Sommaire
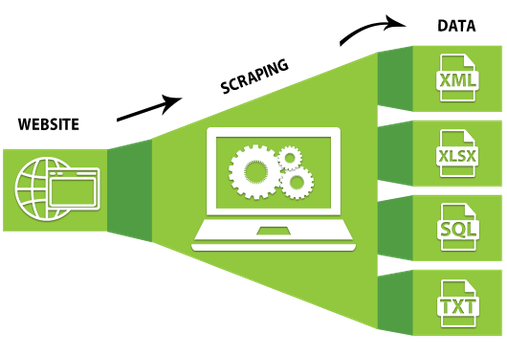
Qu’est-ce que le webscraping ?
Le terme web scraping décrit la lecture automatique du contenu d’un site Web. Outre le scrape Web légal et souhaitable, tel que celui utilisé par les moteurs de recherche pour indexer les sites Web, il existe également des méthodes de scrap Web nuisibles et abusives. Par exemple, les attaquants utilisent cette technologie pour copier entièrement le contenu d’un site Web et le publier sur un autre site. Pour les entreprises, une telle approche a des conséquences néfastes sur l’activité.
Web scraping : une définition
Le scraping Web, également appelé screen scraping, décrit généralement le processus d’extraction, de copie, d’enregistrement et de réutilisation de contenu externe sur le Web. Outre le scraping manuel, dans lequel le contenu est copié à la main, certains outils de lecture automatisée de sites Web se sont également imposés. Une application positive du web scraping est l’indexation des sites web par Google ou d’autres moteurs de recherche. Dans la plupart des cas, cette indexation est intentionnelle, car c’est le seul moyen pour les utilisateurs de trouver les pages de l’entreprise qu’ils recherchent sur Internet. D’autre part, le screen scraping nuisible dans le but de voler illégalement la propriété intellectuelle viole le droit d’auteur et est donc illégal.
Comment fonctionne le web scraping ?
Différentes technologies et outils sont utilisés pour le web scraping :
Scraping manuel
En fait, les sections de contenu et de code source des sites Web sont parfois copiées à la main. Les cybercriminels recourent à cette méthode notamment lorsque les bots et autres programmes de scraping sont bloqués par le fichier robots.txt.
Outils et logiciels
Les outils de scraping Web tels que Scraper API, ScrapeSimple ou Octoparse permettent de créer des scrapers Web même avec peu ou pas de connaissances en programmation. Les développeurs utilisent également ces outils comme base pour développer leurs propres solutions de scraping.
Correspondance de modèle de texte
La comparaison et la lecture automatisées d’informations à partir de sites Web peuvent également être effectuées à l’aide de commandes dans des langages de programmation tels que Perl ou Python.
Manipulation HTTP
Le contenu peut être copié à partir de sites Web statiques ou dynamiques à l’aide de requêtes HTTP.
Exploration de données
Le scraping Web est également possible grâce à l’exploration de données. Pour ce faire, les développeurs Web s’appuient sur une analyse des modèles et des scripts dans lesquels le contenu d’un site Web est intégré. Ils identifient le contenu qu’ils recherchent et l’affichent sur leur propre site à l’aide d’un « wrapper ».
Analyseur HTML
Les analyseurs HTML connus des navigateurs sont utilisés dans le web scraping pour lire et convertir le contenu recherché.
Lecture des microformats
Les microformats font souvent partie des sites Web. Par exemple, ils contiennent des métadonnées ou des annotations sémantiques. La lecture de ces données permet de tirer des conclusions sur la localisation d’extraits de données spécifiques.
Utilisation et domaines d’application
Le web scraping est utilisé dans de nombreux domaines différents. Il est toujours utilisé pour l’extraction de données – souvent à des fins tout à fait légitimes, mais l’abus est également une pratique courante.
Robots d’exploration Web des moteurs de recherche
L’indexation des sites Web est à la base du fonctionnement des moteurs de recherche comme Google et Bing. Le tri et l’affichage des résultats de recherche ne sont possibles que grâce à l’utilisation de robots d’indexation Web, qui analysent et indexent les URL. Les robots d’indexation appartiennent aux soi-disant bots, c’est-à-dire des programmes qui effectuent automatiquement des tâches définies et répétitives.
Remplacement de services Web
Les grattoirs d’écran peuvent être utilisés en remplacement des services Web. Ceci est particulièrement intéressant pour les entreprises qui souhaitent mettre certaines données d’évaluation à la disposition de leurs clients sur un site Web. Cependant, utiliser un service Web pour cela entraîne des coûts élevés. Par conséquent, les grattoirs d’écran qui extraient les données sont l’option la moins chère.
