Sommaire
Cet article de ma série d'articles sur la sémantique et les entités dans le référencement et Google examine le rôle des entités dans l'interprétation des requêtes de recherche. Amusez-vous à lire!
Les tâches principales de la recherche par entité
Pour les systèmes d’extraction de recherche basés sur des entités, les entités jouent un rôle central dans plusieurs tâches.
- Interprétation des requêtes de recherche
- Détermination de la pertinence au niveau du document
- Évaluation au niveau du domaine ou de l'auteur
- Émission d'une réponse ad hoc sous la forme d'un panneau de connaissances, d'un extrait de code …
Dans toutes ces tâches, l’interaction entre entité, requête de recherche et pertinence s’applique. Cet article porte sur l'interprétation des requêtes de recherche et sur les relations entre les entités et les requêtes de recherche.
Google veut reconnaître le sens et l'intention de recherche des requêtes de recherche
L'interprétation des requêtes de recherche est l'un des plus grands défis des moteurs de recherche à une époque où les requêtes de recherche étaient de plus en plus complexes, notamment par le biais de la recherche vocale. Car l’utilité d’un moteur de recherche est cruciale pour comprendre ce que recherche l’utilisateur. Ce n'est pas une tâche facile, en particulier pour les requêtes de recherche mal formulées. Dans moderne systèmes de recherche d'information il s'agit de moins en moins de mots-clés, qui contiennent un terme de recherche autant que le sens de la requête. Ici, les entités jouent un rôle central dans de nombreuses requêtes de recherche.
Presque tous les termes de recherche sont basés sur une question implicite ou explicite et sur une intention de recherche. L'intention de recherche est très importante pour la comparaison avec l'objectif des documents ou du contenu du corpus respectif. En période de recherche vocale et d'appareils mobiles, il est encore plus important pour Google d'identifier les requêtes de recherche et leur intention ou signification d'utilisateur aussi précisément que possible, afin de générer individuellement les résultats de recherche correspondants.
Mais je ne veux pas entrer dans l'intention de recherche ici. Dans cet article, je voudrais me concentrer sur l'interprétation de la signification des requêtes de recherche utilisant des entités.Vous pouvez en lire plus dans l'article explication et identification de l'intention de recherche et de l'intention de l'utilisateur par mot-clé.
Dans une interview en 2009, Ori Allon, ancien directeur technique de la Google Search Quality Team, a déclaré dans une interview avec IDG:
Nous travaillons très fort sur la qualité de la requête. La requête n'est pas la somme de tous les termes. La requête a une signification derrière elle. Pour des requêtes simples comme "Britney Spears" et "Barack Obama", il est assez facile pour nous de classer les pages. Mais quand la question est: Quel médicament devrais-je prendre après ma chirurgie oculaire?, C'est beaucoup plus difficile. Nous devons comprendre le sens …
Un exemple de l'efficacité des systèmes de recherche basés sur les entités, par opposition aux systèmes basés sur les termes, montre cet exemple.
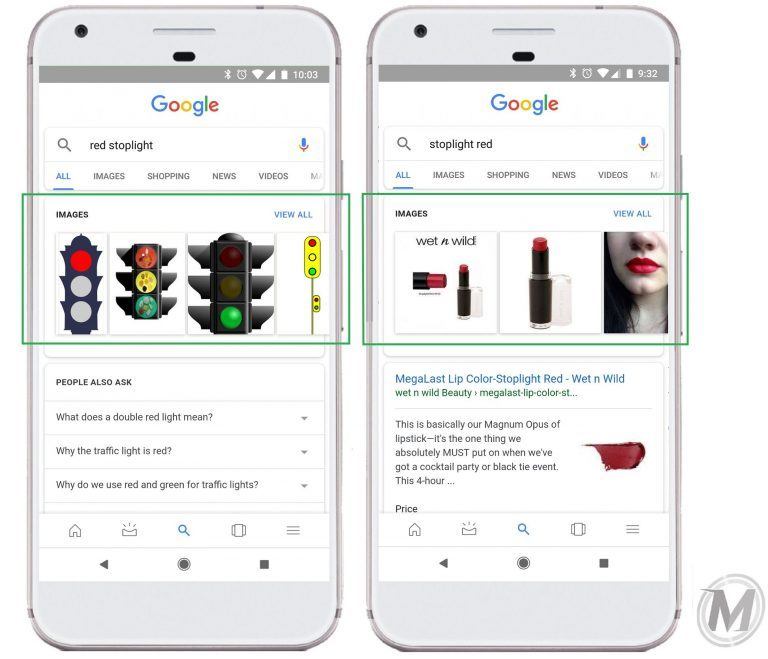
Source: https://mobilemoxie.com/blog/the-entity-language-series-translation-and-language-apis-impact-on-query-understanding-entity-ersterstanding-4-of-5/
Un moteur de recherche purement basé sur des termes ne reconnaîtrait pas la différence de sens entre les requêtes de recherche "feu rouge" et "feu rouge", car les termes de la requête de recherche sont les mêmes, mais disposés différemment. Selon la disposition, le sens est différent. Un moteur de recherche basé sur une entité reconnaît les différents contextes en fonction des différents arrangements. "Stoplight red" est une entité distincte, tandis que "red stoplight" est la combinaison d'un attribut et d'une entité "stoplight".
