Sommaire
Le principal défi que doit relever Google en matière de recherche sémantique consiste à identifier et à extraire des entités et leurs attributs à partir de sources de données telles que des sites Web. Ces informations sont généralement non structurées et non exemptes d'erreurs. Le Knowledge Graph actuel en tant que centre sémantique de Google repose en grande partie sur le contenu structuré de Wikidata et les données semi-structurées de Wikipédia ou de Wikimedia.
Dans cet article, je souhaite examiner de plus près le traitement des données provenant de sources de données semi-structurées telles que Wikipedia.
J'ai déjà brièvement abordé le traitement des données structurées ici.
Vous pouvez trouver une collection d'articles détaillée sur Knowledge Graph, le référencement sémantique et les entités dans la série d'articles associés,
Traitement des données semi-structurées
Les données semi-structurées sont des informations qui ne sont pas conformes aux normes de balisage générales telles que p. Ex. selon RDF, schema.org … sont explicitement distingués, mais ont une structure implicite. À partir de cette structure implicite, i.d.R. obtenir des données structurées via des solutions de contournement.
L’extraction d’informations à partir de sources de données avec des données semi-structurées peut être réalisée via Extracteur basé sur un modèle être effectuée. Il peut identifier des sections de contenu et en extraire des informations sur la base d'une structure récurrente de contributions.
Le traitement des données semi-structurées en utilisant l'exemple de Wikipedia
Wikipédia ou d’autres sources, en raison de la structure similaire de chaque publication et de la révision continue par les éditeurs, par exemple, Les wikipédiens sont une source d’information très attrayante et sont basés sur le système de gestion de contenu MediaWiki. En conséquence, le contenu est fourni avec des annotations rudimentaires et peut être facilement téléchargé via XML, dumps SQL ou html. Vous pouvez aussi d'ici données semi-structurées parler.
La structure d'un article Wikipedia typique est un modèle de modèle permettant de classer les entités par catégories, d'identifier les attributs et d'extraire des informations pour les extraits et les panneaux de connaissances en vedette. La structure très similaire ou identique des contributions individuelles de Wikipedia dans, par exemple,
- Titre (1)
- Section principale (2)
- Introduction (2a)
- Infobox (2b)
- Texte d'introduction (2c)
- Table des matières (3)
- Texte principal (4)
- Suppléments (5)
- Notes de bas de page et sources (5a)
- Liens supplémentaires (5b)
- Catégories (5c)
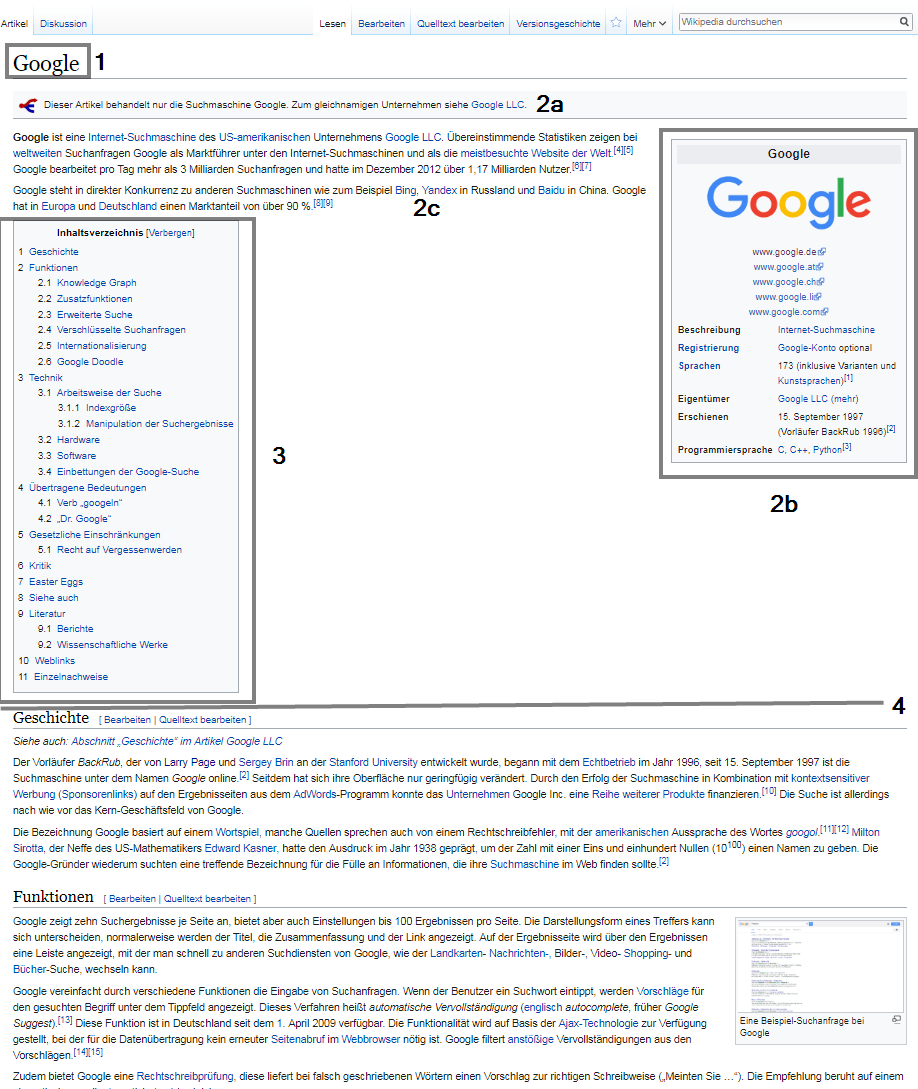

Exemple d'ajout dans Wikipedia en utilisant l'exemple de l'entité "Google"
