
Sommaire
At-il vraiment besoin de divers outils de référencement pour le premier regard sur un domaine? Découvrez quels sont les aspects que vous pouvez analyser sans les crawlers, le classement des données et autres et le moment où le support des outils est vraiment nécessaire.
Est-ce que le référencement a été fait ici?
L'un des facteurs de classement connus et encore importants est le titre d'un document. Une "page de démarrage" dans le titre ou l'utilisation automatique du nom de la page dans le titre sont des signes évidents que le référencement n'a pas été un problème jusqu'à présent et vous pouvez espérer plus de gains rapides.

Figure 1: "Homepage" dans le titre – un signe pour un référencement inexistant.
Un autre sujet simple, souvent critiqué par les référenceurs, est la structure de titre. En commençant avec exactement un H1, HTML fournit des en-têtes allant jusqu'à H6. Cependant, ceux-ci ne doivent être utilisés que dans le contenu principal d'un document et dans le bon ordre.
Dans le cas d'articles de parité sous le répertoire "Fachinfos", commence par un en-tête H3 par défaut, il n'existe pas de titre de premier ordre (H1).
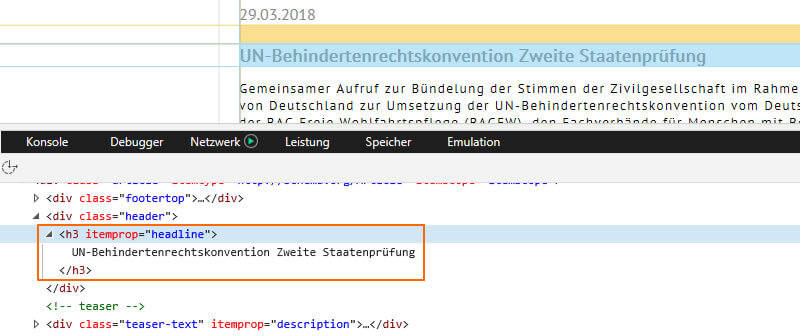
Figure 2: Structure d'en-tête HTML incorrecte – commencez par H3 au lieu de H1.
Parmi les autres bases de OnPage faciles à influencer que vous pouvez découvrir rapidement sur le code source, citons:
- Parler des noms d'image
- Des textes anciens
- Légendes / Légendes
- Meta description
- tag canonique
Y at-il des problèmes avec le contenu en double?
Google gère bien les doublons de contenu (DC), ce qui n’est pas préjudiciable en soi, contrairement aux mythes courants sur le référencement. Néanmoins, DC peut toujours nuire au classement si les signaux de classement peuvent être distribués à différentes variantes d'URL. Chaque contenu ne doit donc être accessible que sous exactement une URL.
Vérifiez si une redirection 301 correcte se produit lorsque vous appelez l'URL de l'une des manières suivantes:
- avec www et sans www
- avec https et avec http
- avec slash final (slash final) et sans
- avec quelques caractères supplémentaires dans l'URL
Comme le montre la figure 3, il est possible d'appeler une URL de la Joint Welfare Association à la fois via la version sécurisée (https) et via http.
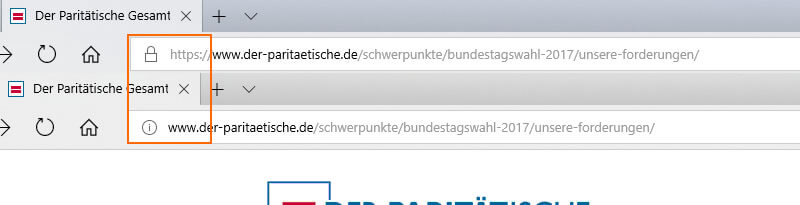
Figure 3: La même URL est accessible via une connexion sécurisée (HTTPS) et non sécurisée via http.
Certaines URL sont en fait indexées avec HTTPS, tandis que la majorité de la variante http de l'index de Google est représentée.
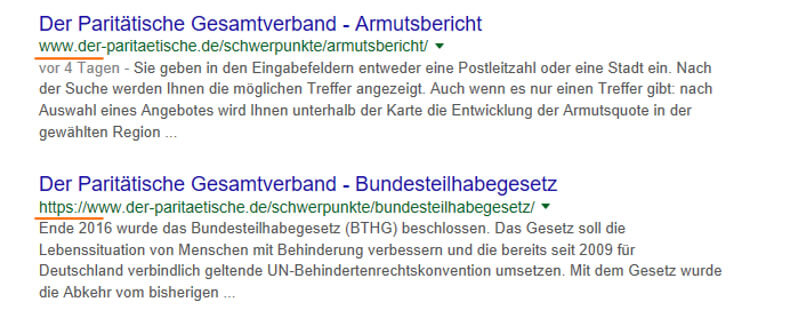
Figure 5: der-paritaetische.de est indexé sur Google avec différents protocoles.
Bien entendu, dans la barre d'adresse du navigateur, seule la moitié de la vérité sur les différentes variantes d'URL est disponible. Par conséquent, appuyez sur F12 dans le navigateur, accédez à l'onglet "Réseau" (Google Chrome), puis rechargez la page. Comme on peut le voir ici, l'URL modifiée à partir de la figure 4 génère une erreur 404 et la version sans / est transmise via 301, ce qui devrait être le cas (figure 6).
