en permanence de très nombreuses données … Le problème est que la langue change. Les pages Web changent. La façon dont les gens s’expriment change. Et tout ce qui compte compte pour la qualité de l'application de la recherche sémantique. C'est pourquoi il est préférable d'adopter une approche basée sur l'apprentissage automatique, qui modifie, itère et répond aux données. C'est une approche plus robuste. Cela ne veut pas dire que la recherche sémantique n'a aucun rôle dans la recherche. C'est juste que pour nous, nous préférons vraiment nous concentrer sur des choses qui peuvent évoluer. Si nous pouvions trouver une solution de recherche sémantique pouvant être mise à l'échelle, nous en serions très heureux. Pour le moment, nous examinons la généralisation de l'intelligence de la recherche sémantique. "
Une grande partie de ce que nous percevons comme une compréhension sémantique dans l'identification de la signification d'une requête de recherche ou d'un document sur Google relève de la responsabilité de méthodes statistiques, telles que par exemple. analyse de l'espace vectoriel ou des méthodes statistiques textuelles, telles que TF-IDF et Traitement du langage naturel et n'est donc pas basé sur une vraie sémantique. Mais les résultats s'approchent d'une compréhension sémantique. En particulier, l’utilisation accrue de l’apprentissage automatique, par ex. L'analyse des entités à l'aide du traitement automatique du langage naturel facilite l'interprétation sémantique des requêtes de recherche et des documents avec des analyses encore plus détaillées.
Apprentissage automatique ou apprentissage approfondi pour l'évolutivité
Pour les systèmes sémantiques, les classes et les étiquettes doivent être prédéfinies pour classifier les données. De plus, il est difficile d'identifier et de créer de nouvelles entités sans assistance manuelle. Pendant longtemps, il s’agissait uniquement de bases manuelles ou de bases de données gérées manuellement, telles que, par exemple, Wikipedia ou Wikidata possible ce que le évolutivité Personnes à mobilité réduite.
Le passage à un moteur de recherche sémantique hautes performances conduit inévitablement à un apprentissage automatique ou à des réseaux de neurones.
L'engagement de Google envers les choses Intelligence artificielle et Machine Learning a débuté en 2011 avant la sortie de Hummingbird et du Knowledge Graph avec le lancement de "Google Brain".
L'objectif de Google Brain est de créer vos propres réseaux de neurones. Depuis lors, Google travaille avec un logiciel d’apprentissage en profondeur auto-développé. DistBelief et le successeur nommé Flux tensoriel et le Moteur d'apprentissage Google Cloud Machine sur l’extension de sa propre infrastructure d’apprentissage machine et en profondeur.
Selon Google, depuis 2014, Google a presque quadruplé ses activités d'apprentissage en profondeur, comme le montrent les diapositives de la conférence de Jeff Dean ci-dessous.
