Exploitez Internet comme votre propre source de données et automatisez plus de 100 tâches de vente, de marketing ou de recherche sur le pilote automatique grâce à Hexomatic.
Créez vos propres règles de scraping Web pour transformer n’importe quel site Web en feuille de calcul ou en API JSON.
Hexomatic facilite la récupération de produits, d’annuaires, de prospects et de listes à grande échelle avec une simple expérience pointer-cliquer. Aucun codage ou logiciel complexe requis.
Trouvez de nouveaux prospects pour n’importe quel secteur, découvrez des profils de messagerie ou de réseaux sociaux, traduisez du contenu, enrichissez vos prospects avec des données de pile technologique, obtenez des estimations de trafic à grande échelle et plus encore.
Hexomatic propose plus de 100 automatisations prêtes à l’emploi que vous pouvez déployer en quelques minutes.
Récupérez les données de n’importe quel site Web en quelques minutes
Automatisez la collecte de données fastidieuse grâce à notre générateur de règles de scrap visuel pointer-cliquer.
Hexomatic propose une détection automatique des champs et une pagination pour vous aider à capturer les produits, les listes et les données de tarification en quelques minutes.
Elles peuvent être combinées et enrichies à l’aide d’automatisations prêtes à l’emploi.
Faites d’Internet votre propre source de données avec notre moteur de scraping de sites Web
Accédez aux automatisations natives, communautaires et premium.
Exécutez vos recettes de grattage à la demande ou planifiez-les pour obtenir des données fraîches et précises qui se synchronisent nativement avec Google Sheets ou peuvent être utilisées dans n’importe quelle séquence d’automatisation. Hexomatic fonctionne 24h/24 et 7j/7 dans le cloud, ce qui vous permet de vous attaquer à des projets de toute taille sur pilote automatique. Chaque plan est livré avec un quota de renouvellement mensuel de demandes de pages (une demande est faite par page récupérée) et inclut une rotation IP gratuite en standard pour une expérience sans frustration.
Plus de 100 automatisations intégrées prêtes à l’emploi pour dynamiser votre flux de travail.
Effectuez des tâches chronophages et enrichissez vos données en quelques minutes grâce à nos automatisations prêtes à l’emploi. Trouvez des coordonnées, des types de documents spécifiques, convertissez des images, extrayez des données SEO, détectez la pile technologique, effectuez des requêtes WHOIS et plus encore.
Commencez avec une recette de scraping, CSV ou Google Sheet et combinez des automatisations pour effectuer des tâches sur vos données à grande échelle.
Exploitez les automatisations premium pour tirer parti des services tiers
Trouvez des prospects à l’aide de la recherche Google ou de Google Maps en quelques clics sans avoir à créer votre propre recette de scraping, puis combinez d’autres automatisations pour trouver les coordonnées, détecter la pile technologique ou même estimer le trafic pour chaque prospect en quelques minutes.
Obtenez des données Amazon, exploitez les traductions automatiques de classe mondiale de Google Translate ou DeepL et obtenez des informations sur le trafic de n’importe quel site Web directement dans votre flux de travail, sans API ni abonnement supplémentaire requis.
Créez votre flux de travail parfait en quelques minutes
Démarrez des flux de travail à partir d’une liste de mots-clés, d’URL, d’un fichier CSV ou de toute règle de scrap de site Web.
Ensuite, enchaînez des recettes de scraping et des automatisations supplémentaires pour effectuer des tâches sur vos données.
Les équipes commerciales peuvent trouver et enrichir des prospects sur le pilote automatique, économisant ainsi des heures de travail manuel.
Les équipes marketing peuvent exploiter de nouveaux marchés, de nouvelles sources de données et traduire des créations à grande échelle grâce à la traduction automatique.
Les équipes SEO peuvent exécuter des extractions de données complexes à grande échelle.
Les équipes de saisie de données et de recherche peuvent créer leurs propres robots de scraping et tirer parti d’automatisations prêtes à l’emploi pour capturer et traiter des données à grande échelle.
En fait, Hexomatic peut aider à peu près n’importe quelle tâche chronophage à l’échelle de l’industrie via une simple plate-forme d’automatisation du travail sans code, pointer et cliquer qui fonctionne 24h/24 et 7j/7 dans le cloud. Aucun logiciel à installer ou compétences en codage requises. Une fois qu’un flux de travail est exécuté, vous pouvez exporter vos données au format CSV, vers des feuilles Google ou synchroniser automatiquement vos données vers une feuille Google en direct.