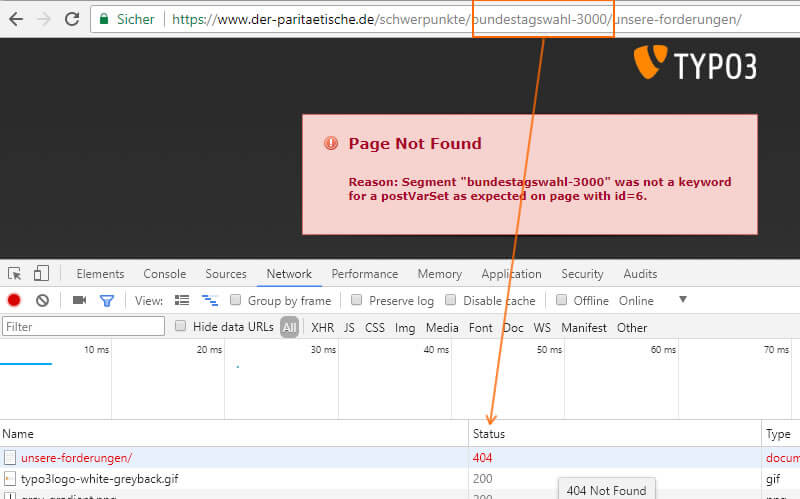
Figure 6: Code d'état 404 dans la console Google Chrome Web Developer.
Mais cela vaut la peine de tester différentes plages de pages. Dans l’annuaire Informations sur les spécialistes, par exemple Les URL peuvent être modifiées presque arbitrairement tout en fournissant le code de statut 200 (Figure 7). Une situation dans laquelle des variantes d'URL différentes sont souvent indexées et classées, ce qui nuit à la performance du référencement.
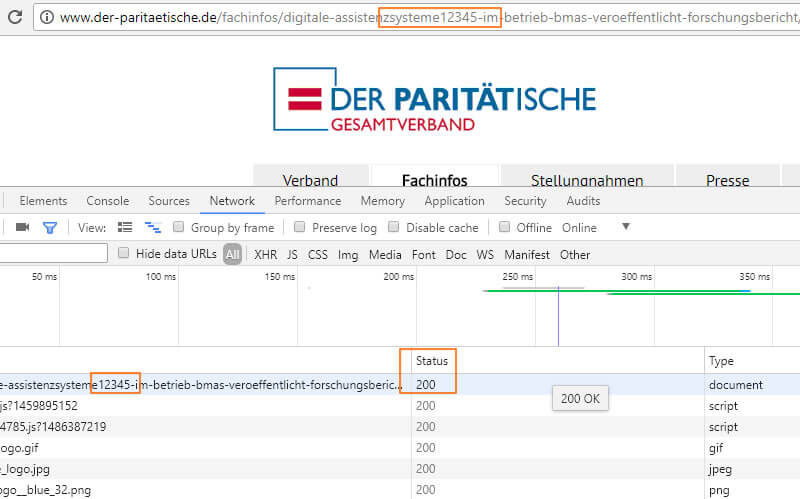
Figure 7: Les URL du répertoire info peuvent être modifiées presque arbitrairement et fournissent un statut OK.
C’est précisément là que réside une faiblesse des tests manuels: Seuls des échantillons aléatoires peuvent être prélevés pour le test de toutes les pages d'un domaine dans une situation d'erreur spécifique. Des outils sont nécessaires en dehors des moyens intégrés du navigateur.
Si la console Webdeveloper est déjà ouverte, consultez l'onglet "Performances". Sauf si déjà présélectionné, cochez la case "Captures d'écran". Ensuite, vous démarrez via la deuxième icône à gauche ou via CTRL + Maj + E un rechargement, pour lequel le temps de charge est maintenant mesuré.
Le graphique suivant montre 3 lignes verticales:
- vert: le premier, visible par le signe de la vie de l'utilisateur de la page (First Paint)
- bleu: l'analyseur a traité le code HTML complet et le modèle d'objet document est prêt (DOMContentLoaded). Ce n'est que maintenant qu'il est possible d'accéder à tous les éléments via JavaSript. Les feuilles de style et les images peuvent encore être manquantes dans cet état.
- rouge: le document est complètement chargé, y compris toutes les feuilles de style et les images (charge)
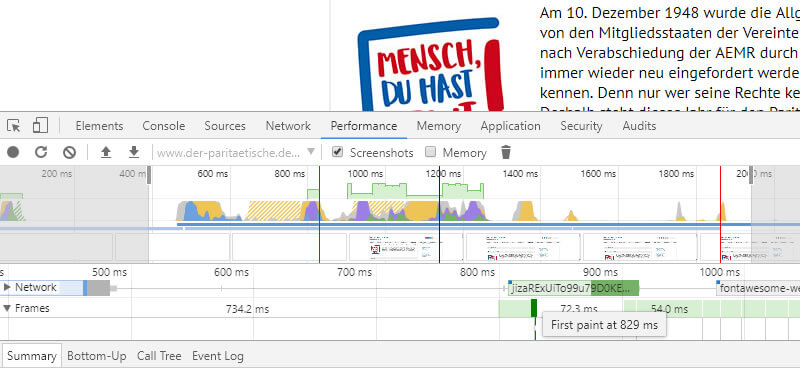
Figure 8: Mesure des performances à parité dans Google Chrome.
