Sommaire
Dans cet article, je vais approfondir le traitement du langage naturel pour l'exploration de données et plus particulièrement le graphe de connaissances et les moteurs de recherche. Pour commencer, j'aimerais aborder les bases du traitement du langage naturel.
Vous pouvez trouver une collection d'articles détaillée sur Knowledge Graph, le référencement sémantique et les entités dans la série d'articles associés,
Qu'est-ce que le traitement du langage naturel?
Natural Language Processing (NLP) est un processus d'analyse et de représentation automatiques du langage humain. Natural Language Processing tente de capturer le langage naturel et de le traiter sur ordinateur à l'aide de règles et d'algorithmes. La PNL se concentre sur différents types d'apprentissage automatique Apprentissage Machine Supervisé et Apprentissage automatique non supervisé, reconnaître le contenu et la structure des textes et du langage parlé sur la base de modèles statistiques et d'analyses d'espace vectoriel. Les nouvelles approches PNL traitent également des méthodes de génération de texte et d’étiquetage via l’apprentissage par renforcement via Apprentissage supervisé semi-ou faible,
En d'autres termes Traitement du langage naturel si PNL est le processus d'analyse du texte, de création de relations entre les mots, de compréhension du sens de ces mots et d'une meilleure compréhension du sens des mots afin de générer des informations, des connaissances ou un nouveau texte
Natural Language Processing peut être utilisé pour les domaines d'application suivants:
- Reconnaissance vocale (texte à parole et parole à texte)
- Segmentation de la langue acquise précédemment en différents mots, expressions et expressions.
- Reconnaître les formes de base des mots et capturer des informations grammaticales
- Reconnaître les fonctions des mots individuels dans la phrase (sujet, verbe, objet, article, etc.)
- Extraction de la signification de phrases et de phrases telles que des phrases adjectives (par exemple trop longues), des phrases prépositionnelles (par exemple pour le fleuve) ou des phrases nominales (par exemple le parti trop long)
- Reconnaissance des contextes de phrase, des relations de phrase et des entités.
Le traitement automatique du langage peut fonctionner à la fois linguistique analyse de texte. Analyse d'humeur et d'opinion (l'analyse des sentiments) traductions ainsi que pour assistants linguistiques. chatbots et sous-jacent Système de questions et réponses être utilisé.
Processus et composants essentiels du traitement du langage naturel
En général, vous pouvez décomposer la fonctionnalité de gobe NLP en plusieurs étapes:
- Fourniture de données
- préparation des données
- analyse de texte
- enrichissement de texte
Classiquement, le processus commence par la Fourniture de données sur un corpus de texte composé de plusieurs documents. Celles-ci consistent en au moins un mot, mais principalement en plusieurs phrases. Un corpus de texte serait par exemple tous les documents pertinents sur le référencement. Les documents individuels sont composés de chapitres, de paragraphes et de phrases. Les phrases sont ensuite décomposées en jetons individuels par phrase. Voici un exemple tiré d'un article de glossaire sur le référencement:
Search Engine Optimization court SEO est l'un méthode dans le Le marketing en ligneà la découvrir la preuve en Les moteurs de recherche à améliorer, la raccourci SEO représente Optimisation du moteur de recherche, Dans le dernier Années avec Optimisation de l'expérience de recherche aussi un second sens appliquée, Dans le classique Search Engine Optimization doit entre Sur la page SEO et Off SEO page distingué,
Les jetons individuels restent dans le contexte des phrases, de sorte que les relations entre elles soient préservées. Cela préserve la relation sémantique des paragraphes, des phrases et des jetons. Dans l'étape de processus de préparation des données les jetons individuels sont dotés d'étiquettes ou d'annotations.
Le document commenté sert de base à d'autres mesures préparatoires telles que l'incorporation de texte ou la reconnaissance et l'interprétation d'entités (reconnaissance d'entité).
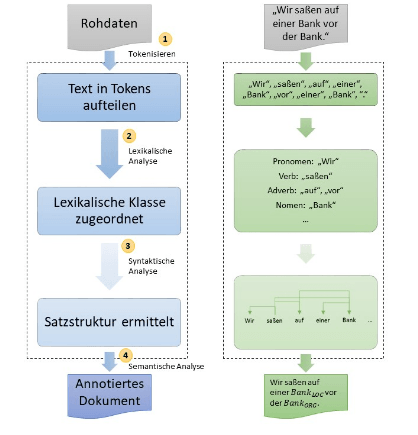
Processus de modélisation du langage; Source: http://www.datenbanken-verstehen.de/lexikon/natural-language-processing/
Ensuite, à l'étape suivante, des modèles peuvent être appliqués aux documents préparés. Ces modèles de langage sont appris à partir de données d'apprentissage automatique ou d'apprentissage. Dans cette étape du processus, les données d'apprentissage sont divisées en jetons, attribuées à une classe lexicale et les structures de phrase sont déterminées. Dans l'analyse sémantique finale, les entités sont identifiées et annotées en fonction de leur signification.
Les composants de base de la PNL sont tokenization trop allemand tokenization. Marquage des mots par partie du discours (Une partie du marquage de la parole) Lemmatisation, les dépendances de mots (Analyse de dépendance) Étiquetage parse. Extraction d'entités nommées (Reconnaissance d'entité nommée) notation de saillance. L'analyse des sentiments. catégorisation. Classification de texte. Extraction de types de contenu et Identification d'une signification implicite due à la structure,
- tokenizationLa tokénisation est le processus consistant à diviser une phrase en différents termes.
- Marquage des mots par partie du discours: Une partie de la classification de la parole classe les mots par parties de la parole telles que Sujet, objet, prédicat, adjectif …
- dépendances Word: La dépendance des mots crée des relations entre les mots en fonction de règles grammaticales. Ce processus mappe également les "sauts" entre les mots.