la titre Chaque publication Wikipedia reflète le nom de l'entité. Dans le cas de titres ambigus, le type est inclus dans le titre pour une délimitation plus claire des autres entités portant le même nom, comme avec le rapporteur pour avis Michael Jordan. Là, le titre est Michael Jordan (dessinateur) pour le distinguer de l'entité populaire du basketteur Michael Jordan.
la Info Box (2b) en haut à droite d'un article de Wikipedia fournit des données structurées sur l'entité respective. la texte d'introduction (2c) peuvent souvent être trouvés dans le panneau de connaissances pour l'entité respective. Plus sur cela plus tard dans ce post.
la liens internes Dans Wikipedia, Google fournit des informations sur les sujets ou autres entités liés sémantiquement à l'entité respective. C'est pourquoi nous utilisons notre propre script Wikipedia dans l'agence depuis plus de 4 ans, qui analyse les liens internes des publications Wikipédia pertinentes.
Comment Google peut utiliser les pages spéciales de Wikipedia
Wikipedia comporte un certain nombre de pages spéciales qui peuvent aider Google à mieux comprendre, grouper et classer les entités.
Pages de liste et de catégorie pour la classification par types d'entités et classes
la Catégoriesqui est associé à une entité dans Wikipedia peut toujours être trouvé à la fin d'un article (voir 5c). Sur le pages Catégorie Vous trouverez un aperçu de toutes les principales catégories, sous-catégories et entités attribuées à cette catégorie.
Les pages de liste (comme ici), telles que les pages de catégorie, fournissent une vue d'ensemble de tous les éléments associés au sujet de la liste.
À travers ces deux types de pages, Google pourrait associer l'entité aux types d'entité et aux classes.
Wikipedia possède le plus grand nombre de types de classes par rapport aux autres grandes bases de connaissances.
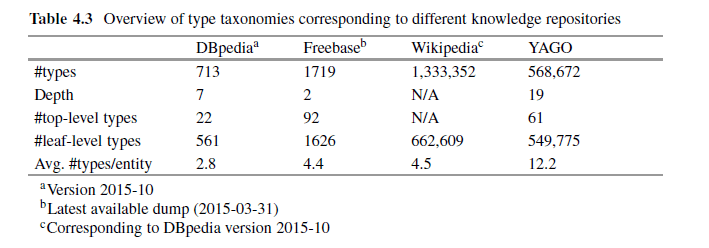
Source: Recherche par entité par Krisztian Balog
Le rôle central que peut jouer Wikipedia dans l'identification des entités et de leur contexte thématique est illustré dans l'article scientifique Utilisation de la connaissance encyclopédique pour la désambiguïsation des entités nommées.
Les relations entre entités pourraient inclure Google et d’autres. À propos des annotations ou des liens dans le produit Wikipedia.
"à annotation est le lien d'une mention à une entité. A jour est l'annotation d'un texte avec une entité qui capture un sujet (explicitement mentionné) dans le texte d'entrée. "
Transfert de pages spéciales pour l'identification de synonymes
Envoi de pages spéciales comme par exemple Celles-ci sur le marketing Internet guident les utilisateurs de Wikipedia vers le concept principal. Dans cet exemple, le marketing Internet est synonyme du terme principal de marketing en ligne. Grâce à ce transfert, Google peut identifier les termes synonymes d'une entité et les associer au terme principal. Cela fonctionne comme une balise canonique dans l'optimisation des moteurs de recherche.