Hexomatic pour le commerce électronique
Les données sont un énorme avantage pour les entreprises de commerce électronique. Hexomatic peut vous aider à transformer n’importe quel site Web en tableur ou en API pour développer votre entreprise et déléguer les tâches chronophages.
Surveiller les prix des concurrents
Recette de grattage Google Sheets
Collectez des descriptions de produits et des images à grande échelle
Recette de grattage Export CSV
Recueillir les avis clients des concurrents
Extracteur XML Scraping recette Schema scraper Export CSV
Hexomatic pour les équipes commerciales
Si votre entreprise vend à d’autres entreprises, obtenir de nouveaux prospects ciblés est le carburant de votre fusée. Trouvez des prospects pertinents pour à peu près tous les créneaux ou secteurs sur le pilote automatique avec Hexomatic.
Trouvez de nouveaux prospects à l’aide de la recherche Google
Automatisation de la recherche Google Extracteur d’ e- mails Extracteur de médias sociaux Découverte de la pile technologique Google Sheets
Trouvez de nouveaux prospects en grattant les participants à la conférence et les sponsors
Recette de grattage Scraper d’e- mails Scraper de réseaux sociaux Balises méta SEO CSV
Trouvez des entreprises locales à l’aide de Google Maps
Automatisation de Google Maps Scraper d’ e- mails Scraper de médias sociaux Découverte de la pile technologique Google Sheets
Grattez les répertoires pour trouver des prospects dans n’importe quel créneau
Recette de grattage Grattoir d’e- mails Grattoir de réseaux sociaux CSV
Hexomatic pour les équipes marketing
Si vous êtes un spécialiste du marketing, du référencement ou un hacker de croissance, vous savez que la croissance consiste à exploiter les données, les réseaux et les opportunités existants.
Rétro-ingénierie du trafic et des stratégies d’acquisition de vos concurrents
Balises méta SEO pour la recherche Google Informations sur le trafic CSV
Détectez la pile technologique de n’importe quel site Web à grande échelle
Découverte de la pile CSV Tech
Obtenez les détails WHOIS et l’expiration du domaine des domaines en masse
Analyseur CSV WHOIS CSV
Grattez les balises SEO pour une liste d’URL
Balises méta CSV SEO Google Sheets
Hexomatic pour les équipes de recherche en finance ou investissement
Obtenez un avantage injuste en puisant dans les données publiques et en automatisant les tâches de recherche chronophages.
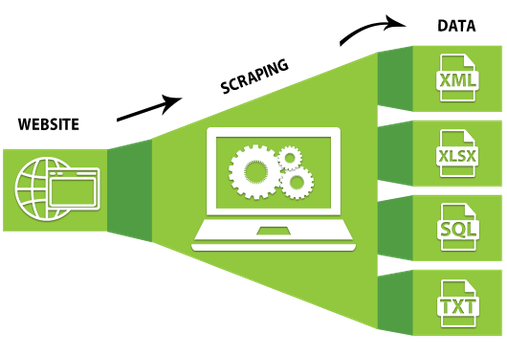
Le terme web scraping décrit la lecture automatique du contenu d’un site Web. Outre le scrape Web légal et souhaitable, tel que celui utilisé par les moteurs de recherche pour indexer les sites Web, il existe également des méthodes de scrap Web nuisibles et abusives. Par exemple, les attaquants utilisent cette technologie pour copier entièrement le contenu d’un site Web et le publier sur un autre site. Pour les entreprises, une telle approche a des conséquences néfastes sur l’activité.
Web scraping : une définition
Le scraping Web, également appelé screen scraping, décrit généralement le processus d’extraction, de copie, d’enregistrement et de réutilisation de contenu externe sur le Web. Outre le scraping manuel, dans lequel le contenu est copié à la main, certains outils de lecture automatisée de sites Web se sont également imposés. Une application positive du web scraping est l’indexation des sites web par Google ou d’autres moteurs de recherche. Dans la plupart des cas, cette indexation est intentionnelle, car c’est le seul moyen pour les utilisateurs de trouver les pages de l’entreprise qu’ils recherchent sur Internet. D’autre part, le screen scraping nuisible dans le but de voler illégalement la propriété intellectuelle viole le droit d’auteur et est donc illégal.