Bien entendu, il existe un potentiel d'optimisation en ce qui concerne leurs performances dans la page examinée ici. Cependant, la page ne se trouve pas dans une zone critique, car elle sera complètement chargée dans un délai de 1 à 2 secondes. Nous allons donc commencer par rechercher d'autres problèmes majeurs.
Astuce pour le test manuel
Certains contenus doivent inclure chaque document et vous pouvez facilement le vérifier via la vue du code source (CTRL + U). Il est important de choisir les exemples de manière à avoir coché au moins une page pour chaque variante de modèle / type de page. Vous pouvez identifier très facilement les erreurs structurelles qui imprègnent chaque document d’un certain type de page.
Les types de page à la Joint Welfare Association seraient, par exemple:
Qu'est-ce que Google a dans l'index?
Les documents que Google a indexés pour la recherche peuvent être déterminés très rapidement via une requête sur le site. À propos de site: der-paritaetische.de vous apprenez que Google a plus de 8 000 pages dans ce domaine dans l’index et n’obtient que des résultats sur le domaine spécifié affiché, y compris tous les sous-domaines.
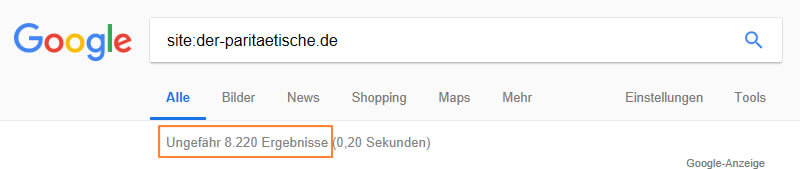
Figure 9: der-paritaetische.de a plus de 8 000 pages sur Google dans l'index.
Google a-t-il trop de pages dans l'index?
Maintenant, si vous avez migré sur le site en question, demandez-vous si la taille de la page que vous percevez correspond au nombre de pages indexées par Google. Si vous êtes surpris du nombre élevé de pages spontanément, c’est un signe certain pour:
- Problèmes techniquesqui conduisent à l'indexation d'URL sans valeur ajoutée pour la recherche.
- Problèmes avec l'architecture de la page / liens internes, parce que vous avez visiblement négligé la masse de pages en surfant sur la page.
La valeur réelle de la requête de site est dans la liste des résultats.
L'ordre de résultat dans la requête du site
En ce qui concerne la question de savoir si les résultats de la requête sur le site sont publiés dans un ordre particulier, Google n’est pas tout à fait d’accord. Alors que Matt Cutts a déclaré que le tri suivait grossièrement le rang de page de chaque page et que la longueur de l'URL était un autre facteur, John Müller parle d'une requête artificielle et n'assume pas le tri en fonction de critères spécifiques.
Cependant, vous pouvez supposer que Google n'utilise pas de générateur de nombres aléatoires pour déterminer l'ordre. Pourquoi la page d'accueil apparaît-elle en premier? Par conséquent, il doit exister des critères selon lesquels la liste est triée. Même sans connaître les critères de tri exacts, vous devez donc vous assurer que les requêtes du site ne sont pas complètement des pages sans importance.
En outre, la recherche de site en rapport avec la recherche d'un mot clé a certainement quelque chose de pertinent.
La requête du site portant le mot-clé "Rapport sur la pauvreté", comme le montre la figure 10, est remarquable en ce qui concerne le document PDF en position 3, qui date de 2016. Nous verrons toujours pourquoi il n'y a pas de version de 2017 ici, bien qu'elle existe.
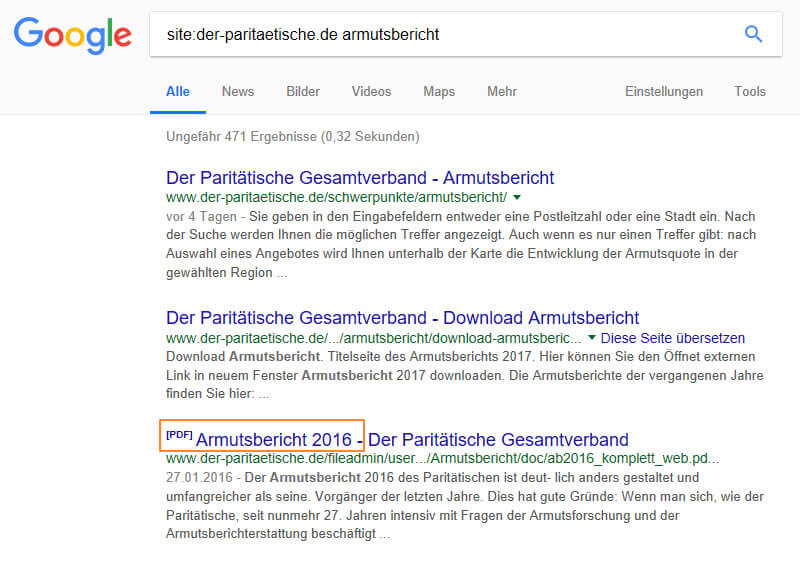
Figure 10: La requête de site associée au mot clé fournit les résultats les plus pertinents d'un domaine au mot clé.
