Sommaire
Jusqu'en 2013, les sites Web, leur contenu, leurs mots clés et leurs liens retour constituaient la base du classement Google. Avec le Mise à jour colibri et ça Google Knowledge Graph Google a commencé sa propre transformation en moteur de recherche sémantique. Les entités jouent un rôle central dans cette transformation en termes d’indexation. Pourquoi est-ce ainsi? J'aimerais expliquer dans cette cinquième partie de ma série d'articles sur le thème de la sémantique et des entités chez Google.
Indexation basée sur une entité: de l'index Content First à l'index Entity First
Tout d’abord, j’aimerais aborder un essai très détaillé en cinq parties de la collègue américaine Cindy Krum, sur lequel l’estimé collègue Marcus Tandler a souligné (merci pour cela). C’est le point de départ de mes réflexions ultérieures sur l’indexation et les entités.
Cindy et son équipe ont effectué de nombreux tests et recherches pour prouver que Google est de plus en plus axé sur la compréhension des entités. Cela le met directement en relation avec l'introduction du Mobile First Index. La langue est au centre de leur argumentation. Selon Cindy, Google veut comprendre les entités indépendamment de la langue.
Avec la nouvelle compréhension basée sur l'entité de Google, la langue de l'entité importe moins que – du moins dans certaines langues et pour certaines requêtes. Le contenu peut être regroupé dans l'index en fonction de la compréhension de l'entité, sans être omis, car il est dans la mauvaise langue. Source: https://mobilemoxie.com/blog/query-language-phone-language-settings-physical-location-5-of-5/
Selon les hypothèses de Cindy, le nouvel index mobile est basé sur les informations du graphe de connaissances, raison pour laquelle il est nommé Entity First Index sont. Ici, le contenu ou les documents et entités liés à l'entité principale sont subordonnés à l'entité principale, puis placés dans une hiérarchie d'entités.
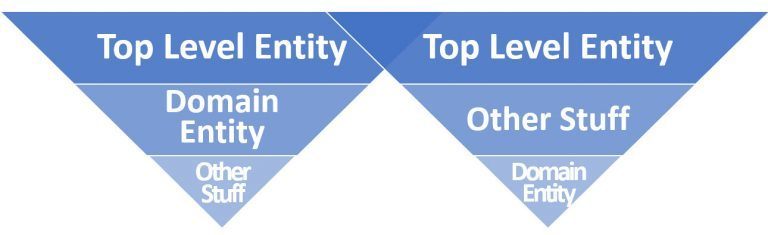
Source: https://mobilemoxie.com/blog/entity-first-indexing-mobile-first-crawling-1-of-5/
Les relations entre les éléments ne sont plus basées sur un graphe de liens, mais sur le graphe de connaissances. Le graphe de liens de la forme précédente ne serait finalement plus modulable en raison du nombre croissant de contenus et de plates-formes différentes.
Continuer à organiser le contenu sur le lien Les graphiques ne sont pas évolutifs pour permettre à Google de comprendre le Web à long terme et sont discutables dans le développement de l'IA et de la recherche multidimensionnelle.
L'exploration et l'indexation constante du contenu en fonction de quelque chose sont faciles à manipuler en tant que graphique de lien et fluide, car elles nécessitent beaucoup de ressources et sont inefficaces pour Google. Et cela ne ferait que croître de manière plus inefficace avec le temps, à mesure que la quantité d'informations sur le Web continuerait de croître.
Enfin, surtout pour les objectifs à long terme de Google, l’ensemble des informations aurait pu être utilisé par leurs systèmes, si seulement ils ne pouvaient pas résoudre le problème du langage … Et c'est pourquoi les entités sont si puissantes!
Surtout sur les appareils mobiles, il convient donc de personnaliser autant que possible le contexte du résultat de recherche correspondant à l'utilisateur.
Cette nouvelle stratégie de catégorisation et de réindexation des informations est basée sur un index centré sur un graphe de connaissances qui utilise les informations provenant d'appareils mobiles pour vous aider. Source Google: https://mobilemoxie.com/blog/query -Langue-téléphone-langue-settings-physique emplacement-5-of-5 /
Un autre avantage de l'indexation basée sur des entités est l'inclusion et l'association de contenu qui n'est pas basé sur des domaines ou des URI, tels que: Apps.
-
Contenu indexé tel que des applications, des cartes, des vidéos, du contenu audio et personnel. (EX: liens profonds de l'application ou profonds du système, tels que les contacts pour les contacts – L'utilitaire de contacts n'est en fait qu'une application.) N'oubliez pas que de plus en plus de contenu consommé avec impatience ne se trouve pas sur des sites Web, même s'il est téléchargé à partir de sites Web. cela pourrait changer avec la hausse des PVA.