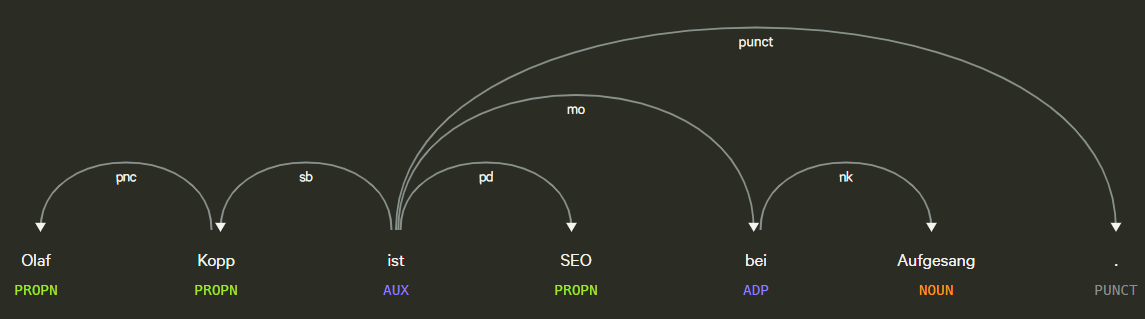
Exemple d’une partie de l’étiquetage de la parole et de l’analyse des dépendances, Source: démo Explosion.ai
- lemmatisation: La lemmatisation détermine si un mot a des formes différentes et normalise les modifications apportées à la forme de base. Par exemple, la forme de base des animaux, des animaux ou ludique est le jeu.
- Analyser les étiquettes: L'étiquette classifie la dépendance ou le type de relation entre deux mots liés par une dépendance.
- Analyse et extraction d'entités nommées: Cet aspect devrait nous être familier des contributions précédentes. Cela tente d'identifier les mots avec une signification "connue" et d'affecter des classes de types d'entités. En général, les entités nommées sont des personnes, des lieux et des choses (noms). Les entités peuvent également contenir des noms de produits. Ce sont généralement les mots qui déclenchent un panneau de connaissances. Mais même les concepts qui ne déclenchent pas leur propre panel de connaissances peuvent être une entité. Plus dans l'article Qu'est-ce qu'une entité? Que sont les entités?
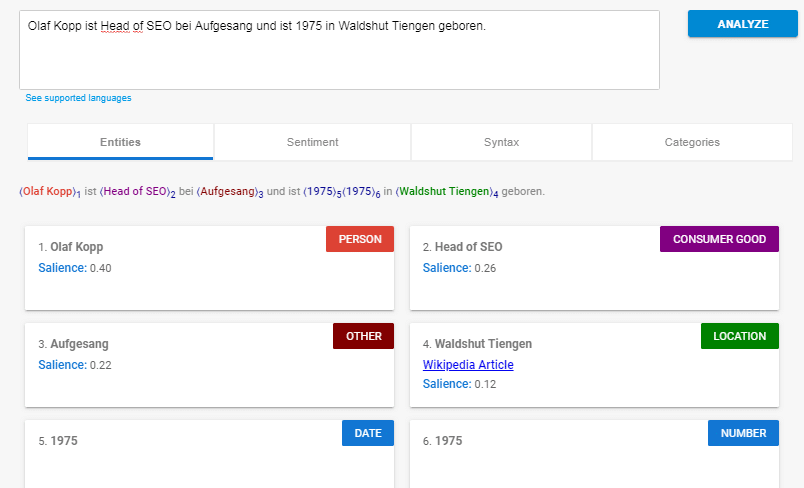
Exemple d'analyse d'entité à l'aide de l'API de traitement du langage naturel de Google.
- notation de saillance: La visibilité détermine l’intensité avec laquelle un texte traite un sujet. Ceci est déterminé dans la PNL sur la base des mots dits indicateurs. En général, la notoriété est déterminée par le partage de mots sur le Web et les relations entre les entités dans des bases de données telles que Wikipedia et Freebase. Google applique probablement également ce diagramme de liaison à l'extraction d'entités dans des documents afin de déterminer ces relations de mots. Une approche similaire est familière aux référenceurs expérimentés issus de l'analyse TF-IDF.
- Analyse des sentiments: En bref, il s’agit d’une évaluation de l’opinion exprimée dans un article (vue ou attitude) sur les entités couvertes dans le texte.
- Replier Catégorisation: Au niveau macro, la PNL classe le texte en catégories de sujets. La catégorisation des sujets permet de déterminer en général de quoi parle le texte.
- Classification et fonction du texte: La PNL peut aller plus loin et déterminer la fonction ou le but recherché du contenu.
- Extraction de types de contenu: Google peut utiliser des modèles de structure ou un contexte pour déterminer le type de contenu d'un texte particulier sans utiliser de désignation de données structurée. Le code HTML, la mise en forme du texte et le type de données du texte (date, emplacement, URL, etc.) peuvent être utilisés pour comprendre le texte sans balisage supplémentaire. Ce processus permet de déterminer si le texte est un événement. Recette, produit ou autre type de contenu sans avoir à utiliser de balisage.
- Identification d'une signification implicite due à la structure: La mise en forme d'un corps de texte peut changer sa signification implicite. Les titres, les nouvelles lignes, les listes et la proximité transmettent une compréhension secondaire du texte. Par exemple, si du texte apparaît dans une liste classée par HTML ou dans une série d’en-têtes avec des chiffres devant elle, il s’agira probablement d’une tâche ou d’un classement. La structure est définie non seulement par les balises HTML, mais également par la taille et la force de la police de caractères et par la proximité du rendu.
Certains des éléments essentiels du traitement automatique du langage naturel devraient vous être familiers dans les contributions précédentes à cette série d'articles, telles que: l'extraction d'entités nommées ou l'identification d'une signification implicite à partir d'éléments structurels.
Le fait que Google maîtrise déjà bon nombre de ces processus est indiqué dans l'API de traitement du langage naturel, dont je parlerai plus loin.
Qu'est-ce que l'API de traitement du langage naturel de Google?
la API de traitement de langage naturel est une interface permettant aux développeurs d'accéder aux algorithmes ou aux ressources d'apprentissage automatique propres à Google NLU. Ainsi, l’API en langage naturel peut être utilisée par n’importe qui, par exemple. Effectuer une analyse des sentiments, une reconnaissance d'entité, une analyse syntaxique, une classification du contenu et d'autres tâches d'annotation de texte.
L'API Cloud Natural Language extrait les données d'un texte non structuré. Outre l'extraction d'informations telles que des lieux, des personnes et des événements, l'API peut également détecter l'ambiance dans des textes (commentaires de médias sociaux, par exemple) et analyser les intentions du client (par exemple, dans les chatbots). Pour rassembler des informations, il associe plusieurs API Google Cloud (notamment: API Cloud Speech, Vision API et API de traduction) en un seul produit.
Dans l'utilisation d'un algorithme pré-formé par Google ou un algorithme autodidacte peut être utilisé.
Selon la tâche, l'utilisation de l'API est en partie gratuite ou facturée en fonction de la durée ou du nombre d'accès à l'API.
À titre d'exemple, je vais expliquer certaines des fonctions suivantes. La démo de l'API Natural Language Processing ne fonctionnant pas actuellement, j'ai emprunté les captures d'écran des collègues de Digital Wunderwelt.