Détecter les pages qui n'appartiennent pas à l'index
Vraisemblablement, vous pouvez voir les URL avec le sous-domaine "relancer" à la figure 11. Une requête de site sur le sous-domaine (site: relaunch.der-paritaetische.de) apporte des résultats supplémentaires. Apparemment, la dernière relance a été préparée sous un sous-domaine exploitable pour Google.
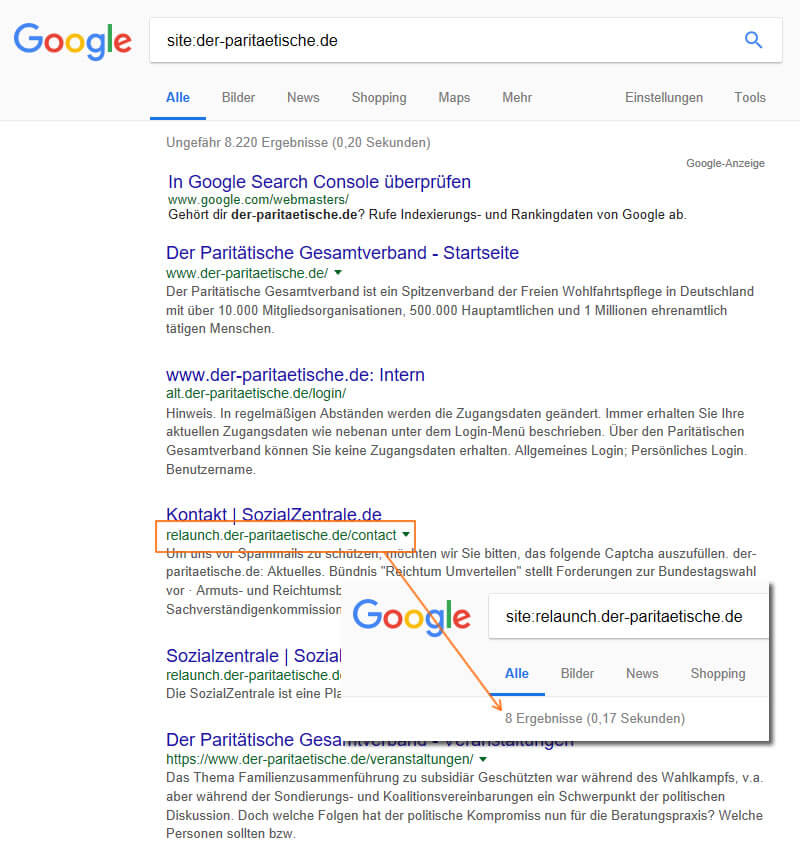
Figure 11: La requête de site affiche des résultats que vous ne voulez probablement pas dans la recherche.
Semble normal sur la première page, vous devriez sauter certaines pages et regarder les résultats sur les dernières pages. Sur la page 18, dans le cas de la parité, par exemple l'URL http://www.der-paritaetische.de/fachinfos/detailseite/?tx_news_pi1%5Bnews%5D=10704&cHash=5d8e8a28b561da92ec0a986ea8ba21fa vous seul en tant qu'optimiseur de moteur de recherche causera une certaine perte de vision.
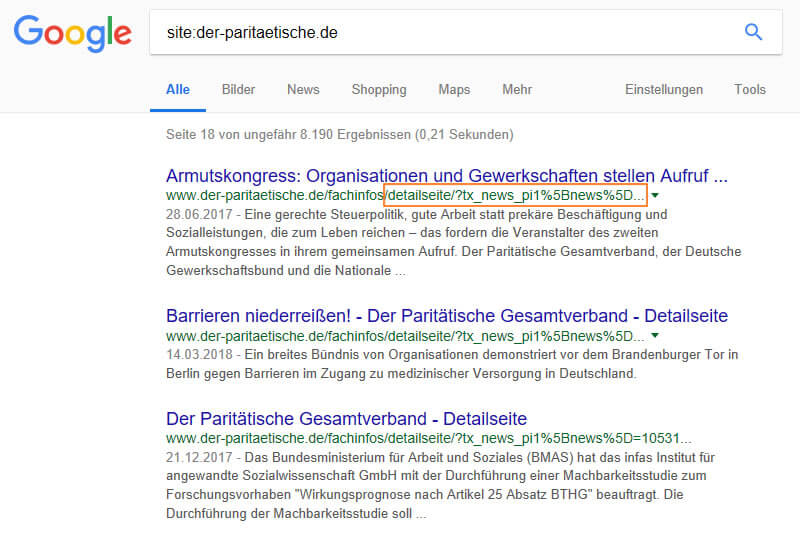
Figure 12: Plus en arrière, une requête de site trouve des URL problématiques.
Le contenu de la page ressemble initialement à un article ordinaire. Il va de soi qu'une fonction du système de gestion de contenu produit l'URL étrange et qu'une autre variante intéressante existe.
Dans le répertoire principal "Fachinfos" à la page 4, vous trouverez le teaser de l'article correspondant, disponible à l'adresse http://www.der-paritaetische.de/fachinfos/barrieren-niederreissen-kundgebung-anlaesslich-des-kongresses-armut- et santé / conduit.