Ainsi, même les entités non-domaine d'une entité majeure telles que, par exemple, une marque ou une entreprise dans un index commun.
Les nouvelles stratégies cherchent à fournir des versions audio de contenu uniquement contenu, et à ajouter et traiter tous ces actifs. Ils souhaitent également optimiser les entités autres que les sites Web, telles que les relations Knowledge Graph, afin de s'assurer qu'elles sont correctement corrélées avec le domaine et tous leurs actifs.
De plus, la signification des entités est uniquement indépendante de la langue et les informations sur les requêtes de recherche ayant une intention claire sur l'entité peuvent être traduites en temps réel dans la langue via l'API de traduction et générées sous la forme d'un résultat de graphe de connaissances.
Dans l’ensemble, les entités fournissent une compréhension meilleure et plus profonde de ce qu’elles sont. Une compréhension plus approfondie d’une entité et de ses relations offre à son tour la possibilité de l’utiliser dans n’importe quel langage (si nécessaire), puisqu’à présent, le langage n’a joué qu’un rôle de soutien pour le groupe. requête – comme un modificateur. Quelles que soient l'entente et les relations entre entités, Google apprend dans une langue, en particulier dans les résultats hébergés sur Google, positionnés à zéro, comme le graphique de connaissances … Source: https://mobilemoxie.com/blog/query-language- téléphone-langue-settings-physique emplacement-5-of-5 /
Dans les requêtes de recherche avec une intention de recherche peu claire, Google joue des langues de plus en plus diverses et moins spécifiques.
Dans l'identification de la langue en fonction de la recherche, en particulier la langue de la requête et les paramètres de langue du terminal, le compte Google et les données GPS jouent un rôle important.
Depuis le passage à Mobile-First Indexing, Google s'appuie de plus en plus sur l'emplacement physique (GPS) du chercheur et sur les paramètres de langue du chercheur sur son téléphone ou son compte Google. Il s’agit d’un virage marqué vers plus de personnalisation. Google s’efforce depuis longtemps de …
Le langage est devenu indexé dans le graphique de connaissances. L’association de graphes de connaissances peut rendre l’intention facile à détecter – en particulier pour les films, les personnalités, les images, etc. Nous appelons cela «intention directe» car Google comprend directement la requête en fonction d’une entrée de Knowledge Graph. Mais lors de nos tests, nous avons remarqué que ce n'était pas le cas, mais cela ne semble pas être la même chose.
Il semble qu'ils puissent se comprendre dans une variété de langues, ils sont susceptibles d'être utilisés dans le domaine de l'apprentissage des langues. Source: https://mobilemoxie.com/blog/query-language-phone-language-settings-physical-location-5-of-5/
Mes thèses sur les entités et l'indexation
Je vois les choses un peu différemment que Cindy et je voudrais expliquer cela plus en détail dans cette section. J'ai fait des tests basés sur la recherche de la contribution de Cindy.
Si vous recherchez avec les paramètres du compte "Emplacement = Allemagne & Langue = Allemand" selon le Président, l'image suivante apparaît:
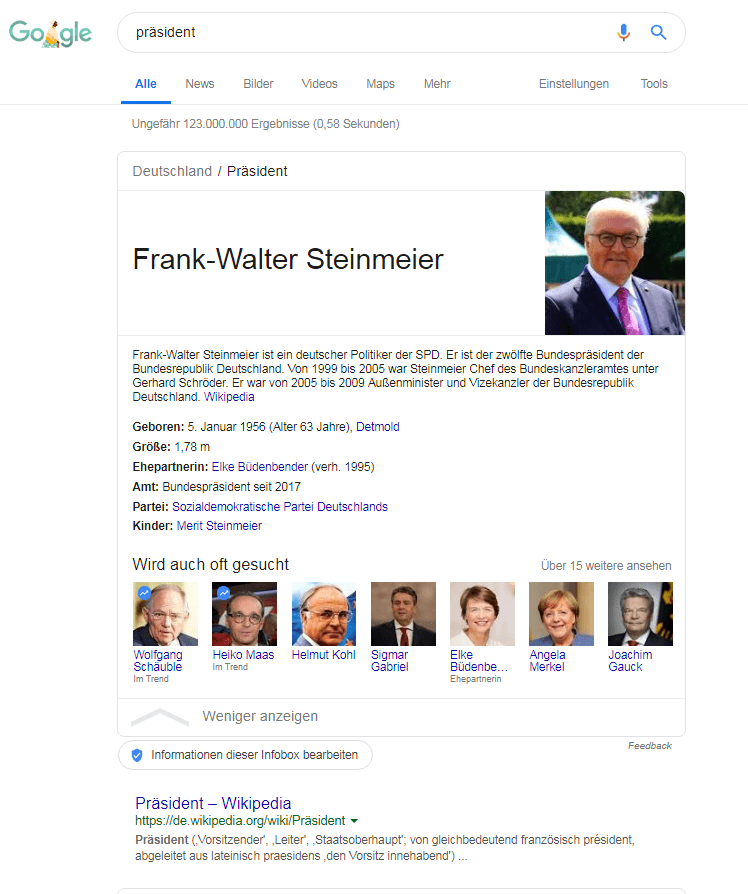
Knwoledge Panel dans la requête de recherche "president" en allemand en allemand
Un panneau de connaissances ou une zone d'entité pour l'actuel président fédéral allemand s'affiche.