Analyse de syntaxe via l'API Google NLP
Voici un exemple d'analyse syntaxique:
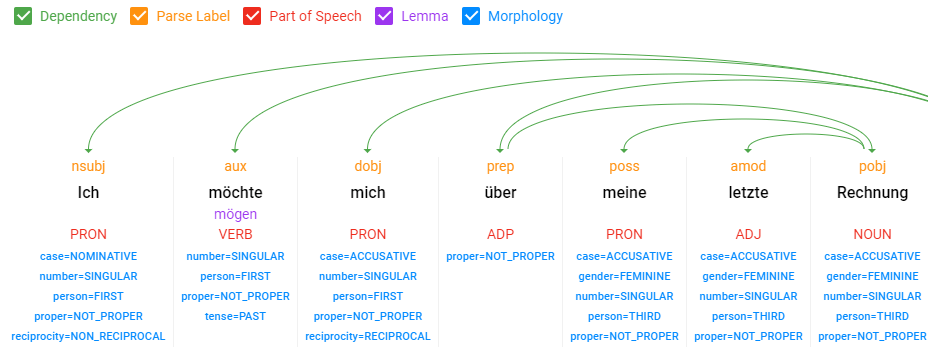
Exemple d'analyse de syntaxe via l'API Google NLP, source: digital-wunderwelt.de
On voit qu'ici, Google identifie les types de mots, tels que les noms, les verbes, les adjectifs … ainsi que les dépendances entre mots et effectue la lemmatisation.
Analyse d'entités via l'API Google NLP
Voici un exemple d'analyse d'entité à l'aide de l'API PNL de Google.
Par exemple, Entity Analysis via l'API NLP de Google
Dans ce cas, Google identifie les entités, leur attribue des classes de types d’entités et attribue un score de saillance indiquant quelle est l’entité ou l’objet principal de cette phrase. Chef de SEO ou Wadshut Tiengen sont des sujets ou des entités auxiliaires. S'il existe un article Wikipedia sur les entités, le lien y sera inclus. Cela montre que Google reconnaît également les entités qui n'ont aucune entrée dans Wikipedia. Dans quelle mesure, prendre cela déjà en compte dans le graphique de connaissances n'est pas clair. Cependant, la classification de "Chef du référencement" en tant que bien de consommation montre également que l'attribution par classes ou types d'entités est toujours incorrecte.
Analyse des sentiments via l'API Google NLP
Voici un exemple d'analyse de sentiment via l'API PNL de Google.
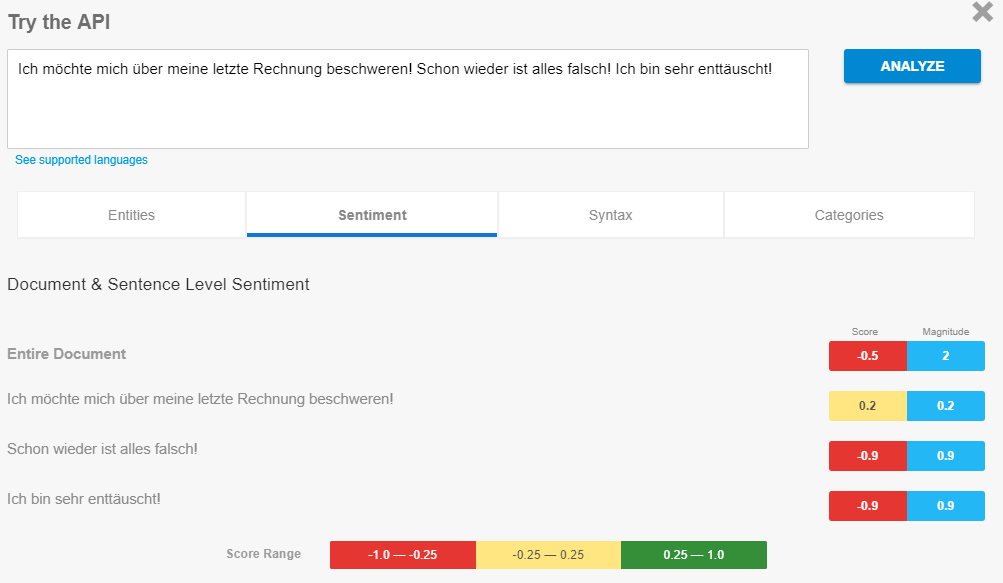
Exemple d'analyse des sentiments via la NLP-API de Google, Source: digital-wunderwelt.de
Ici, Google analyse l'humeur ou l'opinion exprimée dans la phrase. Le score de sentiment indique si l'humeur est négative ou positive. Il est intéressant de noter que cette analyse peut également être appliquée à des entités. C’est pourquoi il est intéressant de noter que Google peut consulter des clients et générer des rapports sur une marque, un produit, une entreprise, etc., et peut éventuellement prendre en compte un élément du classement sur certains sujets.
Classification du contenu via l'API Google NLP
Ici, malheureusement, je n’ai pas de capture d’écran, alors résumez ce que fait l’API. À la suite d'une classification de contenu via l'API, vous obtenez un indice de confiance en plus de la catégorie allant de 0 à 1. Cela vous dira à quel point la catégorie est vraie en ce qui concerne le contenu.
Comme je l'expliquerai plus tard, la préclassification du contenu joue un rôle important dans l'efficacité de la PNL. Dans quelles classes ou quels contextes sémantiques Google classifie le contenu, on peut le voir ici.
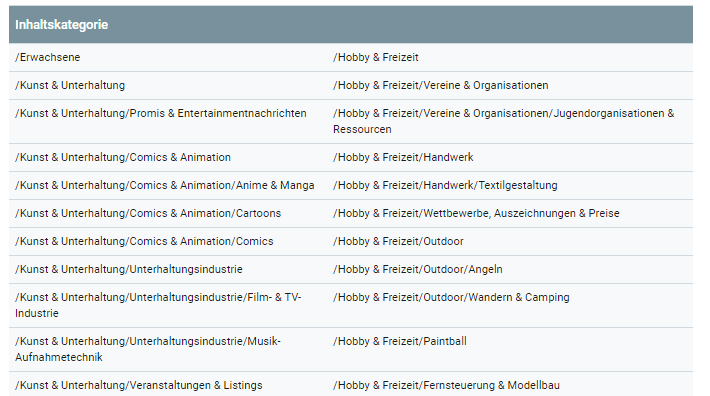
Source: https://cloud.google.com/natural-language/docs/categories
Les catégories de contenu répertoriées sont divisées en catégories principale et secondaire dans différents niveaux de hiérarchie. Je n'ai pas trouvé quels ensembles de propriétés sont affectés aux catégories. Dommage vraiment 🙂

PNL dans l'analyse d'entité
Les informations sur les entités incluent Google Des milliards de documents dans votre propre index et encore plus de combinaisons de requêtes de recherche. Les requêtes de recherche sont idéales pour la sémantique de la formation, car elles ont une intention et un contexte autonomes. (Voici un commentaire sur la façon dont Bing utilise cette méthodologie.)