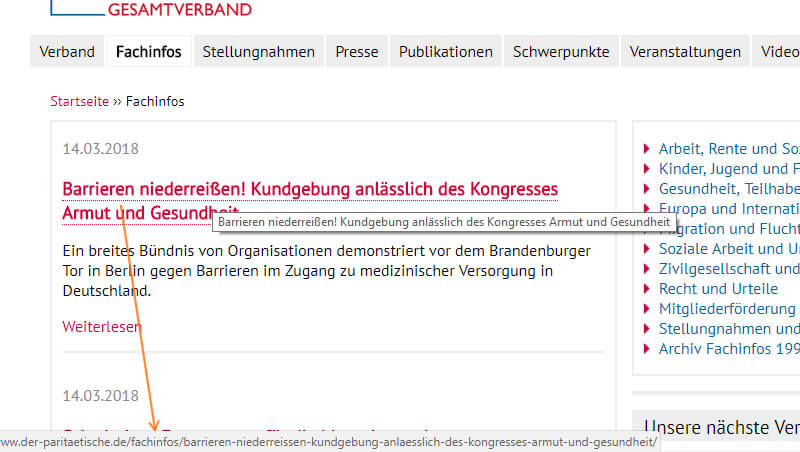
Figure 13: À propos du teaser, la bonne variante d'URL parlée est liée.
Si le problème ne peut pas être résolu techniquement, cette situation pourrait être résolue via une balise canonique pointant vers la dernière variante. Parce que le contenu est exactement le même.
Sur les côtés de la parité mais en principe pas de jour canonique défini. Bien qu'il n'y ait aucun cas de contenu dupliqué devant être résolu via une balise Canonical, il devrait au moins exister une balise Canonical à auto-référencement.
Découvrez 404 bugs
Pendant ce temps, les URL telles que http://relaunch.der-paritaetische.de/contact de la figure 11 entraînent une erreur 404. En règle générale, vous pouvez voir rapidement en parcourant quelques résultats de la requête du site, s'il y a 404 erreurs parmi les pages les plus importantes du domaine.
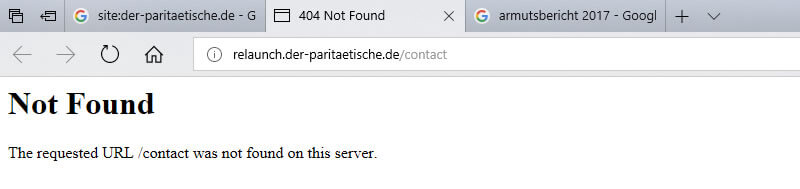
Figure 14: Certains résultats de la requête sur le site renvoient des erreurs 404.
Pagination indexée
La recommandation officielle de Google pour la navigation par défilement, également appelée pagination, est la construction rel = next / prev. Cela indiquera clairement au bot dans l'en-tête d'une page s'il fait partie d'une pagination. Une autre option consisterait à fournir les pages 2 à n avec noindex et, en plus de rel = "next / prev", cela pourrait être utile. Les deux font partie de la pagination de la Joint Welfare Association mais ne sont pas à trouver.
Une requête sur le site http://www.der-paritaetische.de/fachinfos/detail/News/uebergreifend/page/ renvoie en conséquence de nombreux résultats de page de pagination indexés par Google.
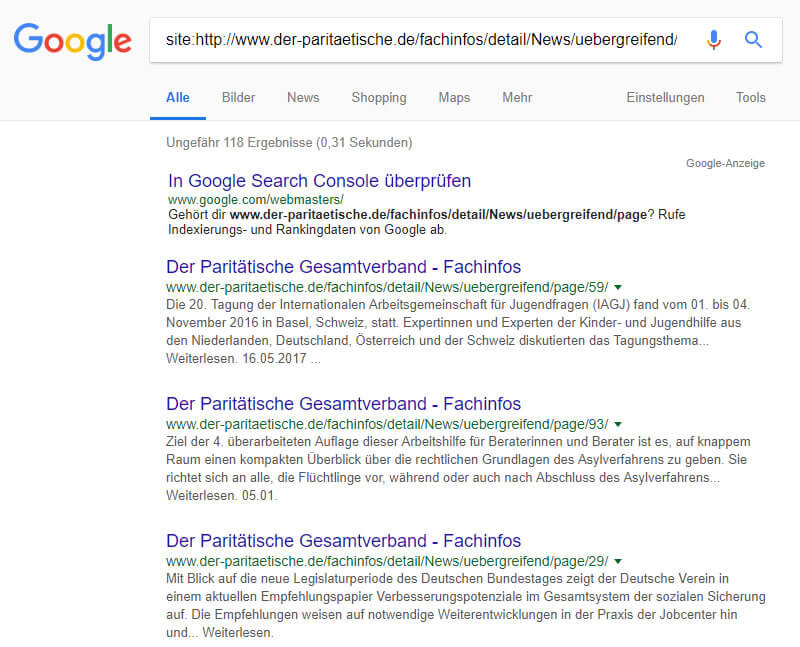
Figure 15: Une requête de site sur la pagination indique un nombre élevé de pages indexées pour la navigation de pagination.
Le fait que cela puisse poser problème pour la recherche montre la recherche exemplaire du titre d'un article: "Thèses pour le développement futur des soins de courte durée en isolement". À la page 3, vous trouverez la page 3 de la pagination http://www.der-paritaetische.de/fachinfos/detail/News/uebergreifend/page/3/. Là encore, si vous appelez cette page à ce moment-là, l'article correspondant vient de glisser au dernier endroit, de sorte que cela (selon l'écran) n'apparaisse plus dans la zone visible. Au moins, cela se trouve encore sur cette page. Si l'article continue de glisser à la page 4 et que le robot d'exploration de Google ne revisite pas la page entre-temps, l'utilisateur ne trouvera plus le contenu initialement taquiné sur le résultat, ce qui entraînera des signaux d'utilisateur erronés dans la masse.