Si vous modifiez les paramètres dans "Emplacement = États-Unis et Langue = Allemand", il se présente comme suit:
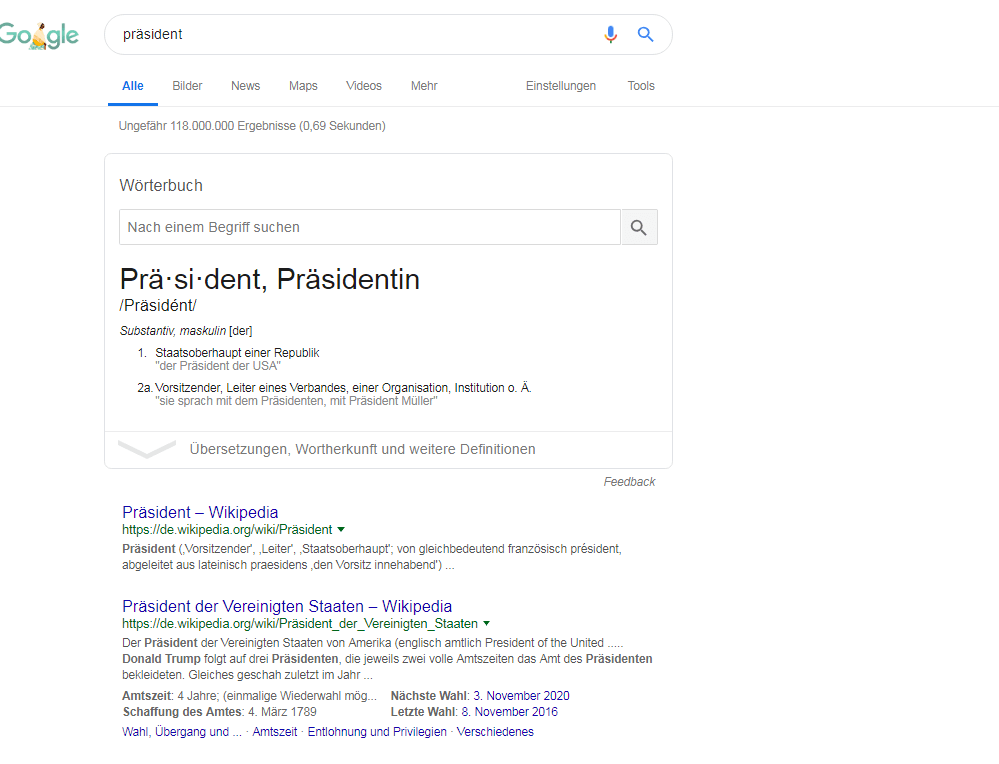
Dictionnaire de la requête "président" aux USA en allemand
Avec les paramètres "Location = United States & Language = English", il se présente comme suit:

Panneau de connaissances de type entité pour la requête "nom d'utilisateur" aux États-Unis en anglais
Dans la requête de recherche allemande "président", Google semble avoir des problèmes pour identifier l'entité appropriée. Au lieu de cela, un panneau de connaissances est fourni pour le type d'entité "président" dans la langue sélectionnée. Donc, au moins Google sait que les termes "président" et "président" sont des noms spécifiques à une langue pour le même type d'entité. Fait intéressant, les SERP sont toujours livrés en allemand.