Pages de clarification des termes pour la reconnaissance de multiples sens
Les pages de clarification des termes telles que, par exemple, celui-ci à Michael Jordan donne un aperçu de toutes les entités qui contiennent le nom Michael Jordan. Il s'applique à 5 entités différentes. Notez que les titres des 5 entités sont libellés différemment pour les distinguer clairement.
Cela donne à Google un aperçu des noms d'entités ambiguës.
Bases de données basées sur Wikipedia: DBpedia & YAGO
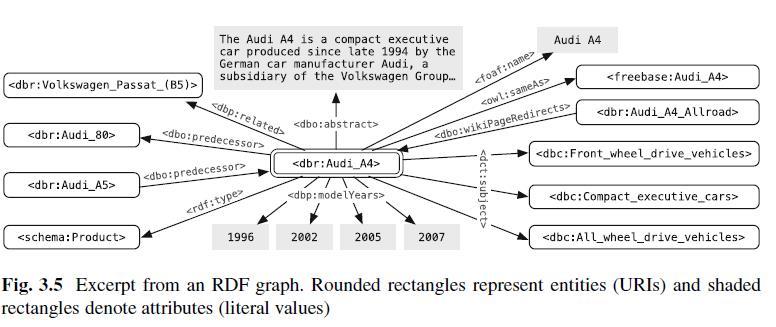
DBpedia est une base de données multilingue basée sur le contenu de Wikipedia ou Wikimedia, qui est mise à jour régulièrement. Les données sont accessibles sous forme de données liées pour chacun via un navigateur, un navigateur RDF ou directement via des clients SPARQL. Le module DBpedia Live met à jour la base de données en temps réel depuis 2016. Voici un exemple d'enregistrement DBpedia pour l'entité Audi A4.
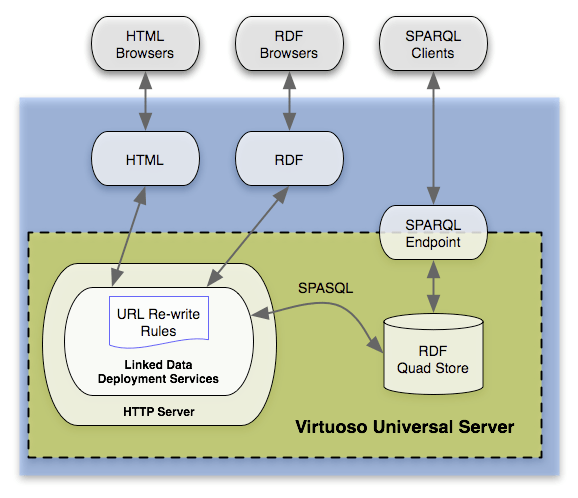
Source: https://wiki.dbpedia.org/about
Dans DBpedia Ontology, les entités sont liées ou représentées sous forme de graphe de connaissances. Dans l'extrait suivant de DBpedia Ontology, les types d'entité (rectangles arrondis) sont liés aux classes d'entité parent via des flèches ascendantes. Par exemple, Les types d'entité Athlètes et Coureurs sont affectés à la classe d'entités "Personne". Les attributs de type et de liaison de classe sont indiqués par les flèches en pointillés.
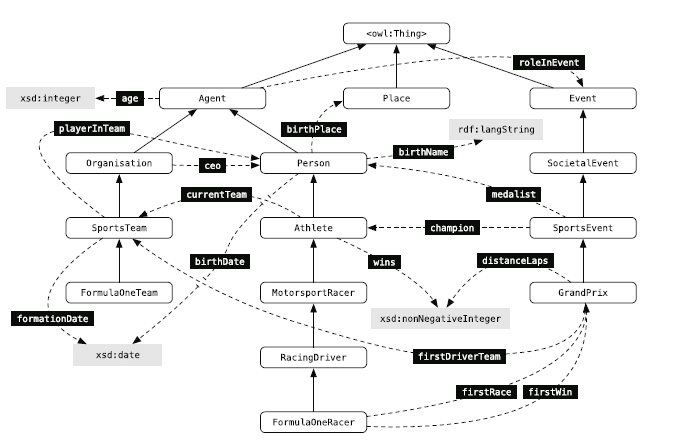
Extrait de DBpedia Ontology; Source: Recherche axée sur les entités – Krisztian Balog
Le tout représente alors une ontologie décrivant les relations entre les classes, les types et donc les entités. L'extraction de données à partir de Wikipedia fonctionne via DBpedia Extraction Framework. Les sources d’extraction incluent les éléments d’un message de Wikipedia répertorié ci-dessus.