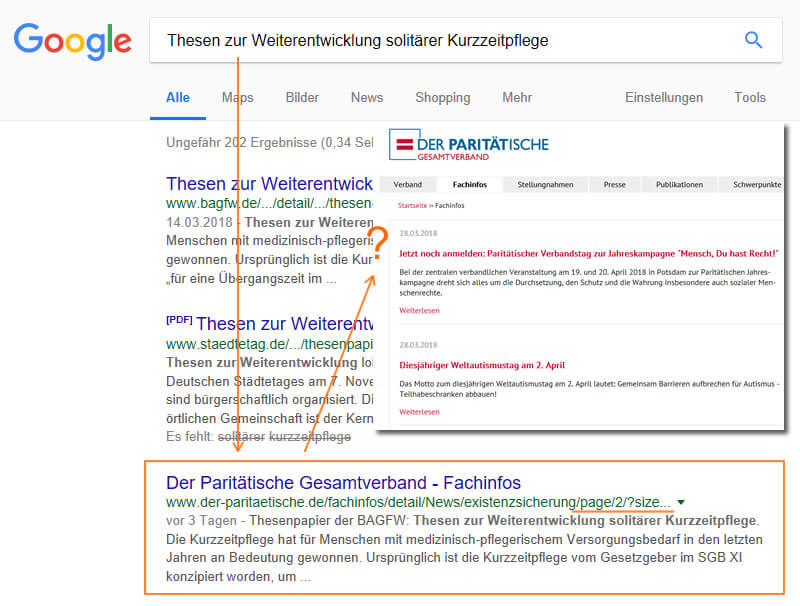
Figure 16: Au lieu de l’article proprement dit, Google renvoie à une page de la pagination sur laquelle cet article est taquiné.
Etant donné que les pages de présentation obtiennent souvent plus de puissance de lien qu'un article unique, il s'agit d'un problème courant, pas seulement dans le domaine analysé ici.
Les priorités? Vraiment?
Bien sûr, l’une des questions les plus importantes est de savoir si un domaine est trouvé pour leurs sujets ou non et si le résultat est justifié. Les sujets les plus importants d'un domaine peuvent être déterminés très rapidement sans l'aide d'outils. Si les sujets de navigation ne sont pas nommés directement en fonction des sujets principaux, des points tels que "Réalisations" ou "À propos de nous" indiquent les sujets principaux du domaine. Dans l'association de bienfaisance étudiée, le point clé de la navigation principale est appelé "points focaux". L’opérateur de site Web aimerait probablement être trouvé pour les mots-clés mentionnés ici et les nuages associés.
Dans ce cas, on remarque immédiatement le "rapport sur la pauvreté". Même quelqu'un qui n'a rien entendu de la Joint Welfare Association aura déjà trébuché sur le très cité rapport sur la pauvreté de l'association. Google le sait aussi et ajoute à titre de suggestion. directement "association de solidarité".
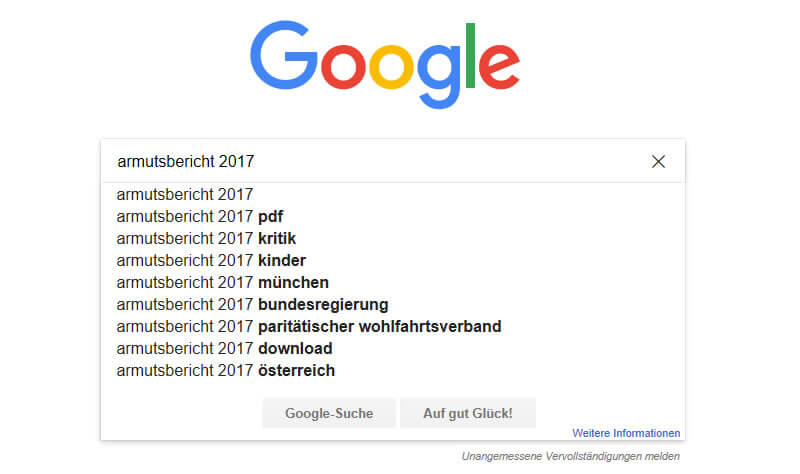
Figure 17: Les propositions de Google concernant le "Rapport sur la pauvreté" montrent la position de l'organisme sur le sujet.
Néanmoins, la page de l’Association de Berlin n’est que le 7e au moment du scrutin.