Comment fonctionne le web scraping ?
Différentes technologies et outils sont utilisés pour le web scraping :
Scraping manuel
En fait, les sections de contenu et de code source des sites Web sont parfois copiées à la main. Les cybercriminels recourent à cette méthode notamment lorsque les bots et autres programmes de scraping sont bloqués par le fichier robots.txt.
Outils et logiciels
Les outils de scraping Web tels que Scraper API, ScrapeSimple ou Octoparse permettent de créer des scrapers Web même avec peu ou pas de connaissances en programmation. Les développeurs utilisent également ces outils comme base pour développer leurs propres solutions de scraping.
Correspondance de modèle de texte
La comparaison et la lecture automatisées d’informations à partir de sites Web peuvent également être effectuées à l’aide de commandes dans des langages de programmation tels que Perl ou Python.
Manipulation HTTP
Le contenu peut être copié à partir de sites Web statiques ou dynamiques à l’aide de requêtes HTTP.
Exploration de données
Le scraping Web est également possible grâce à l’exploration de données. Pour ce faire, les développeurs Web s’appuient sur une analyse des modèles et des scripts dans lesquels le contenu d’un site Web est intégré. Ils identifient le contenu qu’ils recherchent et l’affichent sur leur propre site à l’aide d’un « wrapper ».
Analyseur HTML
Les analyseurs HTML connus des navigateurs sont utilisés dans le web scraping pour lire et convertir le contenu recherché.
Lecture des microformats
Les microformats font souvent partie des sites Web. Par exemple, ils contiennent des métadonnées ou des annotations sémantiques. La lecture de ces données permet de tirer des conclusions sur la localisation d’extraits de données spécifiques.
Utilisation et domaines d’application
Le web scraping est utilisé dans de nombreux domaines différents. Il est toujours utilisé pour l’extraction de données – souvent à des fins tout à fait légitimes, mais l’abus est également une pratique courante.
Robots d’exploration Web des moteurs de recherche
L’indexation des sites Web est à la base du fonctionnement des moteurs de recherche comme Google et Bing. Le tri et l’affichage des résultats de recherche ne sont possibles que grâce à l’utilisation de robots d’indexation Web, qui analysent et indexent les URL. Les robots d’indexation appartiennent aux soi-disant bots, c’est-à-dire des programmes qui effectuent automatiquement des tâches définies et répétitives.
Remplacement de services Web
Les grattoirs d’écran peuvent être utilisés en remplacement des services Web. Ceci est particulièrement intéressant pour les entreprises qui souhaitent mettre certaines données d’évaluation à la disposition de leurs clients sur un site Web. Cependant, utiliser un service Web pour cela entraîne des coûts élevés. Par conséquent, les grattoirs d’écran qui extraient les données sont l’option la moins chère.
Remixage
Avec le remix ou le mashup, le contenu de différents services Web est combiné. Le résultat est un nouveau service. Souvent, le remixage se fait via des interfaces, mais dans le cas où de telles API ne sont pas disponibles, la technique du screen scraping est également utilisée ici.
Les abus
L’utilisation abusive du web scraping ou du web harvesting peut avoir différents objectifs :
Accaparement des prix : L’accaparement des prix est une forme particulière de grattage Web : à l’aide de bots, un fournisseur lit les prix des produits des concurrents afin de les sous-coter et ainsi gagner des clients. En raison de la grande transparence des prix sur Internet, les clients migrent rapidement vers le fournisseur le moins cher suivant – la pression sur les prix augmente.
Saisie de contenu / produit : Au lieu de prix ou de structures de prix, les bots ciblent le contenu du site Web avec ce que l’on appelle la saisie de contenu. Les attaquants copient fidèlement à l’original les pages de produits conçues de manière élaborée dans les boutiques en ligne et utilisent le contenu créé de manière coûteuse pour leurs propres portails de commerce électronique. Les marchés en ligne, les bourses d’emploi ou les petites annonces sont également des cibles populaires pour l’accaparement de contenu.
Temps de chargement accrus : le scraping Web gaspille une précieuse capacité de serveur : les bots en grand nombre mettent constamment à jour les pages de produits à la recherche de nouvelles informations sur les prix. Cela allonge les temps de chargement pour les utilisateurs classiques, notamment en période de pointe. Si le contenu Web souhaité prend trop de temps à se charger, les clients migrent rapidement vers la concurrence.