Mon hypothèse est que Google aimerait émettre des signaux contradictoires en ce qui concerne la localisation, la langue et l'allemand. Aucune entité ni le président actuel ne sont recherchés. Il n'est pas clair s'il est logique de livrer le président allemand ou américain. Google soupçonne que l'on cherche le président des États-Unis. N'est pas sûr et offre donc un raffinement de la requête de recherche sous le panneau de connaissances (encadré: voir les résultats à propos de).
Une autre raison est que, selon Wikipedia de langue anglaise, il existe une deuxième entité, à savoir un modèle de voiture.
Si vous modifiez la langue de la requête de recherche avec les mêmes paramètres, faites alors "président" "président" modifie l'image:
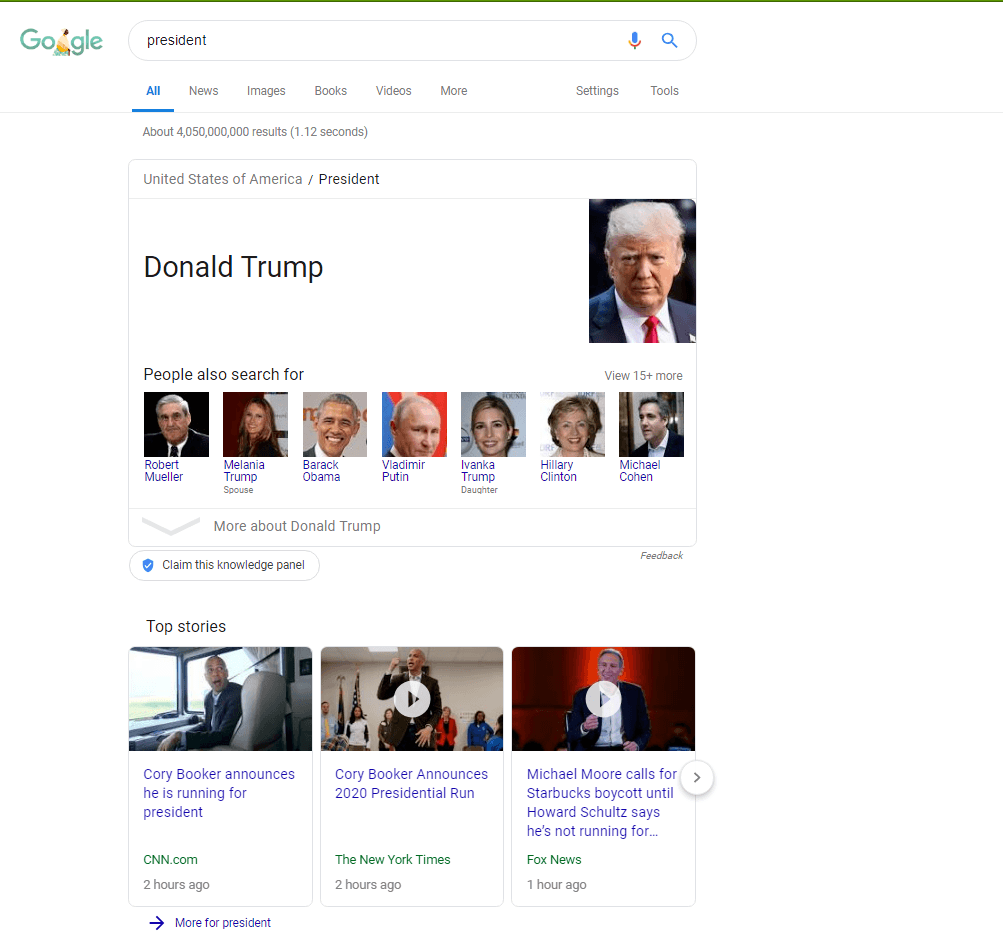
Panneau de connaissances pour la requête "président" aux États-Unis en anglais
Ici, Google sait exactement qu'ils recherchent l'entité Donal Trump en tant que président actuel des États-Unis. Si on cherche "président" avec l'allemand et l'emplacement en Allemagne, il se passe ce qui suit:
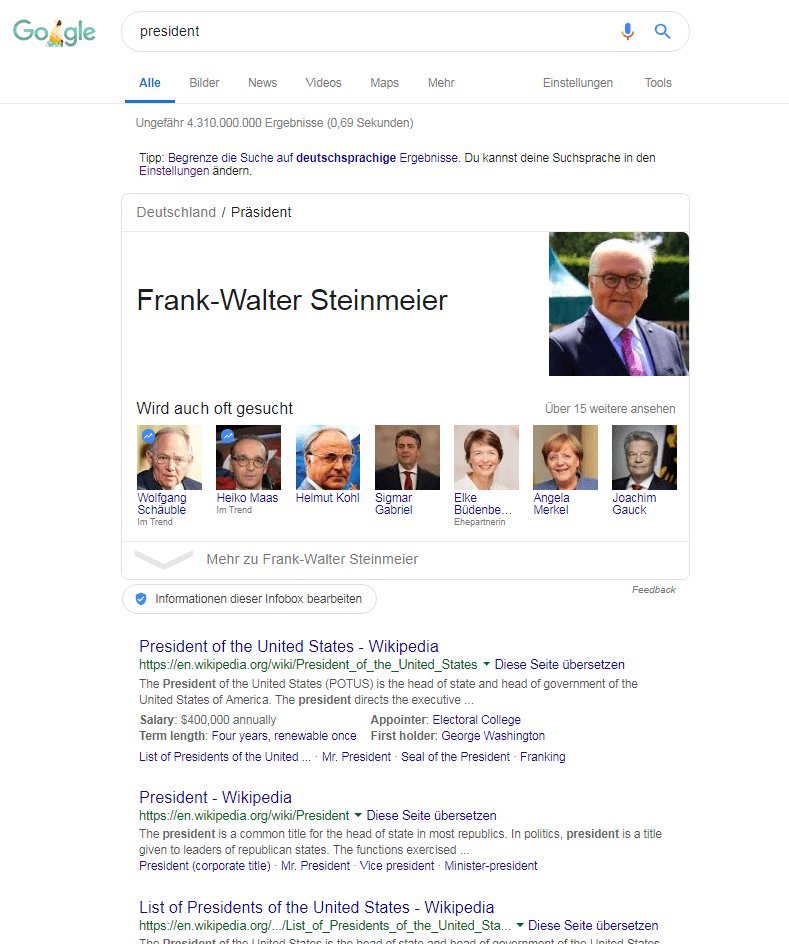
Panneau de connaissances pour la requête de recherche "président" avec l'emplacement Allemagne et la langue allemande
Je trouve cela excitant car ici, contrairement au scénario inverse, sait exactement de quelle entité on parle, malgré le langage contradictoire de la requête de recherche. Cela suggère que dans le cas ci-dessus, la deuxième entité est responsable de ne pas diffuser d'entités dans le panneau de connaissances.
De plus, nous trouvons de nombreux résultats de recherche en anglais dans les SERP.
C'est pourquoi j'ai fait un autre test avec une entité avec un nom unique. Pour cela, j'ai choisi la requête de recherche "têtard".
À l’emplacement Allemagne et langue allemande, le résultat n’a pas l’air très surprenant:

Panneau de connaissances à la requête de recherche "kaulquappe" avec localisation Allemagne et langue allemande