Une méthode pour l'analyse de l'entité est Traitement du langage naturel appliqué aux documents. Google décrit le processus comme suit:
L'analyse des entités fournit des informations sur les entités du texte qui font généralement référence à des "choses" nommées, telles que des personnages célèbres, des points de repère, des objets généraux, etc.
Les entités au sens le plus large appartiennent à deux catégories: les noms propres attribués à des entités uniques, telles que certaines personnes, des lieux, etc., ou des noms génériques. Lors du traitement du langage naturel, également appelé "nom". Ici, une règle générale peut être bien suivie: si c'est un nom, on peut l'appeler une "entité". Les entités sont renvoyées dans le texte d'origine sous forme de décalages indexés …
L'analyse d'entité renvoie un ensemble d'entités reconnues et les paramètres associés à ces entités, tels que le type d'entité, la pertinence de l'entité pour l'ensemble du texte et les expressions associées à la même entité. Les entités sont dans l'ordre des leurs
salienceLes scores (du plus élevé au plus bas) reflétant leur pertinence pour l'ensemble du texte.Source: https://cloud.google.com/natural-language/docs/basics#natural_language_features
De cette manière, les informations sur les entités présentes dans chaque document peuvent être collectées et intégrées au Knowledge Graph ou à un autre référentiel de faits. Des co-compétitions fréquentes d'entités peuvent également être utilisées pour déterminer les relations entre entités.
- la Analyse de sentiment par entité examine le texte donné à la recherche d'entités connues (noms propres et noms génériques), renvoie des informations sur ces entités et reconnaît l'humeur émotionnelle qui prévaut dans l'entité, en particulier pour déterminer si l'auteur a une attitude positive, négative ou neutre. L'analyse d'entité se fait avec la méthode
analyzeEntitySentimentréalisée.
Si cette information est dans le graphe de connaissances ou ailleurs, par ex. n'est pas utilisé dans l'annotation du contenu dans l'index de recherche classique n'est pas clair. Selon les descriptions officielles de Google, les réponses d'une analyse d'entité ressemblent beaucoup aux résultats des requêtes de l'API Knowledge Graph. Par conséquent, on peut supposer que Google possède les paramètres d'entité tels que p. Ex. Type d'entité ou URL Wikipedia (le cas échéant) du graphe de connaissances. On ignore si les informations nouvellement acquises sont ensuite lues dans le graphe de connaissances. Je ne crois pas que les informations obtenues jusqu’à présent apparaissent dans les panneaux de connaissances, car elles sont trop non valides.
Outre l'analyse des entités, Google utilise également le traitement du langage naturel pour: l'analyse des sentiments. analyse syntaxique et classifications de contenu de documents.
- la l'analyse des sentiments examine dans le texte donné l'humeur émotionnelle qui prévaut, en particulier pour déterminer si l'auteur a une attitude positive, négative ou neutre. L'analyse des sentiments se fait avec la méthode
analyzeSentimentréalisée.- la analyse syntaxique extrait des informations linguistiques et subdivise le texte donné en une série de phrases et de jetons (généralement des limites de mots) pour une analyse plus approfondie de ces jetons. L'analyse est faite avec la méthode
analyzeSyntaxréalisée.- la la classification des contenus analyse le contenu du texte et renvoie une catégorie de contenu pour le contenu. La classification du contenu se fait avec la méthode
classifyTextréalisée.
Incorporation de mots et traitement du langage naturel
Word Embeddings L’intégration de mots allemands est un moyen pour Google d’analyser du texte. Grâce à l’intégration de différents contenus dans Word, qu’il s’agisse d’un bref tweet, d’une requête, d’un blog ou d’un site Web, ses mots peuvent être mieux compris grâce au contexte, aux mots et aux entités qui les entourent. Word Embeddings peut être utilisé pour compléter ou réécrire les termes manquants afin de rendre une phrase ou un terme plus compréhensible. Cette méthode est également utilisée pour l'interprétation par Google des requêtes Rankbrain.
Les modèles connus pour l’intégration de mots ou les analyses d’espace vectoriel pour l’application de la PNL sont, par exemple, Word2vec dans les deux applications différentes CBOW ou Skipgram et l’incorporation de texte rapide basé sur Facebook développée à partir de celle-ci, ainsi que les Embeddings Contextuels développés à partir de celle-ci, par exemple. ULM-Fit, Elmo et BERT. Mais le problème avec ces modèles est la focalisation sur la terminologie.
Ces modèles ne prennent pas en compte le contexte dans lequel les mots sont utilisés. Ce n'est que par le biais du contexte qu'il est possible de former Word Embeddings, seule la nouvelle technologie de Contextual Embeddings parvient à différencier les mêmes mots entre différents contextes. Pour Word2vec, le mot Jaguar est toujours le même, car des incorporations contextuelles telles que BERT différencient Jaguar dans le contexte Automobile et Jaguar dans le contexte animal. En fonction de la saisie, une différenciation est faite entre les unités de sens en dépit de la même orthographe et le contexte correct est modifié lors de la formation d'un simple encastrement sans signification des unités du domaine de l'automobile approchant du domaine des animaux.
Les mots que nous parlons et écrivons ne peuvent souvent être compris que dans un contexte sémantique. Seul ce contexte donne un sens aux mots et aux phrases. La même chose s'applique aux mots que nous utilisons sur un site Web.
Par exemple, considérons ces deux phrases: 1) "Le Jaguar est sorti du zoo." 2) "Le Jaguar du voisin est cassé." Le mot Jaguar diffère dans ces deux phrases en fonction du contexte. Raisonnablement, il faut utiliser deux espaces vectoriels différents du mot Jaguar en fonction de leurs deux significations différentes.
Il est donc judicieux de programmer un algorithme afin de pouvoir classer un texte dans d’éventuels contextes sémantiques avant l’alimentation des données d’apprentissage. Cela peut augmenter l'efficacité du traitement du langage naturel.