Remixage
Avec le remix ou le mashup, le contenu de différents services Web est combiné. Le résultat est un nouveau service. Souvent, le remixage se fait via des interfaces, mais dans le cas où de telles API ne sont pas disponibles, la technique du screen scraping est également utilisée ici.
Les abus
L’utilisation abusive du web scraping ou du web harvesting peut avoir différents objectifs :
- Accaparement des prix : L’accaparement des prix est une forme particulière de grattage Web : à l’aide de bots, un fournisseur lit les prix des produits des concurrents afin de les sous-coter et ainsi gagner des clients. En raison de la grande transparence des prix sur Internet, les clients migrent rapidement vers le fournisseur le moins cher suivant – la pression sur les prix augmente.
- Saisie de contenu / produit : Au lieu de prix ou de structures de prix, les bots ciblent le contenu du site Web avec ce que l’on appelle la saisie de contenu. Les attaquants copient fidèlement à l’original les pages de produits conçues de manière élaborée dans les boutiques en ligne et utilisent le contenu créé de manière coûteuse pour leurs propres portails de commerce électronique. Les marchés en ligne, les bourses d’emploi ou les petites annonces sont également des cibles populaires pour l’accaparement de contenu.
- Temps de chargement accrus : le scraping Web gaspille une précieuse capacité de serveur : les bots en grand nombre mettent constamment à jour les pages de produits à la recherche de nouvelles informations sur les prix. Cela allonge les temps de chargement pour les utilisateurs classiques, notamment en période de pointe. Si le contenu Web souhaité prend trop de temps à se charger, les clients migrent rapidement vers la concurrence.
- Phishing : Les cybercriminels utilisent le web scraping pour voler les adresses e-mail publiées sur Internet et les utiliser pour le phishing. De plus, les criminels peuvent recréer une copie faussement réaliste de la page d’origine pour les activités de phishing.
Comment les entreprises peuvent-elles bloquer le web scraping ?
Certaines mesures empêchent le scraping d’un site Web :
- Gestion des bots : avec les solutions de gestion des bots, les entreprises ont la possibilité de déterminer de manière finement granulaire quels bots sont autorisés à accéder aux informations du site Web et lesquels doivent être traités comme des logiciels malveillants.
- robots.txt : à l’aide du fichier robots.txt, les opérateurs de site peuvent spécifier les zones du domaine qui peuvent être explorées et exclure certains bots dès le départ.
- Requêtes Captcha : L’intégration des requêtes Captcha sur les sites Web offre également une protection contre les requêtes des bots.
- Intégration correcte des numéros de téléphone et des adresses e-mail : les opérateurs de sites protègent les données de contact contre le grattage en mettant les informations derrière un formulaire de contact. De plus, une intégration des données via CSS est également possible.
- Pare-feu : des règles de pare-feu strictes pour les serveurs Web protègent également contre les attaques de grattage indésirables.
Scraping comme spam
Les sites Web dont le contenu est récupéré sans citer la source enfreignent souvent le droit d’auteur. De plus, ils sont classés comme spam par les moteurs de recherche tels que Google. Pour les sites Web au contenu original, ces sites de spam présentent également un risque car les moteurs de recherche considèrent le site Web légitime comme un contenu dupliqué et le pénalisent en conséquence. La conséquence en est un classement SEO nettement plus mauvais. Afin de prendre des mesures actives contre le web scraping à un stade précoce, les entreprises et les webmasters utilisent, par exemple, des alertes Google spéciales, qui fournissent des informations sur les contenus suspects sur Internet.
Cadre légal : le screen scraping est-il légal ?
De nombreuses formes de grattage Web sont couvertes par la loi. Cela s’applique, par exemple, aux portails en ligne qui comparent les prix de différents fournisseurs. Un arrêt correspondant de la Cour fédérale de justice de 2014 le précise : tant qu’aucun dispositif technique de protection destiné à empêcher le grattage de l’écran n’est surmonté, il ne s’agit pas d’un handicap anticoncurrentiel.
Cependant, le grattage Web devient un problème lorsqu’il enfreint la loi sur le droit d’auteur. Quiconque intègre des textes protégés par le droit d’auteur dans son site Web sans en citer la source agit donc illégalement.
De plus, lorsque le grattage Web est utilisé à mauvais escient, par exemple pour le phishing, le grattage lui-même peut ne pas être illégal, mais les activités menées en conséquence sont illégales.