Aux États-Unis et dans la langue anglaise:

Panneau de connaissances à la requête de recherche "têtard" avec l'emplacement USA et la langue anglaise
Ici, Google reconnaît l'entité demandée et la traduit dans la langue sélectionnée dans le graphe de connaissances. L’emplacement choisi ne semble pas avoir beaucoup d’importance, mais la langue, Les résultats de la recherche classique sont basés sur la langue du terme saisi malgré les paramètres du compte.
A partir de ces considérations, différentes thèses peuvent être dégagées:
- l'index de contenu classique et l'index d'entité ou le graphe de connaissances, à partir desquels le panneau de connaissances est rempli d'informations, fonctionnent indépendamment l'un de l'autre. Bien que les résultats de la recherche classique soient fortement basés sur le terme entré dans la recherche, la base de connaissances utilise comme critère les paramètres de langue correspondants du compte Google. Cela ne serait pas conforme à l'hypothèse de Cindy selon laquelle il est actuellement conforme à un seul indice entité-premier. Il semble y avoir au moins deux indices.
- Une autre hypothèse est que Google peut s’ajuster aux intentions de recherche de l’utilisateur dans le panneau de connaissances via l’approche entité-première, malgré les signaux contradictoires de la langue de la requête de recherche et de la langue ou du pays dans les paramètres du compte. Cela ne fonctionne pas pour les résultats de recherche classiques.
- Si, en raison de noms d'entités ambigus, Google ne sait pas quelle entité l'utilisateur recherche, Google suggérera diverses améliorations de la recherche permettant une interprétation claire de la requête ou de l'entité de recherche.
L'importance de l'API de traduction est similaire à celle de Cindy. Cependant, je ne vois pas de lien direct entre l'introduction du Mobile First Index et Cindy.