Dans l'exemple de Jaguar ci-dessus, un contexte sémantique pourrait être "voitures" et un autre "animaux". L'approche derrière cette méthode est également appelée "sémantique de trame". Le cadre contextuel est défini par certaines propriétés. Ainsi, dans le cadre contextuel, les "voitures" pourraient inclure des caractéristiques telles que la puissance, les conducteurs, la consommation, la pollution atmosphérique … J'ai déjà décrit une procédure similaire dans les contributions précédentes concernant la classification par types d'entités, d'événements, etc. En savoir plus sur Comment Google peut-il identifier et interpréter des entités à partir de contenu non structuré? et tout ce que vous devez savoir sur les types d'entité, les classes et les attributs.
La chose intéressante à propos de cette approche est que Google peut également classer le contenu à ce sujet. Google définit le cadre contextuel d'un contenu ou d'un document et peut déterminer le contexte thématique et fonctionnel. Il est alors possible de déterminer une correspondance du contenu avec l'intention de recherche d'un terme de recherche.
L'un des rôles pourrait être le projet de l'université Berkeley Framenet ici. Le projet FrameNet crée une base de données lexicale en anglais qui peut être lue à la fois par les humains et par les machines. Il annote des exemples d'utilisation de mots dans un texte réel. Ces notes sont gérées manuellement et présentent donc un degré élevé de précision.
Le projet FrameNet est une base de données lexicale contenant des informations sur les mots et les phrases (représentés par des lemmes joints à une balise de partie de parole grossière), appelés unités lexicales, avec un ensemble de cadres sémantiques qu’ils pourraient évoquer. Pour chaque cadre, il existe une liste d'éléments de cadre associés (ou de rôles, dorénavant), qui sont ainsi distingués comme éléments centraux ou non essentiels.2 Les phrases sont annotées à l'aide de cet inventaire de cadres universel. Par exemple, considérons la paire de phrases de la figure 1. COMMERCE BUY est un cadre qui peut être évoqué par des variantes morphologiques des deux exemples lexicalunits buy.V et sell.V. Acheteur, Vendeur et Marchandises sont quelques exemples de rôles pour ce cadre.
Pour cette base de données et d'autres tels que par exemple Wordnet et german.net peuvent accéder à Google pour effectuer diverses tâches dans le cadre de l'API Natural Language Processing.
Pour cette méthode, il existe un article scientifique de Google appelé Identification de cadre sémantique avec représentations de mots distribuées.
Nous présentons une nouvelle technique d'identification de cadre sémantique utilisant des représentations distribuées de prédicats et leur contexte syntaxique; Cette technique utilise des analyses syntaxiques automatiques et un ensemble générique d’incorporations de mots. Étant donné les données étiquetées annotées avec des analyses sémantiques, nous apprenons un modèle qui projette l’ensemble des représentations de mots pour le contexte syntaxique autour d’une représentation de faible dimension. Ce dernier est utilisé pour l'identification de la trame sémantique; nous obtenons des résultats à la pointe de la technologie grâce à l'analyse sémantique de style FrameNet.
Ce document décrit un concept d'utilisation de Word Embeddings pour définir automatiquement des classes contextuelles avec les propriétés représentatives correspondantes. L'objectif est de définir le cadre contextuel le plus pertinent pour la phrase ou le texte concerné et de le différencier des contextes concurrents.
Plus de détails sur les contextes de cadre sémantique et Frame.net sont disponibles dans les deux vidéos suivantes:
C’est pourquoi les modèles modernes d’apprentissage en profondeur tels que Incorporation à partir du modèle de langage (ELMo) en langage naturel Traiter davantage sur le contexte. ELMo crée différents espaces vectoriels pour le même mot dans différentes phrases. Les experts conseillent de combiner des modèles tels que ELMo avec des méthodes standard telles que Glove et Word2Vec.
Si vous êtes plus intéressé, je vous recommande l'article Techniques modernes d'apprentissage en profondeur appliquées au traitement automatique du langage.
Utilisation de la PNL dans la recherche
Je pense que le traitement automatique du langage est utilisé dans les recherches Google dans les domaines suivants:
- Interprétation des requêtes de recherche (Rankbrain)
- Classification du sujet et but des documents
- Analyse d'entité dans les documents, les requêtes de recherche et les publications sur les réseaux sociaux
- Pour les extraits sélectionnés et la recherche vocale
- Interprétation du contenu vidéo
- Extension et amélioration du Knowledge Graph
Le traitement du langage naturel est la méthode la plus importante pour identifier des entités
Comment Google peut-il identifier et interpréter des entités à partir de contenu non structuré? Le traitement du langage naturel joue actuellement le rôle le plus important pour Google dans l'identification des entités et de leur importance.
Toutefois, la pratique montre que jusqu'à présent, Google n'a qu'un accès très limité aux informations non structurées, du moins jusqu'à la diffusion dans les Knowledge Panels. Les premières applications pratiques d’exploration de données à partir de données non structurées se trouvent dans les extraits sélectionnés, bien que cela soit plus probable après l’utilisation directe de Traitement du langage naturel ressemble sans inclure le graphe de connaissances.
De plus, Google ne travaille actuellement que sur des entités non incluses précédemment dans le graphique de connaissances. PNL, pour les identifier, quel que soit le graphe de connaissances. Pour l’identification des entités et la classification thématique, le traitement du langage naturel sert bien. Cependant, cela ne garantirait que le critère de complétude, le cas échéant, d’actualité. La PNL à elle seule ne garantit pas la justesse.
Je pense que Google maîtrise assez bien le traitement du langage naturel, mais il n'obtient pas de résultats satisfaisants pour l'évaluation des informations extraites automatiquement. Ce sera probablement la raison pour laquelle Google agit toujours avec prudence, en ce qui concerne le positionnement direct dans les SERPs.
Traitement du langage naturel pour la construction du graphe de connaissances
Comme dans l'article précédent Comment Google peut-il identifier et interpréter des entités à partir de contenu non structuré? Par exemple, pour une base de données Wisses comme Knowledge Graph, l'exploration de données est expliquée à partir de données non structurées telles que Les sites Web ne sont pas triviaux. Surtout, en plus de l'exhaustivité, l'exactitude de l'information est importante. L’intégralité de la solution permet désormais de garantir une très bonne évolutivité de Google par rapport au traitement du langage naturel, comme le montrent les résultats de l’API de traitement du langage naturel. Seule une base de données couvrant un sujet et le contexte approprié est un saillienotation de crédit possible.
