Sommaire
L'implication de Google dans les domaines de l'apprentissage automatique et de l'intelligence articulaire est considérable, comme dans l'article Quelle est la signification de ML pour Google? expliqué. L'influence sur le référencement est également clairement identifiable dans la contribution Quel sens a l'apprentissage automatique pour le référencement? Les experts osent regarder vers l'avenir.
La reconnaissance des images ainsi que l'identification des textes et leur signification jouent un rôle important pour Google.
Les temps de non lisibilité des textes en images sont-ils bientôt révolus? Cette question que je me suis posée en suivant l'actualité dans le domaine de la reconnaissance d'images et de textes de Google.
À la fin de cet article, j'ai compilé une sélection de brevets Google relatifs à la reconnaissance et à l'interprétation d'images et de vidéos.
L'apprentissage automatique et la disponibilité de données d'apprentissage appropriées rendent le développement des systèmes existants très rapide. La question est de savoir à quel point les produits de Google sont avancés et peut-on déduire de l'utilisation possible du robot d'exploration de Google?
Difficultés de lisibilité des textes en images
Le développement de l'identification et de l'interprétation des textes dans les images ne pose pas de problème si ce n'est la faisabilité ou les brevets, mais l'exécution sans erreur et le traitement ultérieur significatif. Parce qu'il faudrait inclure une capacité d'abstraction intelligente, que Google est en train de former.
Le problème à résoudre dans le cas de la reconnaissance de texte dans les images est la distinction entre texte réel et texte supposé, tel que des structures ayant la forme d’une lettre ou d’un chiffre et, dans le pire des cas, se trouvant toujours à proximité immédiate de caractères réels. Pour le robot d'exploration, cela signifierait qu'il devrait distinguer correctement le texte des éléments, les transcrire et les attribuer à l'image en tant que balise, créer des liens de site ou identifier le véritable créateur du site Web. Avec une empreinte et une image simple, très peu d'abstraction est nécessaire et la mise en œuvre fonctionne très bien, mais comment les différents types d'image se séparent-ils?
Exactement sur ce point, il serait possible de le réaliser à nouveau par apprentissage automatique et par correspondance avec des images similaires déjà vérifiées. Il serait également possible de faire correspondre les données transcrites avec des mots-clés ou des adresses typiques, par exemple. être en mesure de nouer des relations avec les entreprises et d’éliminer les erreurs mineures dans l’enquête
Un autre problème de reconnaissance de texte dans l'image est la pondération de la balise générée automatiquement et la classification thématique automatisée. Ce processus, appelé généralisation, décide de la pertinence du texte par rapport au motif de l'image et de la relation sémantique entre le texte et l'image. De même, la comparaison avec l'inscription sur les images et les mots-clés manuscrits devrait être prise en compte afin de déterminer la pertinence si nécessaire. Dans le pire des cas, votre photo de vacances sur la plage serait associée au nom du fabricant de poubelles local. Dans la reconnaissance d'image et la classification automatique, il y avait déjà un scandale explosif cette année.
Ce serait plus simple avec des images telles que des infographies détaillées qui fourniraient suffisamment de texte pour les classifications Google ou des données telles que des adresses ayant une structure relativement fixe. Dans ce numéro, Web 3.0 jouera un rôle clé en termes de reconnaissance d’images et d’objets, comme l’API Cloud Vision et l’apprentissage en profondeur. La publication de l'API de Google et son utilisation dans les applications entraînent une quantité encore plus importante de données et d'applications multifonctionnelles. Avec la confirmation de la notation calculée et des classifications d'utilisateurs, le processus peut être affiné. De cette façon, les systèmes existants continuent d'évoluer.
En résumé, donc, non seulement la question de la faisabilité finale se pose, mais également ce que Google fera en définitive à partir des données ainsi collectées ou ce que Google considère comme une utilisation utile des données. En fin de compte, il s’agit de générer une valeur ajoutée tangible pour les utilisateurs, ce qui ne fonctionne qu’avec les délais et le maillage de plusieurs systèmes. Pour tester les pensées théoriques d'un produit réel, voici une petite enquête.
Enquête: reconnaissance de texte par échantillonnage dans l'application Google Traduction
Pour tester le produit Google le plus sophistiqué dans le domaine de la reconnaissance de texte à partir d'images, j'ai pris quelques variantes d'image et vérifié l'application de Google Traduction pour son développement et ses vulnérabilités. Il convient de noter que le traducteur de Google a été délibérément détourné par moi, l’utilisation conforme en est bien sûr une autre. L'application utilise des données d'apprentissage automatique et les combine en temps réel avec un système de réalité augmentée, comme vous le voyez ici.
Afin d’exclure les problèmes de reconnaissance de la typographie du mot, j’ai sondé le lettrage. Le traitement est facile. Cela montre les énormes capacités de reconnaissance de texte dans la variation des polices. Cependant, les manuscrits sont exclus ou non pris en charge par Google. Il convient de noter que Google fournit une large gamme de typographies via Google Fonts, fournissant ainsi des données d'apprentissage parfaites pour la reconnaissance de texte. À cet égard, le résultat n’est pas surprenant et devrait donner de bons résultats, même pour les polices plus complexes.

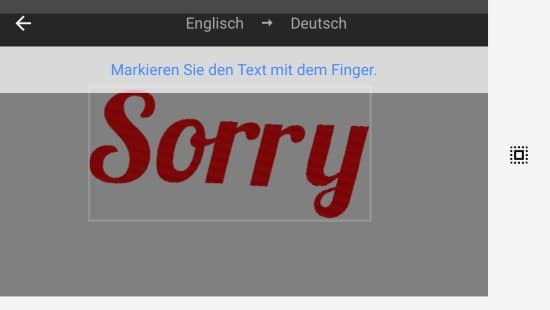
Pour vérifier la manière dont l'alignement du texte affecte la reconnaissance, j'ai fait pivoter l'image pour qu'elle corresponde au mot "Désolé". On peut voir que l'étendue détectée dans le "WE`RE CLOSE" précédemment reconnu stagne et que le message "Désolé" n'est toujours pas reconnu. Cela montre que l'environnement du texte a une signification énorme, les valeurs de couleur de la typographie, malgré le contraste rouge, ont moins d'importance dans ce cas, et une modification de l'orientation dans un contexte d'image complexe influence fortement la reconnaissance du texte. Une autre hypothèse tirée de cet exemple est que la forme ou la structure a une importance plus grande que le contraste car la lettre "désolé" n’est pas reconnue malgré des résultats positifs antérieurs. En outre, un artefact s'est glissé dans le S de "Désolé" au niveau de "Fermé", le numéro 8 a été reconnu et inséré. Cela montre que cela peut également donner lieu à des malentendus arbitraires, bien qu'il n'y ait apparemment rien de semblable au chiffre 8 ou que nous percevrions comme tel.
Le dernier exemple est une infographie sur le processus de référencement de notre agence.
Collection de brevets Google sur la reconnaissance vidéo et image
Une sélection correspondante des brevets de Google:
À Philippe
Philip étudie la gestion de l'information en mettant l'accent sur l'informatique et les médias audiovisuels. Il a rejoint l'équipe en tant que stagiaire en 2015 et travaille comme assistant dans le domaine de la recherche de mots clés et du développement Web.
- Google peut-il lire ou reconnaître des textes sur des images? – 15 décembre 2015