Selon une récente déclaration de Google, le graphe de liens semble toujours jouer le rôle central dans le classement, pas le graphe de relations entre entités, comme le suggère Cindy.
Dans un récent Webmaster Hangout, John Müller a déclaré que les sites Web problématiques peuvent être classés comme problématiques en raison de leurs liens les uns aux autres, mais pas parce qu'ils appartiennent à une personne ou à une organisation identique.

Traduit, cela signifie qu'il n'est pas déterminant à quelle entité les sites Web doivent être attribués, mais s'il existe un lien entre ces sites. Cela réfuterait la thèse de Cindy selon laquelle le graphe de liens est remplacé par le graphe de relations d'entités.
Mais dans l’affirmation de base, les entités jouent un rôle central dans l’indexation et le classement que je partage depuis un certain temps, quel que soit l’indice Mobile First.
Pour moi, le lancement de la mise à jour Hummingbird a été le point de départ de ce développement, avec lequel Google a officiellement annoncé l'introduction de la recherche sémantique et qui a permis de mettre en avant le graphe de connaissances et les entités.
Le graphique de connaissances est l'index d'entité de Google, et je pense qu'en plus du graphique de connaissances, il existe également un index de contenu classique. Il serait possible d’avoir une interface dans le contenu et les entités dans un Entité-premier indice être fusionné. Cependant, je ne le vois pas dans les observations ci-dessus.
Plus probablement, une interface échange des informations entre l'index de contenu classique et le graphe de connaissances.
Cette interface de contenu d'entité vise à découvrir
- Si les entités se produisent dans une entité de contenu
- s'il y a une entité principale dont le contenu agit
- à quelle ontologie ou ontologies l'entité principale peut être assignée
- à quel auteur ou entité le contenu doit être affecté
- dans lequel relation, les entités apparaissant dans le contenu sont liées les unes aux autres
- quelles propriétés ou attributs doivent être affectés aux entités
Voici à quoi cela pourrait ressembler:
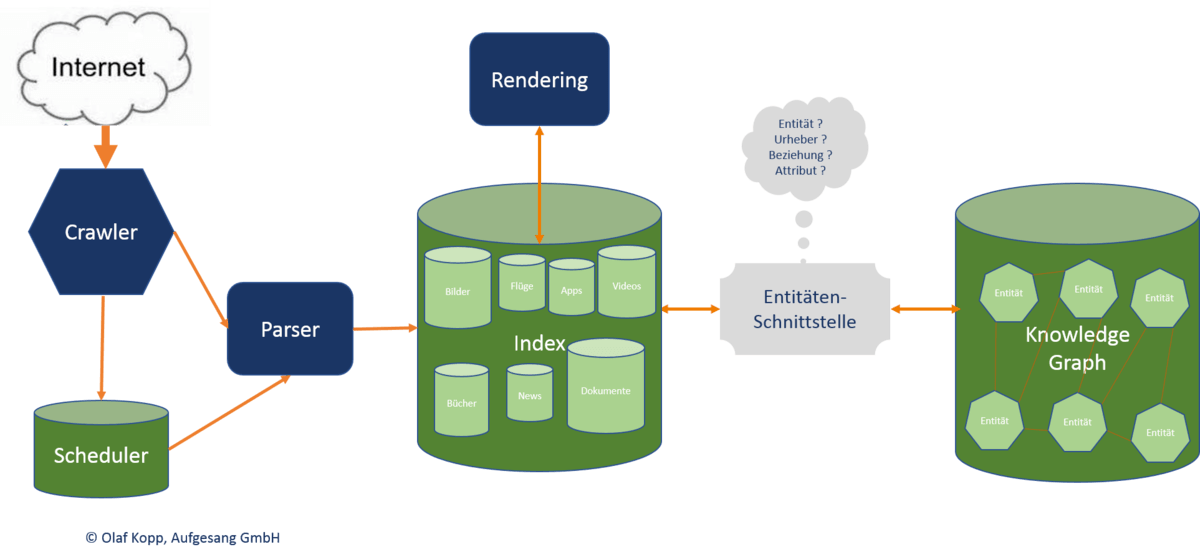
Exploration et index possibles à l'âge des entités (cliquez sur l'image pour l'agrandir)
Dans certains brevets, Google est également toujours écrit par une base de données d'entités qui existe en plus d'un index de recherche. Cette base de données d'entités est évidemment le graphe de connaissances en termes de Google.