Phishing : Les cybercriminels utilisent le web scraping pour voler les adresses e-mail publiées sur Internet et les utiliser pour le phishing. De plus, les criminels peuvent recréer une copie faussement réaliste de la page d’origine pour les activités de phishing.
Comment les entreprises peuvent-elles bloquer le web scraping ?
Certaines mesures empêchent le scraping d’un site Web :
Gestion des bots : avec les solutions de gestion des bots, les entreprises ont la possibilité de déterminer de manière finement granulaire quels bots sont autorisés à accéder aux informations du site Web et lesquels doivent être traités comme des logiciels malveillants.
robots.txt : à l’aide du fichier robots.txt, les opérateurs de site peuvent spécifier les zones du domaine qui peuvent être explorées et exclure certains bots dès le départ.
Requêtes Captcha : L’intégration des requêtes Captcha sur les sites Web offre également une protection contre les requêtes des bots.
Intégration correcte des numéros de téléphone et des adresses e-mail : les opérateurs de sites protègent les données de contact contre le grattage en mettant les informations derrière un formulaire de contact. De plus, une intégration des données via CSS est également possible.
Pare-feu : des règles de pare-feu strictes pour les serveurs Web protègent également contre les attaques de grattage indésirables.
Scraping comme spam
Les sites Web dont le contenu est récupéré sans citer la source enfreignent souvent le droit d’auteur. De plus, ils sont classés comme spam par les moteurs de recherche tels que Google. Pour les sites Web au contenu original, ces sites de spam présentent également un risque car les moteurs de recherche considèrent le site Web légitime comme un contenu dupliqué et le pénalisent en conséquence. La conséquence en est un classement SEO nettement plus mauvais. Afin de prendre des mesures actives contre le web scraping à un stade précoce, les entreprises et les webmasters utilisent, par exemple, des alertes Google spéciales, qui fournissent des informations sur les contenus suspects sur Internet.
Cadre légal : le screen scraping est-il légal ?
De nombreuses formes de grattage Web sont couvertes par la loi. Cela s’applique, par exemple, aux portails en ligne qui comparent les prix de différents fournisseurs. Un arrêt correspondant de la Cour fédérale de justice de 2014 le précise : tant qu’aucun dispositif technique de protection destiné à empêcher le grattage de l’écran n’est surmonté, il ne s’agit pas d’un handicap anticoncurrentiel.
Cependant, le grattage Web devient un problème lorsqu’il enfreint la loi sur le droit d’auteur. Quiconque intègre des textes protégés par le droit d’auteur dans son site Web sans en citer la source agit donc illégalement.
De plus, lorsque le grattage Web est utilisé à mauvais escient, par exemple pour le phishing, le grattage lui-même peut ne pas être illégal, mais les activités menées en conséquence sont illégales.
Définition du scraping : qu’est-ce que le scrape web ?
Définition du scraping : historiquement, lorsque les référenceurs SEO et les webmasters parlent de scraping, ils parlent de scraping d’écran ou de web scraping.
Le scraping est le processus d’extraction du contenu d’un site Web et de son incorporation dans un autre site Web, souvent avec une conception ou un objectif différent.
Il existe des utilisations positives du scrape, ainsi que des utilisations négatives, qui sont expliquées plus en détail ci-dessous.
Le scraping Web est connu sous de nombreux autres noms selon ce qu’une entreprise veut l’appeler, le scraping d’écran, l’extraction de données Web, le Web Harvesting et plus encore. Peu importe comment vous l’appelez, il s’agit d’une technique utilisée pour extraire de grandes quantités de données à partir de sites Web.
Les données sont extraites de divers sites Web et supports de stockage et stockées localement pour une utilisation ou une analyse immédiate, généralement effectuée ultérieurement.
Les données sont stockées le plus souvent dans un système de fichiers local ou dans des tables de base de données en fonction de la structure des données extraites.
La plupart des sites Web que nous visitons régulièrement nous permettent de visualiser uniquement le contenu et n’autorisent généralement pas la copie ou le téléchargement. Copier manuellement les données est aussi efficace que de couper des articles de journaux et peut prendre des jours ou des semaines.