YAGO est également une base de données sémantique basée sur le contenu de Wikipedia. Cette base de données est plus axée sur la création de types d’entités et d’ontologies. Pour cela, YAGO établit une correspondance entre les catégories Wikipedia et les classes de WordNet triées hiérarchiquement. Les catégories de Wikipédia n'ayant pas de structure hiérarchique, YAGO représente un atout supplémentaire en termes de structure.
Les éléments de DBpedia et YAGO sont liés via "same-as-links". Ainsi, les deux bases de données peuvent être utilisées par Google en parallèle, sans que des doublons ou des redondances ne se produisent. Des centaines d'autres bases de données sémantiques peuvent être utilisées comme sources parallèlement.
YAGO et DBpedia appartiennent à côté de Wikidata aux plus importants.
Catégorisation des entités sur la base d'attributs clés
Outre les pages de catégories et de listes, Google peut associer des entités à des types d'entités et à des classes d'entités spécifiques. Par exemple, la catégorisation d'objets Google Brevets légèrement plus ancienne pour l'extraction d'informations décrit comment cela peut fonctionner. Les objets décrits dans le brevet peuvent être des entités.
Le brevet décrit comment des objets basés sur des attributs de clé identifiés peuvent être assignés à une catégorie ou à un type. Une fois qu'un objet a un seuil d'attributs de clé caractéristique d'une catégorie, il peut être affecté à cette catégorie.
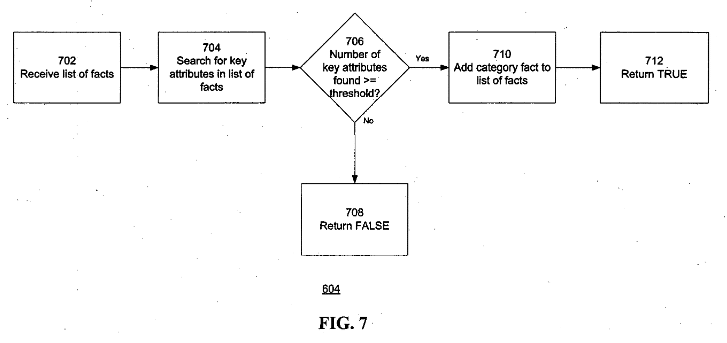
Source: catégorisation d'objets Google Patent pour l'extraction d'informations, US20070203868A1
Par exemple, pour la classe d'entité "livre", un numéro ISBN, l'auteur, l'éditeur et le titre seraient des attributs de clé typiques. Pour un album photo, le nom de l'album, la taille du fichier, l'adresse de la photo, les dimensions, la résolution … seraient des attributs caractéristiques.
Cette méthode s'applique à la fois aux données non structurées et aux données structurées.
Les attributs ou les paires attribut-valeur qui sont pertinents pour une entité ou un type d’entité pourraient être déterminés par une méthode décrite dans le document de brevet Google Extraction de la valeur des attributs de documents structurés.
La liste blanche d'attributs initiale comprend un ou plusieurs attributs initiaux; extraire une largeur d'attributs candidats à partir d'une première collection de documents; regrouper le candidat en fonction de chaque candidat; calculer un score pour chaque attribut unique dans les attributs candidats, le score reflétant un nombre de groupes contenant les attributs uniques et les attributs figurant sur la liste blanche d'attributs initiaux; générer une liste blanche d'attributs développés, la liste blanche d'attributs développés comprenant l'attribut initial et chaque attribut unique ayant un score de seuil; et utiliser la liste blanche d'attributs développés pour identifier les paires valides d'attributs. "
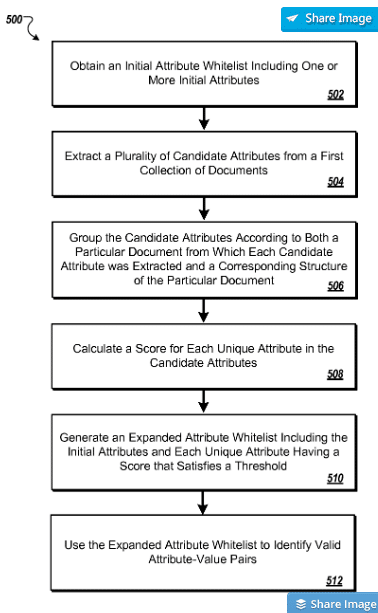
Source: Google Patent Attributes – Extraction de valeur à partir de documents structurés
Cette méthodologie pourrait également être utilisée pour vérifier l'exactitude de certaines valeurs afin de valider la base de données respective.