Comme indiqué dans l'agrégation de données de la base de données d'entités de brevets Google:
une base de données d'entités stockant un graphe de relation d'entité représentant des éléments dans l'environnement de virtualisation,
par un nœud de type entité dans le graphe de relation d'entité,
les relations entre les éléments sont représentées par des arêtes entre les nœuds, et
Les informations sur chacun des nœuds de type entité sont accessibles via une interface de requête.
De même, le graphe de connaissances est également décrit officiellement par Google. Il est également intéressant de noter ici que les types d’entités sont appelés noeuds et non les entités elles-mêmes.
Le brevet décrit que les relations entre les types d’entités, les attributs respectifs et les statistiques historiques sont utilisées pour la sélection des entités à livrer dans les résultats de la recherche. Voici une illustration de ce à quoi un tel graphe d'entité pourrait ressembler:

L'idée qu'une entité principale, par exemple Entité de niveau supérieur telle que une personne ou une entreprise possède diverses sous-entités telles que, par exemple, Des sites Web, du contenu ou des applications sont affectés à la recherche de l'impulsion la plus excitante du message de Cindy. Cette approche peut également être trouvée dans les nœuds de classement de brevets Google dans une base de données liée basée sur l'indépendance des nœuds à partir de 2013. Elle indique:
générer un ou plusieurs groupes de nœuds affiliés à partir du
où les nœuds affiliés, de chaque groupe de nœuds affiliés, représentent un ou plusieurs des éléments suivants:
appartenant à une entité commune, ou
contrôlée par l'entité commune;
La figure suivante du brevet clarifie ce que l'on veut dire:
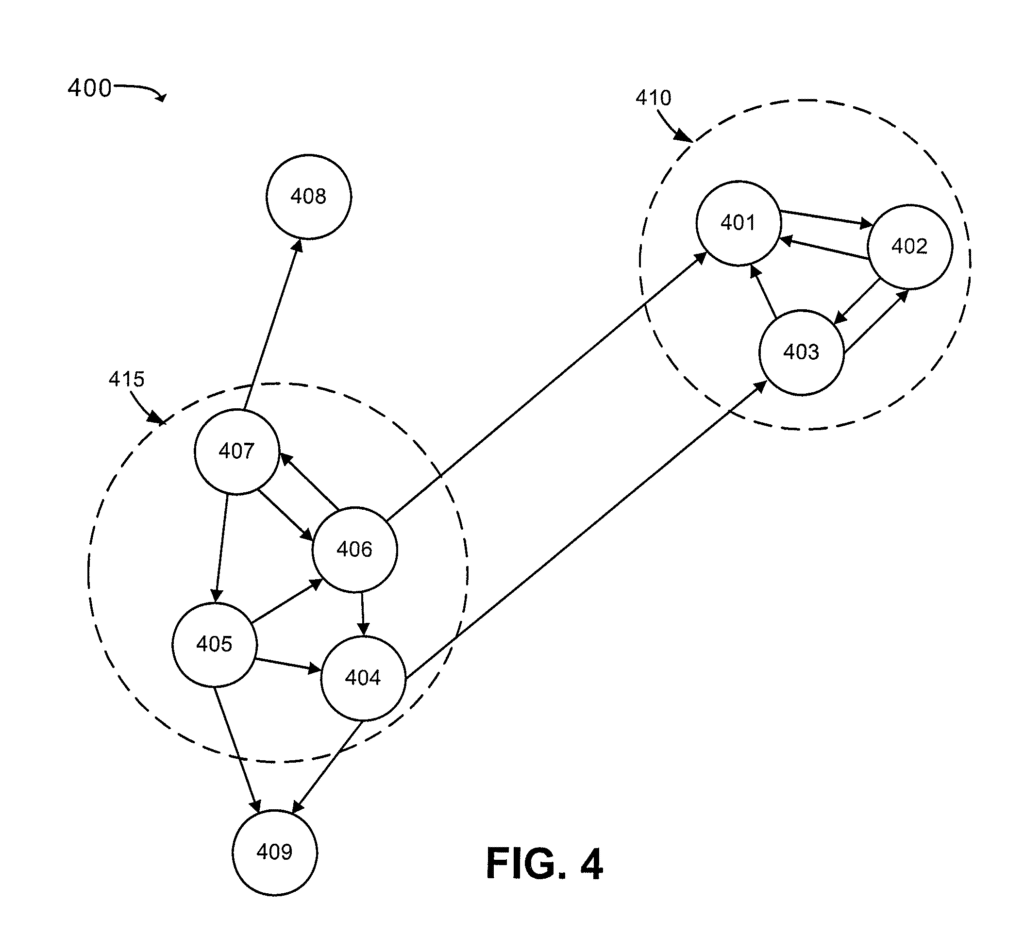
Entités en cluster
Les éléments 415 et 410 représentent des grappes de différents nœuds, par ex. Documents ou sites web. Ces clusters sont formés en raison des liens entre les nœuds ou lorsqu'il est clair que les nœuds sont sous le contrôle de la même organisation ou entité.