Les techniques d’automatisation de ce processus afin qu’un script intelligent puisse vous aider à extraire les données des pages Web de votre choix et à les stocker dans un format structuré.
Qu’est-ce que le scraping ?
Il existe un certain nombre d’options techniques différentes disponibles pour scraper. Le scrape se fait automatiquement ou manuellement à l’aide d’outils dédiés. De plus, le scrape via la manipulation http et l’exploration de données est possible. La copie manuelle du contenu est également appelée scrape ou scraping.
Il existe diverses raisons de scraper. Par exemple, il existe une variété d’outils d’analyse qui extraient des données d’un site Web et les traitent ensuite à des fins spécifiques. Par exemple, un outil vérifie le placement d’un site Web pour un mot-clé spécifique sur Google et accède ainsi aux SERP.
Les flux RSS peuvent également être intégrés à d’autres sites Web et outils et représenter une forme de scrape. Par exemple, les informations sur les conditions météorologiques ou les horaires des transports en commun utilisent le scraping.
En général, l’extraction de données Web est utilisée par les personnes et les entreprises qui souhaitent utiliser la grande quantité de données Web accessibles au public pour prendre des décisions plus intelligentes.
Dans le monde du e-commerce, le web data scraping est largement utilisé pour la surveillance des prix des concurrents. C’est le seul moyen pratique pour les marques de vérifier les prix des produits et services de leurs concurrents, leur permettant d’affiner leurs propres stratégies de prix et de garder une longueur d’avance. Il est également utilisé comme outil par les fabricants pour s’assurer que les détaillants respectent les directives de prix pour leurs produits. Les organismes d’études de marché et les analystes dépendent de l’extraction de données Web pour évaluer le sentiment des consommateurs en suivant les critiques de produits en ligne, les articles de presse et les commentaires.
Il existe une vaste gamme d’applications d’extraction de données dans le monde financier. Les outils de scrapage 😊 de données sont utilisés pour extraire des informations des reportages, en utilisant ces informations pour guider les stratégies d’investissement. De même, les chercheurs et les analystes dépendent de l’extraction de données pour évaluer la santé financière des entreprises. Les compagnies d’assurance et de services financiers peuvent exploiter un riche gisement de données alternatives extraites du Web pour concevoir de nouveaux produits et polices pour leurs clients.
Les applications d’extraction de données Web ne s’arrêtent pas là. Les outils de récupération de données sont largement utilisés dans la surveillance des actualités et de la réputation, le journalisme, la surveillance SEO, l’analyse des concurrents, le marketing basé sur les données et la génération de leads, la gestion des risques, l’immobilier, la recherche universitaire, et bien plus encore.
Comment les données de tarification Web et l’intelligence des prix peuvent être utiles :
Tarification dynamique
Optimisation des revenus
Veille concurrentielle
Suivi des tendances produits
Conformité de la marque et du MAP
Les études de marché sont essentielles et doivent être guidées par les informations les plus précises disponibles. Des données Web de haute qualité, à volume élevé et très pertinentes, de toutes formes et tailles, alimentent l’analyse de marché et l’intelligence économique dans le monde entier.
Analyse des tendances du marché
Tarification du marché
Optimisation du point d’entrée
Recherche & Développement
Veille concurrentielle
Visite guidée de Scrap.io : comment scraper Google ?
Scrap.io est un outil pour capturer des leads B2B en masse en utilisant la data de Goole Maps de manière 100% légale.
La génération de leads est une activité marketing/vente cruciale pour toutes les entreprises. Dans le rapport Hubspot 2020 , 61 % des spécialistes du marketing entrant ont déclaré que générer du trafic et des prospects était leur défi numéro 1. Heureusement, l’extraction de données Web peut être utilisée pour accéder à des listes de prospects structurées à partir du Web.
Grattage web – Comment fonctionne un logiciel de scraping Web ?
Le logiciel de scraping Web charge automatiquement plusieurs pages Web les unes après les autres et extrait les données selon les besoins. Il est soit conçu spécifiquement pour un site Web spécifique, soit configuré en fonction d’un ensemble de paramètres pour fonctionner avec n’importe quel site Web. D’un simple clic sur un bouton, vous pouvez facilement enregistrer les données disponibles sur un site Web dans un fichier sur votre ordinateur.