Dans cet exemple, il apparaît clairement qu'il ne suffit pas d'utiliser un terme pour déterminer l'entité. Les mots dans l'environnement jouent également un rôle important dans l'identification du sens. Les termes dont le sens varie en fonction du contexte représentent un défi pour Google ou les moteurs de recherche.
Google veut reconnaître les entités dans les requêtes de recherche
Google veut savoir quelle entité est une question. Ce n'est pas si facile si l'entité elle-même n'apparaît pas dans le terme de recherche. Google peut identifier l'entité que vous recherchez par les entités trouvées dans le terme de recherche et le contexte de relation entre les entités.
Un exemple:
La question "qui est le chef chez vw" ou la question implicite "chef vw" mène à la livraison de la boîte de graphe de connaissances suivante:
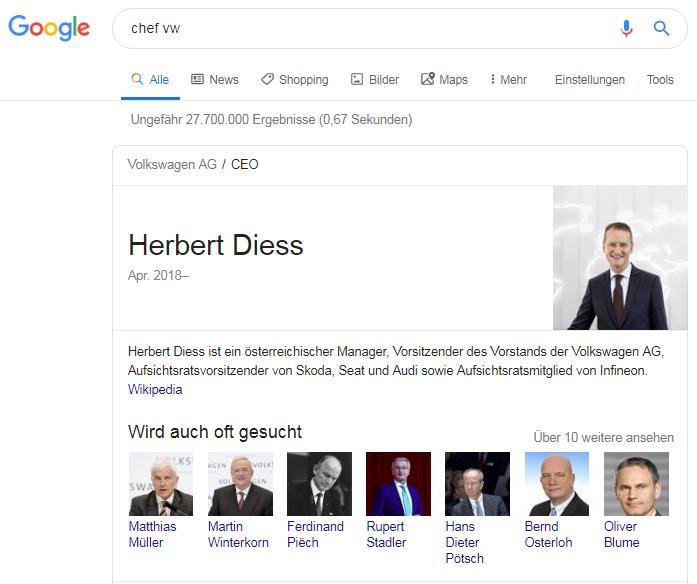
Dans cet exemple, deux entités et une phrase de connexion ou de prédicat jouent un rôle important dans la réponse à la question.
- VW (entité)
- Chef (type de connexion)
- Herbert Diess (entité)
Ce n'est qu'en combinant l'entité "VW" et le type de connexion "boss" que Google peut répondre à la question sur l'entité "Herbert Diess".
C'est pourquoi l'identification des entités par Google est si importante dans la première étape. Google utilise Knowledge Graph comme référentiel central pour tous les termes identifiés en tant qu'entités.
Pour Google, il est important d'identifier les entités dans les termes de recherche et d'identifier les connexions avec d'autres entités. Les relations entre les entités sont au moins aussi importantes. C'est la seule façon pour Google de répondre à des questions implicites sur les entités et donc à des questions concrètes sur des entités directement dans les SERP. Voici un exemple:
La requête de recherche "Qui est le fondateur d'Adidas?" (Question explicite) et "fondateur Adidas" (question implicite) conduit presque aux mêmes résultats de recherche:
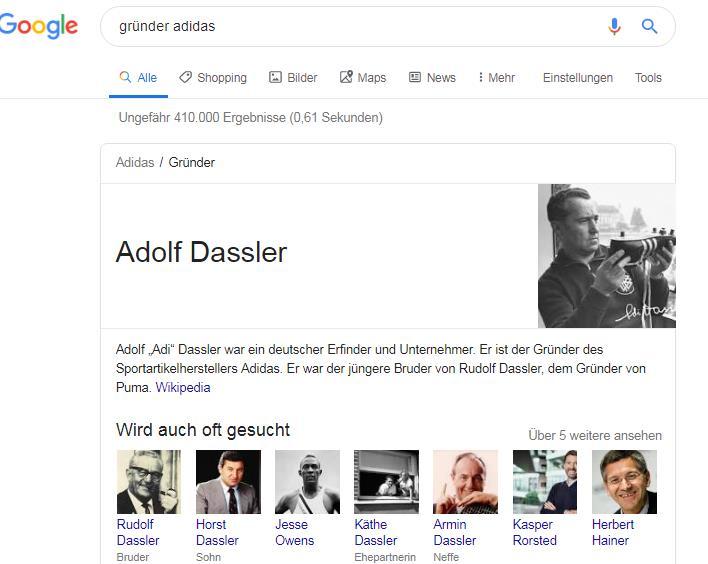
Même si les résultats diffèrent légèrement, Google reconnaît que l'entité recherchée est Adolf Dassler, bien que le nom n'apparaisse pas dans la requête de recherche. Peu importe si je pose une question implicite sous la forme du terme de recherche "Fondateur Adidas" ou une question explicite. L'entité "adidas" et le contexte relationnel "fondateur" suffisent à cela.