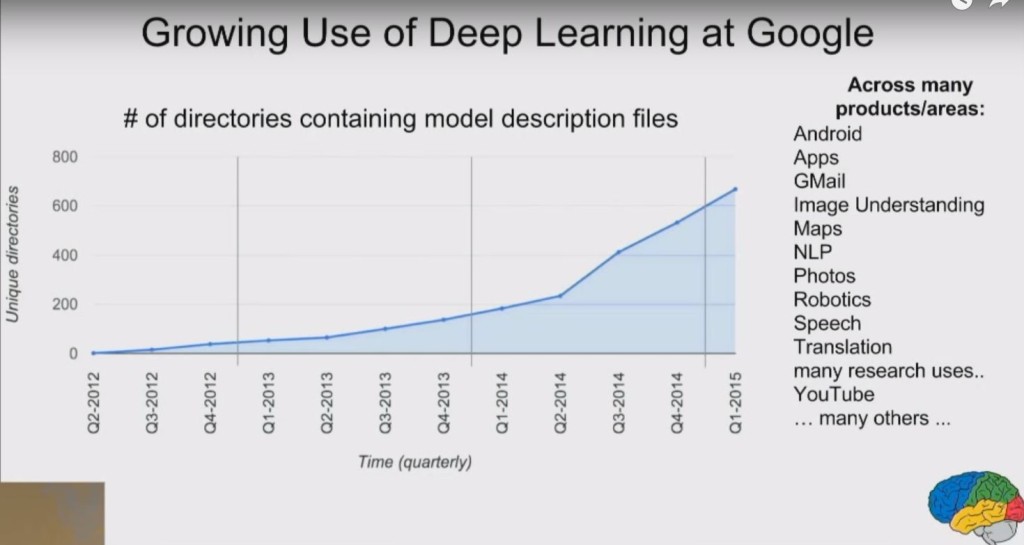
Source: Présentation Jeff Dean / Google
Jusqu'à présent, l'apprentissage automatique ou approfondi a été utilisé avec une probabilité élevée ou selon les propres déclarations de Google, dans les cas suivants:
- Catégorisation ou identification des requêtes de recherche en fonction de l'intention de recherche (Infomational, Transactional, Navigational …)
- Catégorisation du contenu / des documents par objectif (information, vente, navigation …)
- Détection, catégorisation des entités dans Knowledge Graph
- Analyse de texte via Natural Language Processing
- Détection, catégorisation et interprétation d'images
- Reconnaissance, catégorisation et interprétation du langage
- Détection, catégorisation et interprétation de vidéos
- Traduction de langues
Ce qui est vraiment nouveau, c’est que Google peut maintenant effectuer cette catégorisation de mieux en mieux, car il apprend toujours à le faire et surtout de manière automatisée.
Les portiers numériques tels que Google exigent de plus en plus des algorithmes plus fiables pour gérer ces tâches de manière autonome. Ici, les algorithmes d'autoapprentissage basés sur l'intelligence artificielle et les méthodes d'apprentissage automatique joueront un rôle de plus en plus important. Ce n'est qu'ainsi que la pertinence des résultats et / ou des dépenses / résultats escomptés sera garantie – tout en maintenant l'évolutivité.
En ce qui concerne la compréhension sémantique des requêtes de recherche et des documents, l’apprentissage automatique est un impératif de performance.
Ce n'est donc pas un hasard si les trois lancements majeurs de Google, Knowledge-Graph, Hummingbird, Rankbrain et l'important engagement de Google dans l'apprentissage automatique sur une période de trois ans sont très proches dans le temps.
En savoir plus sur le Machine Learning:
Conclusion: Google est sur la voie de la compréhension sémantique
Avec des jalons tels que Knowledge Graph, Hummingbird et Rankbrain, Google a fait un pas en avant pour devenir un moteur de recherche parfait. Ici, les statistiques, les théories sémantiques et les structures de base, ainsi que l’apprentissage automatique jouent un rôle très important.
Google souhaitait utiliser le graphe de connaissances et l'algorithme de Hummingbird pour introduire la recherche sémantique. Aujourd'hui, cependant, il devient clair que l'objectif de développement d'une compréhension sémantique a longtemps échoué en raison du manque de modularité.
La classification sémantique des informations, des documents et des requêtes de recherche dans un large éventail de requêtes de recherche et de documents est réalisable sans devoir faire d’énormes sacrifices en termes de performances – également grâce à l’aide active des SEO et des webmasters, les informations fournies. même manuellement marquer.
De plus, la capacité de faire des prédictions, ce que veut l'utilisateur quand il introduit un terme de recherche jusque-là inconnu dans la fente de recherche, n'est devenue possible que par l'apprentissage automatique.
Le chemin vers le moteur de recherche parfait est probablement encore à faire, mais les étapes sont beaucoup plus grandes depuis 2013. En raison des progrès accomplis par Google en matière d'apprentissage en profondeur au cours des dernières années, la compréhension sémantique devrait s'améliorer de manière exponentielle à l'avenir.