Dans le monde d’aujourd’hui, des bots intelligents font du web scraping. Contrairement au screen scraping, qui ne fait que copier les pixels affichés à l’écran, ces bots extraient le code HTML sous-jacent ainsi que les données stockées dans une base de données en arrière-plan.
Un outil de scrap envoie généralement des requêtes HTTP à un site Web cible et extrait les données d’une page. Habituellement, il analyse le contenu accessible publiquement et visible par les utilisateurs et rendu par le serveur au format HTML. Parfois, il envoie également des demandes aux interfaces de programmation d’applications (API) internes pour certaines données associées, telles que les prix des produits ou les coordonnées, qui sont stockées dans une base de données et transmises à un navigateur via des requêtes HTTP.
Il existe différents types d’outils de grattage Web, avec des fonctionnalités qui peuvent être personnalisées pour s’adapter à différents projets d’extraction. Par exemple, vous pourriez avoir besoin d’un outil de grattage capable de reconnaître des structures de site HTML uniques, ou d’extraire, de reformater et de stocker des données à partir d’API.
Les outils de scraping peuvent être de grands frameworks conçus pour toutes sortes de tâches de scraping typiques, mais vous pouvez également utiliser des bibliothèques de programmation à usage général et les combiner pour créer un scraper.
Par exemple, vous pouvez utiliser une bibliothèque de requêtes HTTP – telle que la bibliothèque Python-Requests – et la combiner avec la bibliothèque Python BeautifulSoup pour récupérer les données de votre page. Ou vous pouvez utiliser un framework dédié qui combine un client HTTP avec une bibliothèque d’analyse HTML. Un exemple populaire est Scrapy, une bibliothèque open-source créée pour les besoins de scraping avancés.
Le scraping Web est populaire
Et cela ne devrait pas être surprenant, car le web scraping fournit quelque chose de vraiment précieux que rien d’autre ne peut : il vous donne des données Web structurées à partir de n’importe quel site Web public.
Plus qu’une commodité moderne, la véritable puissance du web scraping de données réside dans sa capacité à créer et à alimenter certaines des applications professionnelles les plus révolutionnaires au monde. « Transformatif » ne commence même pas à décrire la manière dont certaines entreprises utilisent les données récupérées sur le Web pour améliorer leurs opérations, en éclairant les décisions de la direction jusqu’aux expériences de service client individuelles.
Si vous le faites vous-même à l’aide d’outils de grattage de sites Web
Voici à quoi ressemble un processus général de grattage Web DIY :
Identifier le site Web cible
Collectez les URL des pages dont vous souhaitez extraire les données
Faire une requête à ces URLs pour obtenir le HTML de la page
Utilisez des localisateurs pour trouver les données dans le HTML
Enregistrez les données dans un fichier JSON ou CSV ou dans un autre format structuré
Assez simple, non? Si vous avez juste un petit projet. Mais malheureusement, vous devez relever de nombreux défis si vous avez besoin de données à grande échelle. Par exemple, maintenir le scraper si la mise en page du site Web change, gérer les proxies, exécuter du javascript ou contourner les antibots. Ce sont tous des problèmes profondément techniques qui peuvent consommer beaucoup de ressources. Il existe plusieurs outils de grattage de données Web open source que vous pouvez utiliser, mais ils ont tous leurs limites. C’est en partie la raison pour laquelle de nombreuses entreprises choisissent d’externaliser leurs projets de données Web.
Si vous l’externalisez :
Notre équipe recueille vos exigences concernant votre projet.
Notre équipe chevronnée d’experts en web scraping écrit le(s) scraper(s) et met en place l’infrastructure pour collecter vos données et les structurer en fonction de vos besoins.
Enfin, nous livrons les données dans le format et la fréquence souhaités.
En fin de compte, la flexibilité et l’évolutivité du web scraping garantissent que les paramètres de votre projet, aussi spécifiques soient-ils, peuvent être facilement satisfaits. Les détaillants de mode informent leurs créateurs des tendances à venir sur la base d’informations recueillies sur le Web, les investisseurs chronomètrent leurs positions boursières et les équipes marketing submergent la concurrence avec des informations approfondies, tout cela grâce à l’adoption croissante du Web Scraping en tant que partie intégrante des activités quotidiennes.
Que puis-je utiliser à la place d’un outil de grattage ?