Enrichissement sémantique des requêtes de recherche
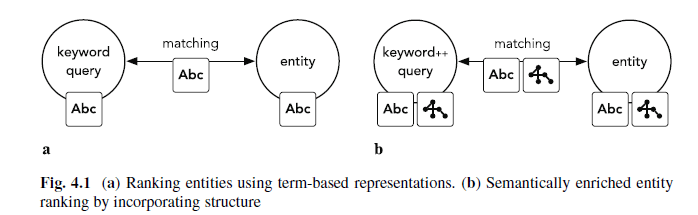
Source: Recherche par entité, Krisztian Balog
Il n’est pas toujours facile pour Google d’interpréter les entités pertinentes à partir des requêtes de recherche. Les requêtes de recherche en arrière-plan peuvent être automatiquement enrichies d'informations sémantiques supplémentaires ou d'annotations, ou suggérées à l'utilisateur via la méthode de suggestion automatique. Ce faisant, la correspondance entre la requête de recherche et l'entité ne repose plus uniquement sur le texte saisi, mais également sur les relations sémantiques des entités et des attributs.
L'exemple suivant recherche l'entité "Ann Dunham". Un moteur de recherche purement basé sur des termes aurait des problèmes pour répondre à la requête de recherche du "parent d'Obama". Grâce à la combinaison de recherche par terme et par entité, la réponse "Ann Dunham" peut être sortie en tant que mère du moteur de recherche.
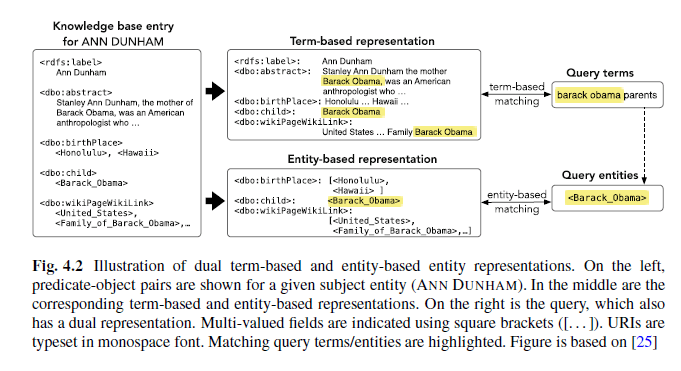
Source: Recherche par entité, Krisztian Balog
En pratique, le résultat ressemble à ceci. En plus de la mère Ann Dunham, la deuxième entité du père Barack Hussein Obama ayant fait l'objet d'une recherche, ainsi que le panel de connaissances de Barrack Obama, sont également publiés. Le panneau de la connaissance de Barrack Obama est joué parce que le système répond au terme Barack Obama dans la requête de recherche. Les deux autres zones d'entité sont sorties du graphe de connaissances en fonction des informations supplémentaires sémantiques.