Les premiers documents mentionnés en tant que source pour une sélection initiale d'attributs pourraient être des données structurées de Wikidata et des données semi-structurées de Wikipedia.
Recueillir des attributs avec Wikipedia comme point de départ
Dans le brevet Google Extraction non supervisée de faits, une méthode est expliquée, ce qui permet de collecter en permanence de nouveaux faits ou attributs concernant une entité dans un référentiel de faits.
Cette méthodologie commence par un document de démarrage à partir duquel une paire d'attributs ou un type d'entité est extraite, telle que "Age (attribut): 43 ans" ou acteur. À partir de l'attribut age ou du type acteur, la classe homme ou personne peut être dérivée.
Lors de l'extraction des données de base sur un module d'importateur à partir du document de départ, il n'y a pas d'évaluation qualitative. Supposons que le document doit être de bonne qualité ou d’exactitude. La validité des informations collectées dépend des données de base. Ici, seules les sources fiables de haute validité, par ex. les Wikipedia sont utilisés.
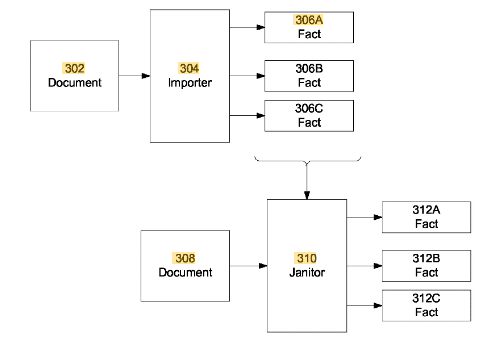
Source: Google Patent Extraction non supervisée de faits, US9558186B2
Dorénavant, d’autres documents peuvent être analysés, lesquels, par exemple, traiter avec les acteurs ou l'entité elle-même. Là, des paires d'attributs / valeurs à correspondance contextuelle supplémentaires peuvent être extraites et attribuées à l'entité dans le référentiel de faits. De cette manière, d'autres attributs clés pour les types d'entité ou les classes pourraient être constamment mis à jour.
Ceci est fait en plus d'un module importateur via un module Janitor, qui s'occupe du nettoyage en double, de la fusion des données, de la normalisation ou de la propreté des données.
Les sources de la recherche initiale peuvent être des publications sur Wikipedia.
Comment les informations sur les entités sont-elles collectées?
L'état actuel de Google semble toujours être celui d'i.d.R. toutes les informations sur les entités à partir de sources de données sont agrégées avec des données structurées conformes à RDF et des données semi-structurées telles que Wikipedia.
Pour collecter des informations sur les entités telles que les attributs, les types d'entité, les classes d'entités et les relations avec les entités voisines, vous devez d'abord créer un profil d'entité. Ce profil est comme dans le post Qu'est-ce qu'une entité? expliqué précédemment avec un nom d’entité et un URI permettant une association unique.
Ce profil reçoit ensuite des informations sur cette entité à partir de différentes sources de données. Voici un exemple de ce à quoi cela pourrait ressembler pour l'entité Audi A4:
Source: Recherche par entité par Krisztian Balog
Dans cet exemple, les informations proviennent de Wikipedia ou de DBpedia et l'entité est liée à la même entité sur Freebase.
Informations provenant de Wikipedia dans Snippets et panneau de connaissances en vedette
Compte tenu en particulier de l'importance croissante des demandes de recherche parlées ou de la recherche vocale, les moteurs de recherche modernes tentent de fournir des réponses immédiatement, sans que l'utilisateur ait à naviguer dans 10 liens bleus sur la première page de résultats de recherche. À cette fin, la signification du terme de recherche doit être identifiée et, d'autre part, les informations pertinentes extraites de sources de données structurées et non structurées. La solution est Récupération d'entité,
La tâche de Récupération d'entité Il s'agit d'identifier les entités pertinentes à une requête écrite ou parlée à partir d'un catalogue et de les sortir triées par pertinence pour la requête de recherche dans une liste. Le résultat d'une réponse nécessite un extrait qui explique brièvement et de manière concise l'entité.