Pour tous les projets, sauf les plus petits, vous aurez besoin d’une sorte d’outil de grattage Web automatisé ou d’un logiciel d’extraction de données pour obtenir des informations à partir de sites Web.
En théorie, vous pouvez couper et coller manuellement des informations de pages Web individuelles dans une feuille de calcul ou un autre document. Mais vous constaterez que cela est laborieux, long et sujet aux erreurs si vous essayez d’extraire des informations de centaines ou de milliers de pages.
Un outil de grattage Web automatise le processus, en extrayant efficacement les données Web dont vous avez besoin et en les formatant dans une sorte de structure bien organisée pour le stockage et le traitement ultérieur.
Une autre voie pourrait être d’acheter les données dont vous avez besoin auprès d’un fournisseur de services de données qui les extraira en votre nom. Cela serait utile pour les grands projets impliquant des dizaines de milliers de pages Web.
Dans les applications possibles décrites ci-dessus, le scraping doit être appréhendé positivement. Cependant, il existe également des exemples où le scraping est assimilé à du spam car il implique des méthodes de référencement illégales.
Par exemple, si une boutique en ligne présente un nouveau produit et copie le texte de description d’une autre boutique en ligne, il s’agit d’un scraping illégal. De plus, dans un tel cas, il y a du contenu en double, ce qui fait plus de mal que de bien au placement des SERP.
Étant donné que le contenu dupliqué peut également conduire à la dévaluation de la page avec le contenu original, les webmasters doivent veiller si le scraping a lieu par rapport à leur propre page.
Les SEO ont plusieurs options pour rendre le scrape plus difficile. Vous pouvez bloquer les robots correspondants via le fichier robot.txt, installer des requêtes de sécurité et optimiser le pare-feu du serveur.
4 conseils pour bien scraper
Bien qu’il s’agisse d’un excellent outil pour obtenir toutes sortes d’informations, vous devez vous occuper de certains problèmes juridiques afin de ne pas avoir d’ennuis.
Respectez le fichier robots.txt
Vérifiez toujours le fichier Robots.txt , quel que soit le site Web que vous souhaitez récupérer. Le document contient un ensemble de règles qui définissent la manière dont les bots doivent interagir avec le site Web. Cependant, si vous grattez d’une manière qui enfreint ces règles, vous pouvez vous trouver dans une zone grise légale.
Attention à ne pas stresser trop souvent les serveurs.
Ne devenez pas un scraper permanent. Certains serveurs Web sont victimes de temps d’arrêt lorsque la charge est très élevée. Les bots ajoutent plus de charge d’interaction au serveur d’un site Web, et lorsque la charge dépasse un certain point, le serveur peut devenir lent ou planter, détruisant l’expérience utilisateur d’un site Web.
Il est préférable de gratter les données pendant les périodes d’inactivité.
Pour éviter de vous enliser dans le trafic Web et les temps d’arrêt du serveur, vous pouvez scraper la nuit ou lorsque vous constatez que le trafic vers un site Web est plus faible.
Traitement responsable des données
Les directives doivent être suivies et la publication de données protégées par le droit d’auteur peut avoir de graves conséquences. Il est donc préférable que vous utilisiez les données collectées de manière responsable.

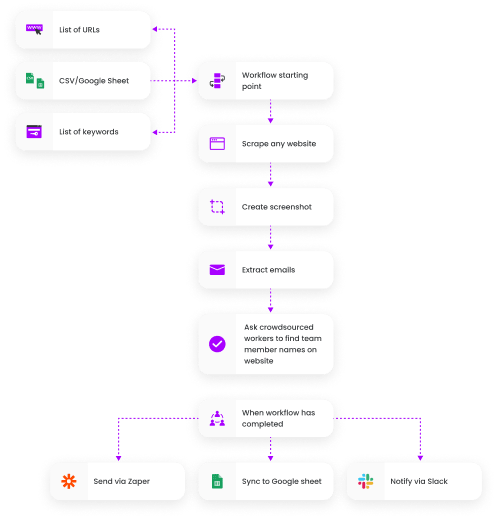 Démarrez des flux de travail à partir d’une liste de mots-clés, d’URL, d’un fichier CSV ou de toute règle de scrap de site Web.
Démarrez des flux de travail à partir d’une liste de mots-clés, d’URL, d’un fichier CSV ou de toute règle de scrap de site Web.