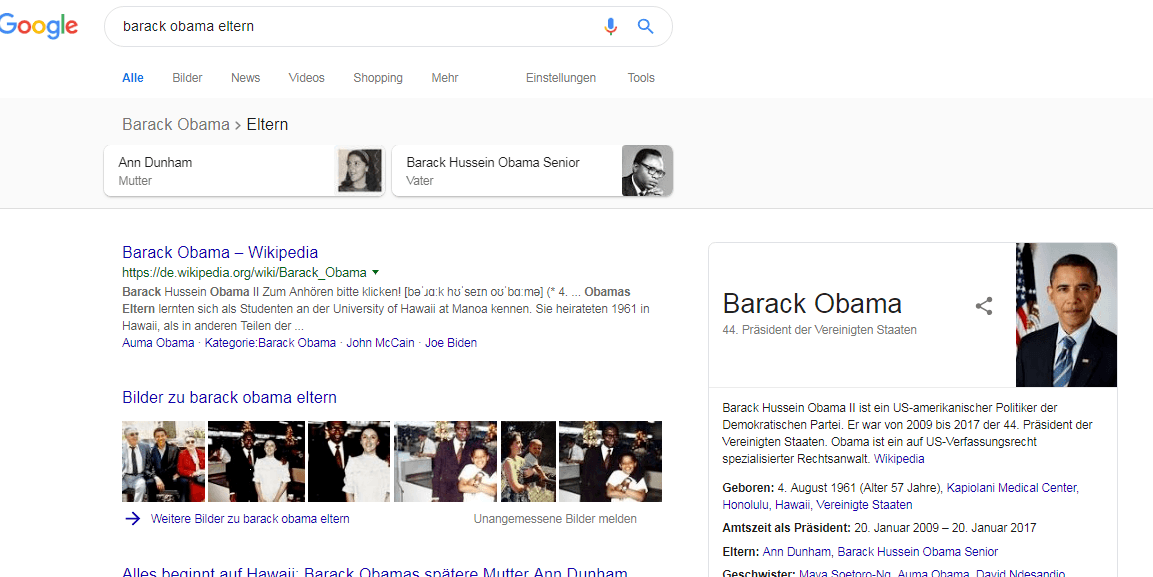
Cliquez sur l'image pour l'agrandir
La chose pratique à propos de ce système dual lors de l’interprétation des requêtes de recherche est que les résultats peuvent également être générés si aucune entité n’est recherchée dans un terme de recherche.
En plus de l'interprétation gênée par l'entité des requêtes de recherche, la méthode basée sur les termes peut également être prise en charge par des méthodes basées sur des types d'entités. Cela concerne les recherches qui recherchent plusieurs entités dans une classe de type, telles que "Visites de Hanovre". Voici une boîte qui répertorie plusieurs entités.
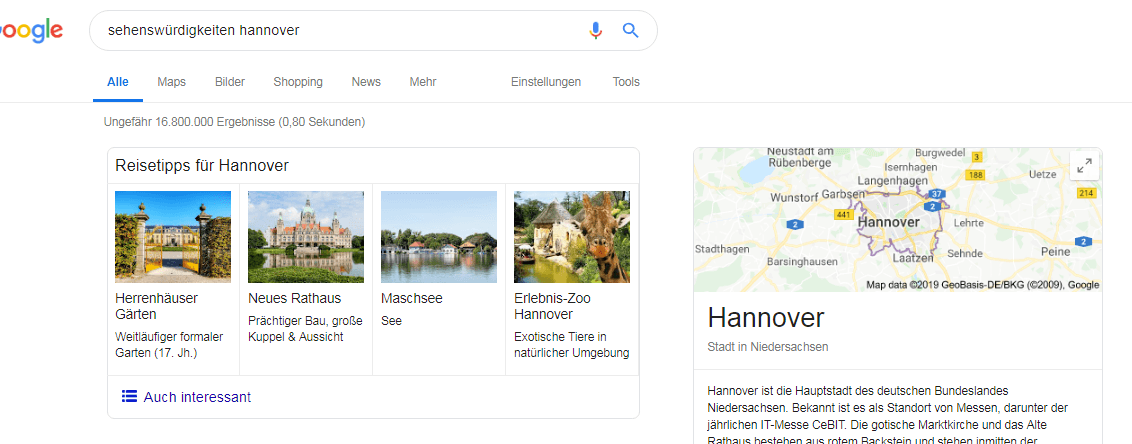
Cliquez sur l'image pour l'agrandir
Les requêtes relatives à un type d'entité génèrent souvent l'entité la plus pertinente, les carrousels ou le type de boîte de graphe de connaissances ci-dessus. Ces zones affichent les entités les plus pertinentes en fonction de la requête de recherche, en fonction de la pondération. La proximité ou la pertinence des entités par rapport à la requête de recherche peut être similaire à celle de documents concernant des analyses d'espace vectoriel, telles que p. Ex. Remarquez Word2Vec. Plus l'angle entre le vecteur de requête de recherche et le vecteur d'entité est petit, plus le terme et l'entité sont pertinents ou proches.