En d'autres termes, composant de classement 340 peut déterminer que plusieurs nœuds doivent être regroupés lorsqu'il existe une forte probabilité que tous les nœuds soient contrôlés par une seule entité.
Les critères cruciaux pour le regroupement de nœuds peuvent inclure la paternité, la structure du graphène, la similarité du contenu, des informations sur les ensembles manuels, par exemple Soyez méta-données. De cette manière, des éléments tels que des publications individuelles et d’autres formats de contenu, domaines, applications, etc., telles que des entités telles que Attribuer des entreprises ou des personnes. Les informations WHOIS seraient également possibles, mais selon le GDPR, ce n'est plus aussi facile.
Les avantages d'un index basé sur les entités
Étant donné que les entités ont presque la même signification dans tous les pays et dans toutes les langues, un index basé sur les entités constitue un avantage considérable pour des raisons d'efficacité. Un lion en Angleterre a la même signification qu'en Allemagne. Seul le nom est différent selon la langue nationale. Leo (allemand), lion (anglais), Leon (espagnol) … a la même signification dans tous les pays et dans toutes les langues.
Il s'agit de sens et non de langage. Cela simplifierait grandement l'interprétation de la langue par Google. Une fois que Google a compris le sens d'une entité, il est reconnaissable dans toutes les langues.
Par exemple, Google peut pour un graphe de connaissances, fournissez la description de l'entité de la langue utilisateur appropriée, que lion ou lion soit entré ou non. Surtout dans les langues Google n'est pas encore à l'écran a un gros avantage. Le post de Cindy contient quelques tests intéressants.
Aussi pour la recherche d'image un grand avantage. Ainsi, Google pourrait, quelle que soit la langue, la même sélection d’image pour les recherches lion, leon … livré. Surtout avec des images, peu importe si les images sont maintenant en allemand, anglais ou Site espagnol.
Cela fonctionne évidemment actuellement mais pas encore. Cela peut également être lié au fait que Google n’est pas aussi reconnaissant qu’ils le voudraient. La reconnaissance d'image dépend toujours trop d'informations telles que l'environnement de texte, les balises title et alt. Et cette information sine principalement dans la langue respective de la source d'image.

Principales sources d'images allemandes pour la requête de recherche "lion"

Principales sources d'images allemandes lors de la recherche de "lion"
Défis d'indexation par entité
Je pense que nous commençons à ressentir l’impact des SERPs, car Google tarde à comprendre le sens des entités individuelles. La compréhension des entités se fait par le haut pour la pertinence. Et les entités les plus pertinentes sont enregistrées dans Wikidata ou Wikipedia.
La grande tâche sera d'identifier et de vérifier des entités inconnues. Vous pouvez être curieux. Les critères que Google vérifie pour l'inclusion d'une entité dans le graphique de connaissances ne sont également pas clairs.
Selon ma question à John Mueller, quelque chose devrait venir ou travailler sur une possibilité plus facile de créer des entités pour tout le monde.
Je pense que nous n'avons pas de réponse claire. Je pense que différents algorithmes le testent, puis que nous prenons différents critères pour résumer, séparer et reconnaître quelles sont les entités vraiment distinctes, qui ne sont que des variantes ou des entités moins distinctes … Mais en ce qui me concerne C'est quelque chose sur lequel nous travaillons pour étendre le tout et j'imagine que ce sera aussi plus facile à afficher dans le graphique de connaissances. Mais quels sont exactement ces projets, je ne les connais pas maintenant.
Je pense que John aborde ici les développements que j'ai décrits dans l'article Comment revendiquer votre entité sur Google. Peut-être qu’à l’avenir il sera possible de soumettre de nouvelles entités à la revue via le processus décrit afin de capturer d’autres entités que celles de Wikipedia et Wikidata.
En outre, je pense qu’ici l’apprentissage automatique ou l’API de traitement du langage naturel joueront un rôle crucial dans ce processus, qu’il soit automatisé ou semi-automatisé.
Cependant, je recommande fortement de prendre le temps de lire la série d'articles de Cindy Krum.