Nous connaissons ce type de description à partir des extraits sélectionnés ainsi que les descriptions des entités dans les panneaux de connaissances, qui sont pour la plupart extraites de Wikipedia ou de DBpedia. Les extraits sélectionnés extraient également des informations de sources non structurées telles que des magazines, des glossaires ou des blogs. Cependant, Google semble utiliser actuellement les descriptions de sources non structurées comme une solution de rechange et préférer les descriptions de Wikipedia.
Vous trouverez ci-dessous une évaluation de Malte Landwehr de mars 2019 à la question de savoir comment les sources d'informations pour Snippets en vedette se répartissent autour du thème du marketing en ligne.
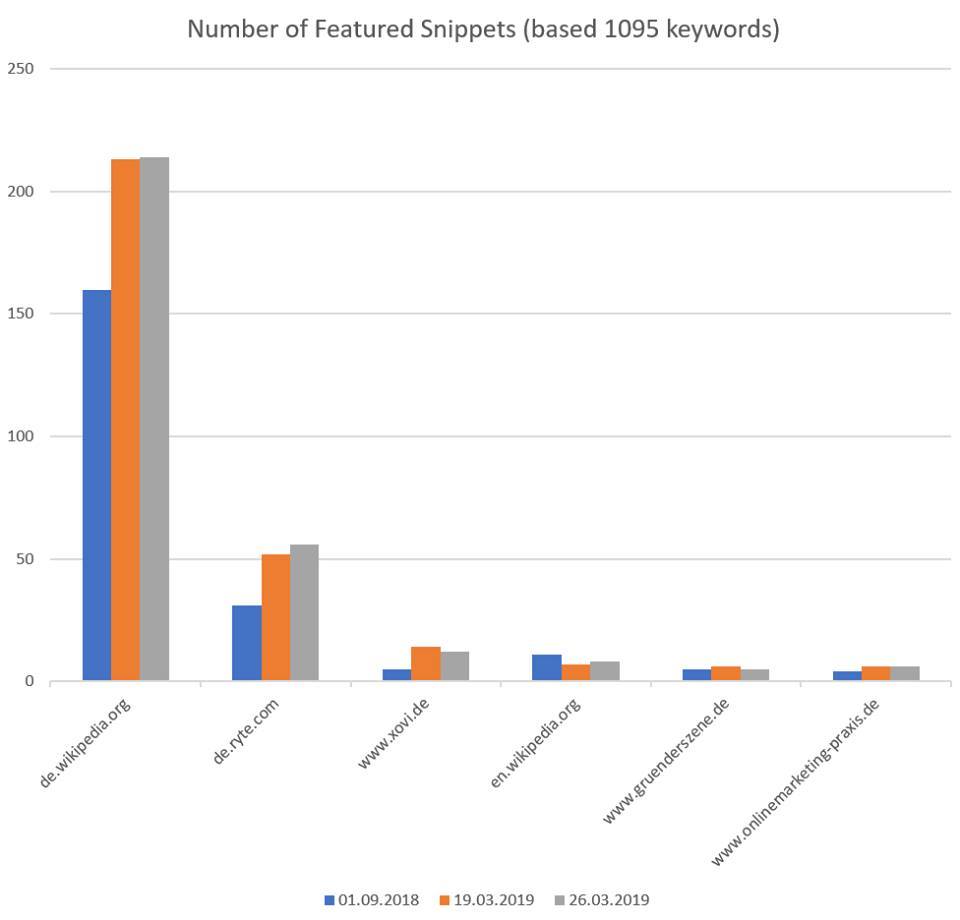
Distribution des sources d'extraits en vedette pour 1095 termes de recherche tirés du marketing en ligne, Source: Malte Landwehr (Searchmetrics)
De temps en temps, on trouve encore des informations, qui ne proviennent pas de Wikipedia comme ici avec l'exemple de la requête de recherche "redirect". Une fois que Wikipedia fournit des informations sur un terme, il est souvent préféré. Dans ce cas, Google semble heureusement pour les collègues de SEO Expertise les entités Redirection et redirection encore "liées" les unes aux autres, même si dans Wikipedia a déjà une page spéciale de redirection.