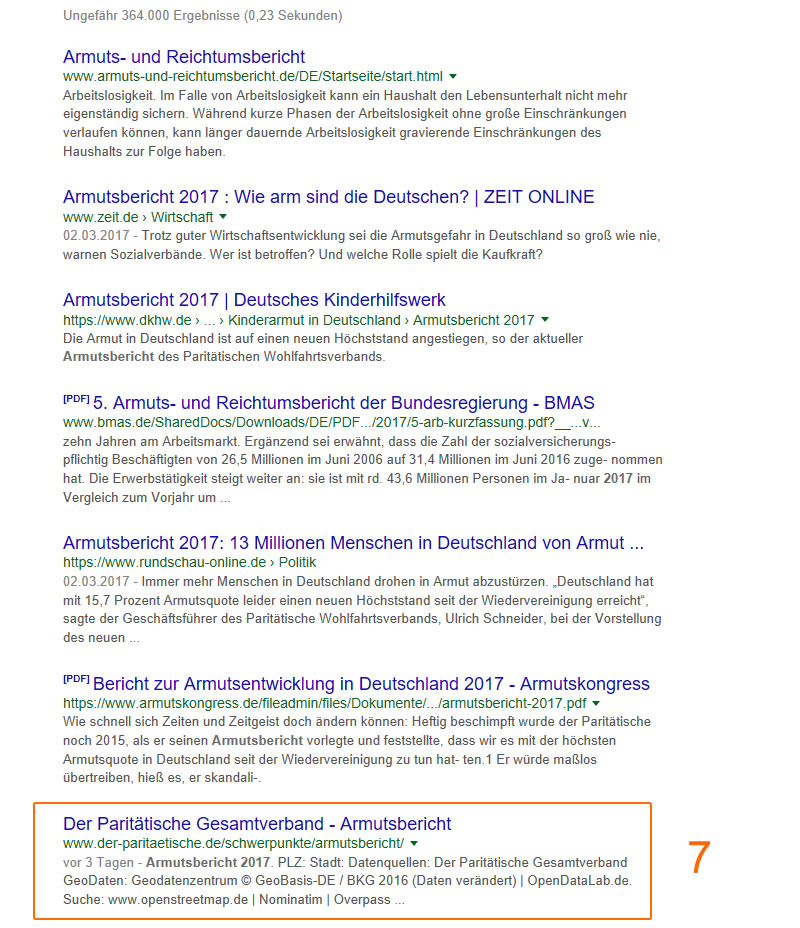
Figure 18: Top 10 des classements pour le mot-clé Rapport sur la pauvreté 2017.
Si vous regardez la page de classement http://www.der-paritaetische.de/schwerpunkte/armutsbericht/, ceci est encore plus étonnant et montre clairement la force des signaux OffPage. En termes de contenu, le contenu de cette page est vraiment médiocre, ce qui ne lui a certainement pas valu d'être classé dans le top 10.
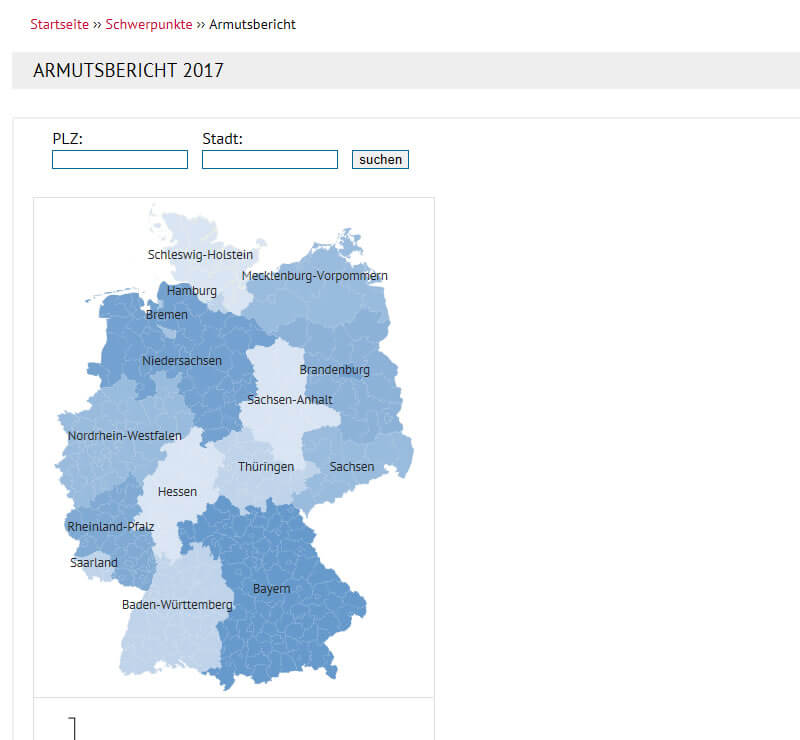
Figure 19: Contenu textuel peu pertinent dans le rapport sur la pauvreté sur la page de destination.
Une requête de cache révèle que Google rencontre des problèmes pour interpréter les JavaScripts côté client qui rendent la carte interactive.
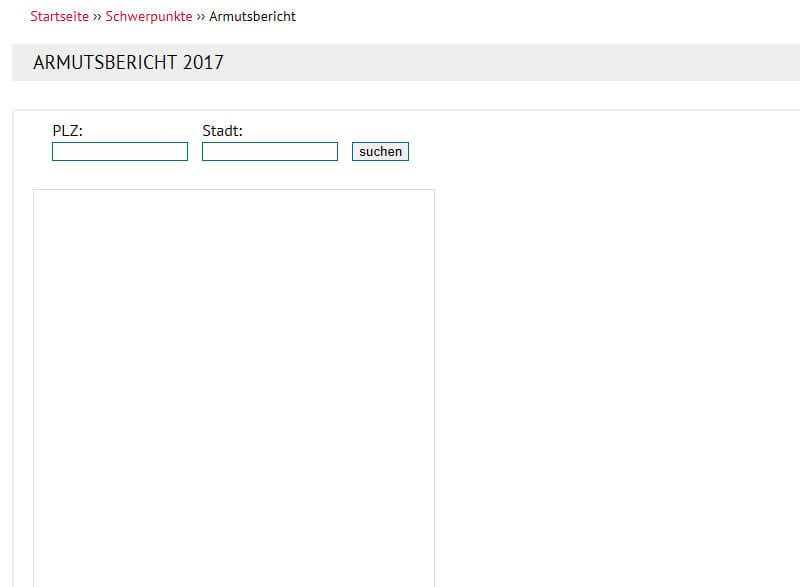
Figure 20: Du point de vue de Google, la page de destination est encore plus pauvre en raison de son utilisation du script Java.