Pour cela, les étapes déjà expliquées ci-dessus fourniture de données, Préparation des données, analyse de texte et enrichissement de texte passer par, Les phrases, les paragraphes et les textes complets sont divisés en sections via la PNL, les entités identifiées et complétées par des commentaires (annotations).
Cela permet d'extraire des connaissances à partir de données non structurées. Sur cette base, des relations entre des entités et un graphe de connaissances peuvent être créés. Cela aide le "Une partie du marquage de la parole». Les noms sont des entités potentielles et les verbes représentent souvent la relation des entités les unes avec les autres. Les adjectifs décrivent l'entité et les adverbes décrivent la relation.
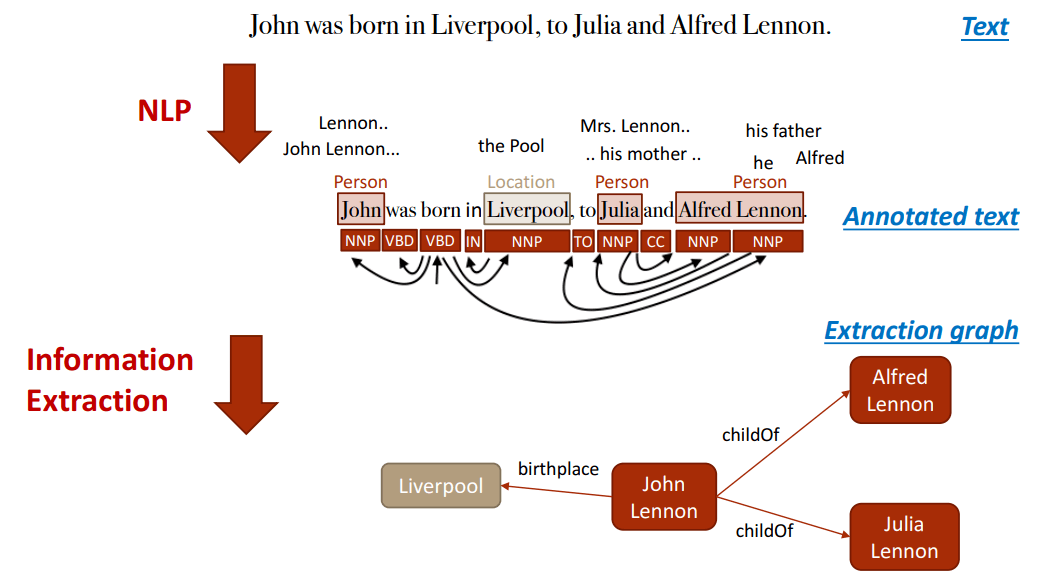
Exemple de création d’un graphe de connaissances par la PNL; Source: https://kgtutorial.github.io/wsdm-slides/Part2_knowledge-extraction.pdf
Dans le cas de termes ambigus ou de synonymes, il est possible de définir plus précisément quelle entité est maintenant basée sur les termes supplémentaires mentionnés dans le contexte. De cette façon, même les entités reconnues peuvent être affectées à des classes de types d'entités. Ainsi, la marque de voiture Jaguar est appelée avec d'autres termes que l'animal.
La reconnaissance et l’affectation d’entités à des types d’entité nécessitent une hiérarchie initiale de classes, comprenant certains attributs, qui peut être complétée automatiquement par de nouveaux attributs. Les algorithmes d'autoapprentissage, tels qu'ils sont connus en apprentissage machine ou en apprentissage approfondi, sont également capables de reconnaître et de compléter de manière indépendante de nouvelles classes de types d'entités.
Jusqu'à cette étape, la "complétude" est garantie en tant que critère de qualité pour un graphe de connaissances. Le deuxième critère de qualité important est l'exactitude. Bien qu'à mon avis la complétude puisse être assurée presque sans intervention humaine supplémentaire, je vois tout de même la justesse d'un effort manuel élevé. À l'heure actuelle, il n'est possible de revenir ici qu'aux approches d'apprentissage automatique supervisé. Un clustering sémantique hiérarchique correctement formé sur des méthodes d’apprentissage automatique non supervisées est un très gros défi, mais il n’est pas sûr de savoir quand et si cela peut jamais conduire à des résultats presque complètement corrects. (Pour plus d'informations sur les différentes formes d'apprentissage automatique, consultez l'article Qu'est-ce que l'apprentissage automatique? Définition, différence par rapport à l'intelligence artificielle, son fonctionnement …)
Assurer l'exactitude des informations nécessite un scoring ou une évaluation. L'évaluation doit être basée à la fois sur les résultats finaux et les attributs. De plus, les personnes responsables doivent apporter un certain niveau d’expertise.
Google Knowledge Vault est l'actuel "fournisseur d'information"Pour les données provenant de sources non structurées pour Knowledge Graph, fonctionne entièrement automatisé dans les domaines des types d’entités ainsi que pour la reconnaissance et l’attribution des attributs standard. Les faits sont en partie automatisés et en partie contrôlés et évalués manuellement.
À ce stade, je ne voudrais pas aller plus loin et espère que mes commentaires ont fourni une compréhension de base du sujet du traitement automatique du langage.
Si vous voulez aller encore plus loin ici, je vous recommande ces diapositives.
Conclusion: construction du graphe de connaissances via Wikipedia, Wikidata et Knowledge Vault
Avec cet article, je voudrais conclure le sujet de l’exploration de données pour la construction du graphe de connaissances de Google dans la mesure du possible, ainsi que dans les contributions suivantes plus concrètes sur le rôle du graphe de connaissances et des entités jouant spécifiquement pour la recherche.
Il reste à noter que, à mon avis, le plus grand impact sur le graphique de la connaissance wikipediaqui Coffre de connaissances. Wikidata et étiquettes de données structurées ont. À l'exception des données structurées extraites manuellement par les webmasters, Google devient plus ou moins ouvert Traitement du langage naturel se replier sur.
- wikipedia fournit de nombreuses données semi-structurées accessibles via des bases de données telles que DBpedia peut être traité de manière plus structurée et peut être directement transféré au Knowledge Graph. Pour moi, il s'agit actuellement de la source de données la plus importante pour Google, car les informations sont vérifiées manuellement. Le traitement du langage naturel joue ici un rôle mineur.