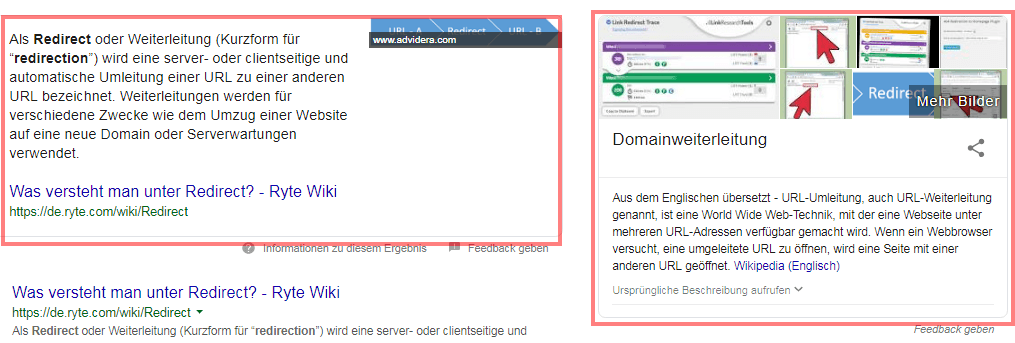
Exemple: extrait de code et panneau de connaissances pour la requête "redirection"
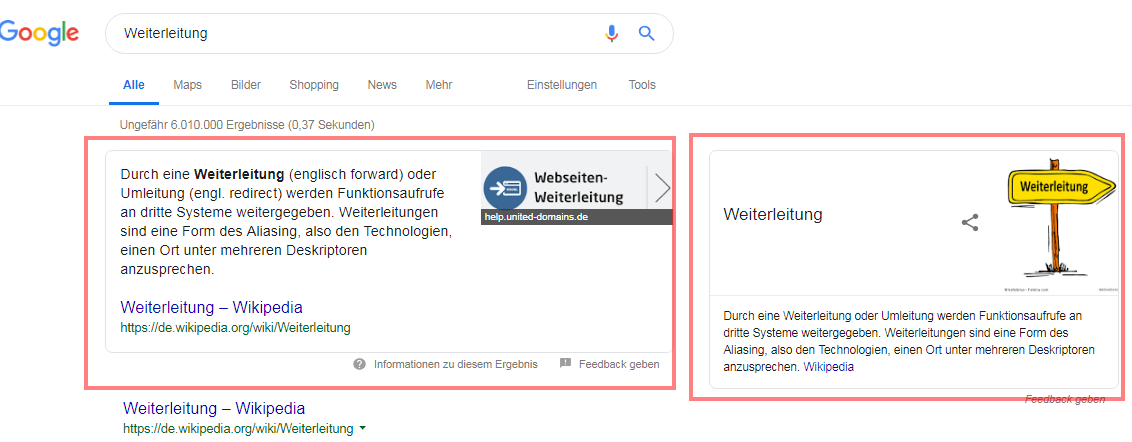
Exemple d'extrait et de panneau de connaissances en vedette pour la requête "transfert"
Google fait actuellement confiance à la plupart des informations de Wikipédia pour alimenter les extraits sélectionnés. Il y a plusieurs raisons à cela. D'une part, en raison de la structure claire de Wikipedia, il est facile d'extraire le texte d'introduction d'une contribution. Ceci décrit le sujet de manière succincte.
Comment Google extrait exactement les informations de textes de sites Web non structurés pour les extraits en vedette est une spéculation. Les conjectures sont nombreuses. Je crois qu’il est principalement lié aux triplets objet, prédicat et sujet figurant dans la section. Mais dans le prochain post de ma série de contributions plus.
La prévalence des informations de Wikipédia dans les extraits proposés indique que Google n'est pas encore satisfait des résultats de l'extraction de données non structurées et / ou n'a pas encore été en mesure de contrôler les tentatives de manipulation.
Wikipedia comme "preuve d'entité"
Le moyen le plus sûr d'être perçu en tant qu'entité est une entrée sur Wikipedia, Wikidata ou la soumission à Google lui-même.Vous en saurez plus à ce sujet dans l'intéressante expérience de soi du collègue Artur Kosch.
Mais Google se réserve le droit de vérifier les entrées et de les supprimer des bases de données si vous ne spécifiez pas suffisamment de sources de référencement dans l'entrée Wikidata. Pour empêcher toute manipulation, une entrée d'au moins une troisième source doit être vérifiée. Au moins c'est ce qu'il semble. Une page Wikipedia ou une entrée Wikimedia semble être une source importante ici.