Le rapport de pauvreté réel est ensuite masqué via une autre page intermédiaire, comme illustré à la Figure 21, qui est liée à la sous-navigation (rapport de pauvreté à télécharger). Le rapport sera lié au format PDF uniquement à partir de cette page. Malheureusement, cela est rendu disponible via le propre nuage, de plus non exploitable pour Google et n'a donc aucune chance dans les résultats de la recherche.
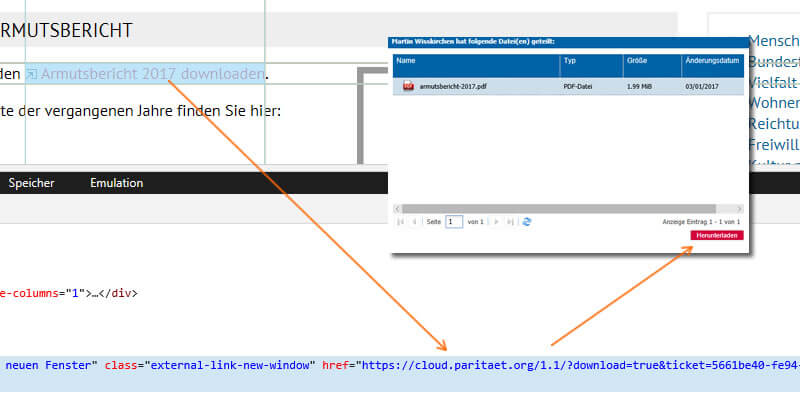
Figure 21: Le PDF fourni via le cloud n'a aucune chance de se classer.
Le fait que le rapport soit délibérément masqué de Google peut être mis en doute et ne serait de toute façon pas utile, comme le montre la recherche d'une portion de texte entre guillemets chez Google (un moyen facile, par ailleurs, de rechercher des doublons).
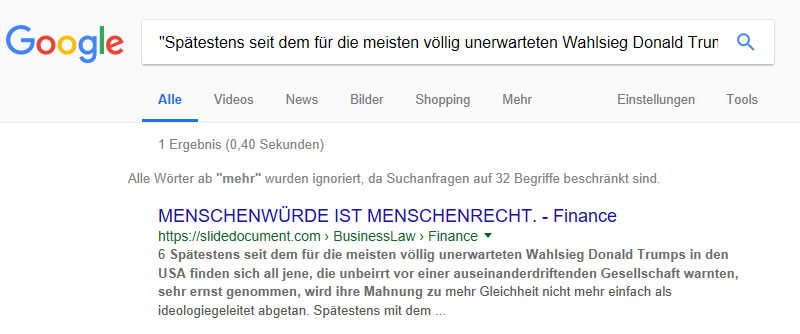
Figure 22: Localisez les doublons dans l'index Google à l'aide de guillemets.
Un résumé des principales découvertes sur http://www.der-paritaetische.de/schwerpunkte/armutsbericht/ pourrait déjà suffire à améliorer le classement. Même la première place serait probablement possible, puisque le seul rapport concurrentiel est le rapport sur la pauvreté du gouvernement fédéral (actuellement numéro 1), qui appelle cela un "rapport sur la pauvreté et la richesse" quelque peu euphémiste.
Conclusion: une analyse sans outil de référencement ne doit pas nécessairement être une mauvaise analyse
Comme le montre l'exemple de la Joint Welfare Association, même sans logiciel de référencement, des informations précieuses peuvent déjà être obtenues pour l'exploitant du site. Bien entendu, cela ne signifie pas que les outils sont superflus, bien au contraire, l’analyse montre également les limites d’une telle approche:
- Pour quels mots clés le domaine reçoit-il actuellement des impressions et des clics?
- Quel volume de trafic les pages traversent-elles Google Search?
- Existe-t-il des problèmes d'indexation?
- Le sitemap contient-il des erreurs?
- Dans quel ordre de grandeur y a-t-il 404 erreurs?
- Où se trouve le lien de domaine et fonctionnent-ils tous?
- Quelle est la longueur des chemins de clic?
- Quelles pages pourraient utiliser ou donner plus de liens internes?
Vous ne pouvez répondre à ces questions et à bien d'autres questions pour une analyse de référencement professionnel à l'aide des données de la console de recherche Google, des robots d'exploration sur la page tels que SEO Expertise et d'autres outils. Mais s’appuyer uniquement sur des outils, ne donne aucune idée de la page analysée et peut en rater beaucoup, ce qui n’est évident que lorsqu’un site Web et un index Google sont affichés.
Surveille, analyse et optimise ton site web avec SEO Expertise FREE!
Allons-y!