- la Coffre de connaissances deviendra de plus en plus important à l'avenir, car Google a besoin de toute urgence d'informations complètes provenant de sources de données non structurées. Celles-ci peuvent uniquement être générées via le traitement du langage naturel ou l'apprentissage automatique pour le graphe de connaissances. La mesure dans laquelle Google parvient à abandonner l'aide manuelle est une spéculation. Cependant, pour atteindre l'évolutivité, ce sera l'objectif souhaité. Toutefois, selon les résultats actuels souvent erronés, il semble que le coffre-fort de la connaissance en soit encore à ses balbutiements.
- De nombreux référenceurs ne font que regarder Wikidata lorsqu'il s'agit d'influencer / manipuler les panels de connaissances. Il est relativement facile de créer des entrées pour des entités qui se retrouvent souvent dans les SERP. Avec Wikidata, on trouve la déclaration suivante:
Alors que Freebase était l’open source du Knowledge Graph, ce n’est pas le cas de Wikidata. Wikidata est une source de connaissances particulière parmi beaucoup d'autres, mais il n'a pas la même position que Freebase.
La source la plus importante du Knowledge Graph est en réalité l’Internet lui-même. Vous pouvez créer vos propres pages Web avec schema.org. Elles seront lues et traitées par tous les principaux moteurs de recherche.
Da es aktuell doch noch relativ einfach ist über Wikidata Knowledge Panels zu erzeugen, wie einige Tests von SEO-Kollegen gezeigt haben muss ich diese Aussage etwas relativieren. Wikidata scheint hier eine durchaus relevante Quelle zu sein. Allerdings sind die Moderatoren bei Wikidata nicht ganz so streng wie die die Wikipedianer. Von daher sehe ich es auch eher als Zwischenlösung, solange bis der Knowledge Vault nahezu fehlerfrei funktioniert.
- la Auszeichnung von Inhalten durch strukturierte Daten scheint ein probates Mittel zur Snippet-Optimierung zu sein. Mir fehlen allerdings aktuell die (deutschen) Beispiele bei denen eine Auszeichnung mit strukturierten Daten zu einer Veränderung von Inhalten in Knowledge Panels geführt haben. Eigene Tests sind bisher ergebnislos geblieben. Mir sind bisher nur wenige Beispiele aus den USA bekannt. Wenn Du deutsche Beispiele hast kannst Du mir sie gerne schicken und ich baue sie dann gerne mit einer Erwähnung ein. Aber auch die Auszeichnung mit strukturierten Daten halte ich wie bereits beschrieben nur für eine Zwischenlösung. Gerade für die Anreicherung von Entitäten und Entitätstypen-Klassen mit Standard-Attributen spielen sie eine große Rolle in Form von menschlich verifizierten Trainingsdaten. Aber nur solange wie Google sie nicht mehr braucht, da der Algorithmus genug Daten zum lernen für die eigenen Modelle bekommen hat. Mehr dazu im Beitrag Warum strukturierte Daten für Google zukünftig überflüssig werden könnten .
Damit schließe ich das Thema Data Mining für den Knowledge Graph erst einmal ab. Hier eine Übersicht der weiteren Beiträge zu dem Thema:
Zum Abschluss noch einige Tools, die ich in diesem Zusammenhang nicht unerwähnt lassen möchte.
Tools
Nachfolgend einige weitere Tools um sich ein bisschen mit dem Thema Textanalyse über NLP auseinanderzusetzen:
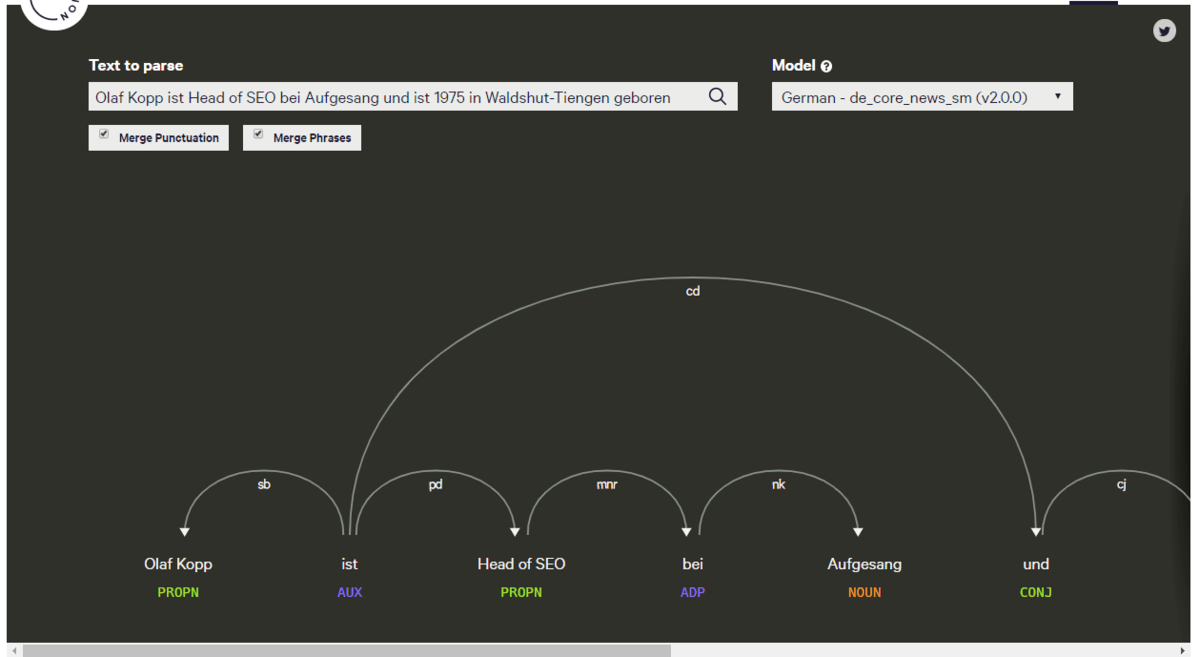
Explosion.ai
Mit Explosion.ai kann man einige Dinge wie Part of Speech Tagging und Analyse der Wortabhängigkeiten tun, die man mit der Natural Language Processing API von Google auch machen kann. Ich finde die Google API aber aus SEO-Gründen spannender.