Alors que Wikipedia attribue les attributs à une entité plutôt en héritage, Wikipedia décrit l’entité dans un texte détaillé. Un article de Wikipedia est une description détaillée d'une entité et, en tant que document externe, constitue une source importante pour le graphe de connaissances.
Par exemple, une référence d'identification unique peut être stockée dans le nœud, une chaîne d'information courte peut être stockée dans un nœud de terminal sous forme littérale, et une description longue peut être attachée à une entité. graphique de la connaissance. Source: "https://patents.google.com/patent/US20140046934A1/fr"
Dans un projet scientifique impliquant un employé de Google, une entité est définie comme une publication Wikipedia.
"à entité (ou concept. sujet) est un article de Wikipedia qui est identifié de manière unique par son identifiant de page".
Les contributions de Wikipedia jouent un rôle majeur dans de nombreuses zones de graphe de connaissances en tant que source d'informations et sont utilisées par Google en plus des entrées Wikidata comme preuve de la pertinence d'une entité. Sans une entrée dans Wikipedia ou Wikidata, aucune boîte d'entité ou panneau de connaissances.
Une entrée sur Wikipedia, cependant, reste dépourvue de la plupart des entreprises et des personnes, car elles manquent de pertinence sociale aux yeux des Wikipédiens. Si votre entreprise ou vous-même êtes suffisamment pertinent pour Wikipedia, vous le saurez dans l'article. Mon entreprise est-elle pertinente pour Wikipedia? ou notre guide détaillé Communicaton sur Wikipedia.
Une alternative judicieuse consiste à créer un profil sur Wikidata. La fréquence des données répétitives et cohérentes sur plusieurs sources fiables facilite la reconnaissance des entités de Google.
Bouton pour réclamer un panneau de connaissances
Avec les entrées d'entité créées par Google ou les auteurs sur Wikipedia ou Wikidata, il est possible de revendiquer votre propre entité, comme expliqué dans l'article Comment revendiquer votre entité sur Google.
Dès qu'un Knowledge Panel est affiché, il est possible de l'utiliser comme Entity Manager (voir la figure à gauche).
La carte d'identité joue ici un rôle particulier. Celles-ci se trouvent dans le texte source du Knowledge Panel.

Carte d'identité du panel de connaissances par Angela Merkel
Dès que vous cliquez sur le bouton, vous accédez à la page Google où vous pouvez utiliser le panneau de connaissances pour l'entité et où l'ID de carte est ajouté en tant que paramètre à l'URL.
Wikipédia et Wikidata sont actuellement (encore) les sources de données les plus importantes
Depuis plus de 10 ans, Google s’efforce de développer de plus en plus une base de connaissances telle que le Knowledge Graph actuel. Ceci est démontré par les innombrables brevets. L’ensemble de la communauté des réseaux montre également un grand intérêt pour l’archivage, la mise en réseau et la reproduction aussi complète que possible des connaissances humaines, comme le montrent les nombreuses bases de données de connaissances principalement honorifiques. Ces bases de données sont maintenant ce que l'humanité avait l'habitude de collecter et de conserver dans d'énormes bibliothèques.
Et Google veut être le gardien numéro un de cette connaissance.
Mais il reste encore beaucoup à faire en termes d’exhaustivité. Des bases de données et des portails comme Wikidata et wikipedia se sont développés en énormes bases de connaissances avec des données structurées et semi-structurées. Des services comme DBpedia et YAGO forme une sorte d'interface pour Google et d'autres instances de traitement.
Wikipedia fournit une très bonne base de connaissances accessible et fiable autour des entités.
Le gros inconvénient: Seules une fraction de toutes les entités et concepts nommés sont décrits dans Wikipedia et Wikidata.
Pour obtenir un aperçu approximatif de toutes les entités, concepts et sujets, ceux-ci ne sont pas suffisants en grande partie comme base de données créée manuellement.
L'objectif doit être de capturer toutes les connaissances affichées sur Internet. Dans ce but, on se trouve dans le champ de tension entre validité et complétude. De plus, la manipulation doit être arrêtée.
Des procédures techniques doivent être développées pour prendre en compte ces points. Ici, le traitement automatisé de sources de données non structurées est tout à fait unique. C'est une autre raison pour laquelle Google continue de stimuler l'apprentissage automatique.
C'est pourquoi mon prochain article traitera du traitement de données non structurées.
J'espère que cet article vous a aidé pour les données semi-structurées, Wikipedia en termes d'entités et le graphe de connaissances. Passez le mot!