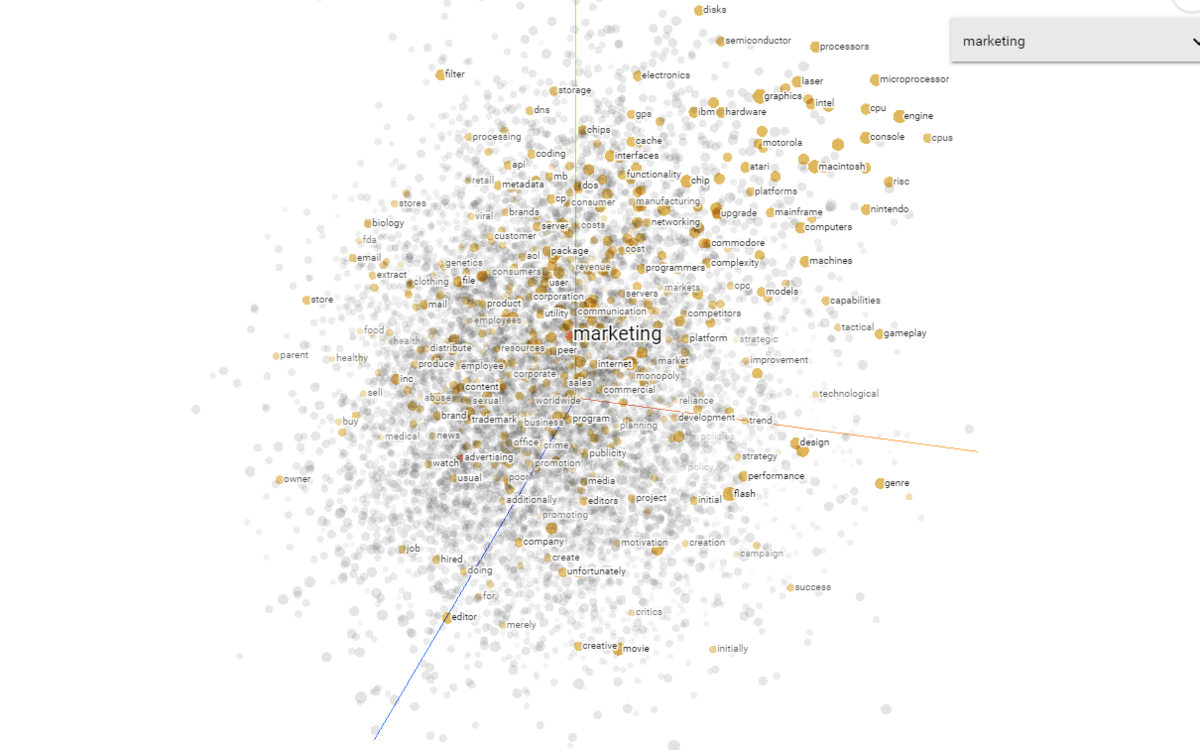
projector.tensorflow.org
Über dieses Tool lassen sich Nähe von Begriffen zueinander analysieren. Mit Blick auf NLP, Entitäten und den Knowledge Graph könnte es interessant sein welche Begriffe bzw. Attribute in Nachbarschaft zueinander stehen. Dieses Tool basiert auf dem embedding projector von tensorboard, mit dem auch selbst trainierte Embeddings bis zu 100000 Datenpunktec visualisiert werden können.
Chrome Extension zur Entitäten-Extrahierung aus Websites
Eine Chrome Extension namens Extractor de entitades bedient sich der Natural Language Processing API um die Entitäten-Analyse durchzuführen und diese dann in den SERPs zu den jeweiligen Dokumenten auszugeben. Die Extension ist eine nette Spielerei. Die wirklich interessanten Analysen bzw. Aufgaben deckt sie allerdings nicht ab.
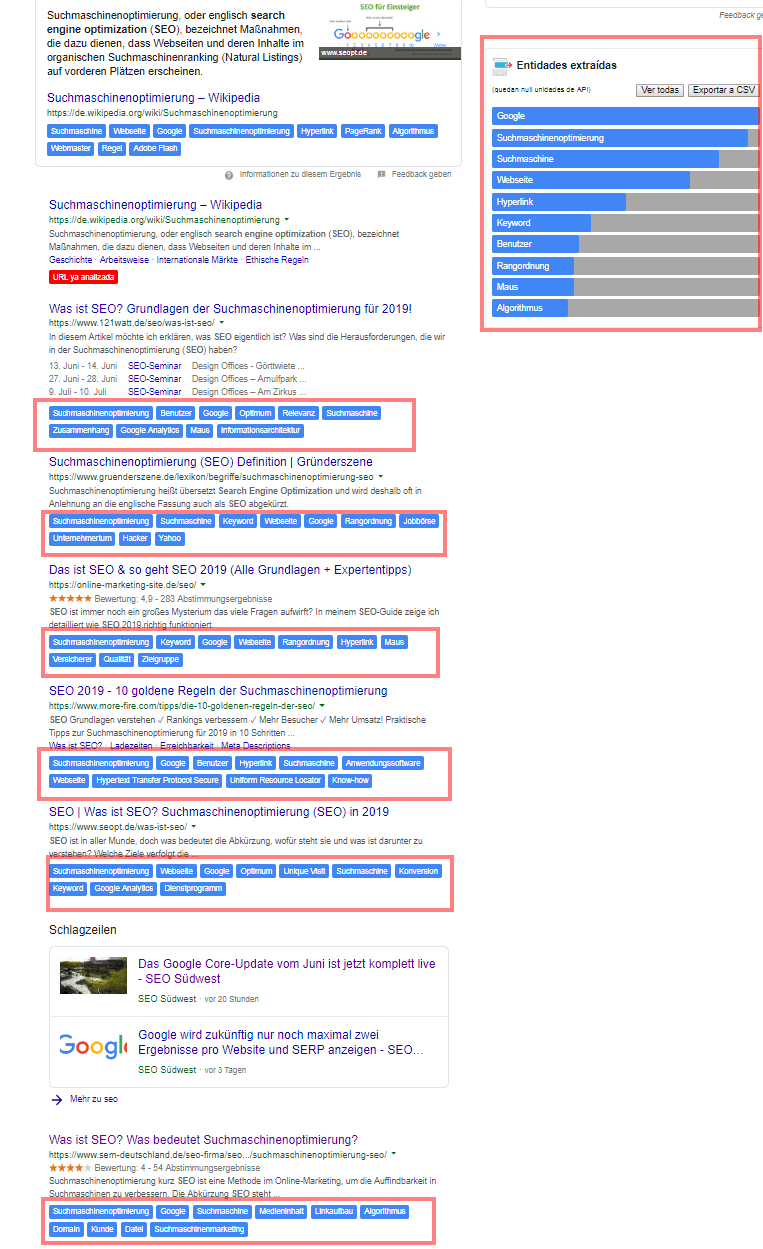
Entitäten-Mining mit der Chrome Extension Extractor de entidades am Beispiel der SERPs zum Begriff „seo“