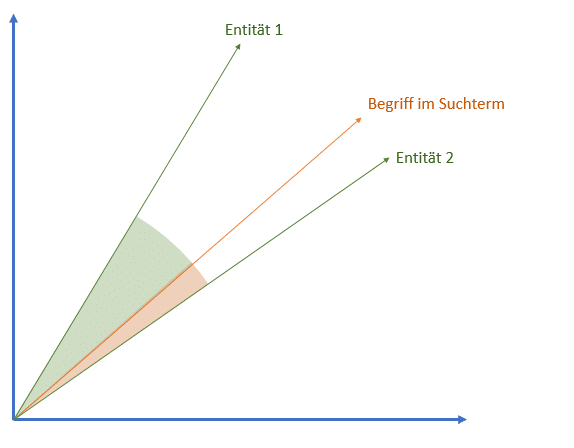
Exemple d'analyse d'espace vectoriel Entités pour la requête de recherche
Brevets Google pour l'interprétation des requêtes de recherche
Ci-dessous, je voudrais présenter quelques brevets Google pouvant être pertinents pour l'interprétation des requêtes de recherche. Certains des brevets ultérieurs pourraient être la technologie de base mise sur le Rankbrain avec ses technologies d’apprentissage automatique.
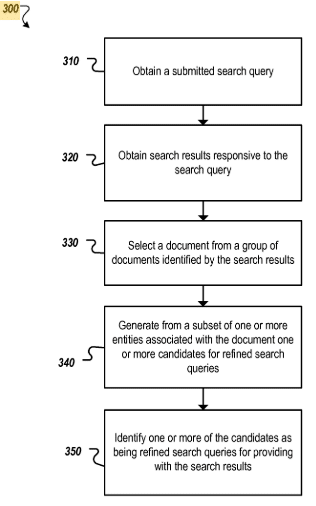
Je voudrais commencer par une série de brevets qui traitent du raffinement des requêtes de recherche. La date de publication du premier brevet montre que Google s’occupe de cette question complexe depuis longtemps. Il s’agit de l’un des premiers brevets de Google sur l’interprétation sémantique des termes de recherche. Ori Allon à partir de l'année 2009.
Affinage des requêtes de recherche
Le brevet traite principalement de l'interprétation des requêtes de recherche et de leur raffinement. Selon le brevet, le raffinement de la requête de recherche fait référence à certaines entités qui souvent coexistent dans les documents explorant la requête d'origine ou ses synonymes. En conséquence, les entités peuvent être référencées les unes aux autres et même des entités auparavant inconnues peuvent être rapidement identifiées.
Identification des expansions d'acronymes
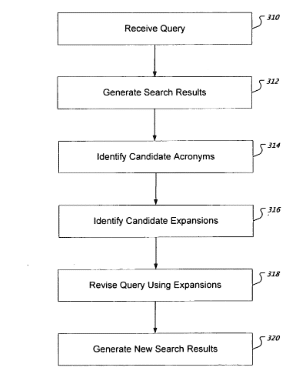
Ce brevet a été publié pour la première fois dans le Août 2011 dessiné par Google et im Octobre 2017 redessiné à nouveau sous un nouveau nom. C'est très excitant en tant que l'un des inventeurs du spécialiste de l'apprentissage en profondeur Thomas Strohmann qui a joué un rôle de premier plan dans le développement de Rankbrain.
Ce brevet ne parle pas d'entités, mais il décrit une autre façon pour Google de réécrire ou d'affiner les recherches originales en fonction des informations d'un premier sous-ensemble de documents afin d'obtenir des résultats de recherche plus pertinents. Dans ce brevet, il s'agit principalement d'interprétation des acronymes dans les requêtes de recherche. Toutefois, le processus décrit constitue un modèle pour de nombreuses autres méthodes traitant du raffinement ou de la réécriture des requêtes de recherche.
L'acronyme et le moteur de synonymes décrits dans le brevet peuvent être remplacés par le graphe de connaissances.
Réécriture de requêtes avec détection d'entités
Ce brevet a été publié pour la première fois dans le Septembre 2004 dessiné par Google et im Octobre 2017 redessiné à nouveau sous un nouveau nom. C'est particulièrement excitant, car les racines ont une longueur d'avance sur Rankbrain, Hummingbird et Knowledge Graph, et semblent être pertinentes aujourd'hui, ce qui suggère que la méthodologie fait partie intégrante de la recherche Google actuelle.
La méthodologie décrit comment réécrire les requêtes de recherche avec des références d'entité selon les besoins, ou au moins suggérer des suggestions pour obtenir des résultats de recherche plus pertinents.
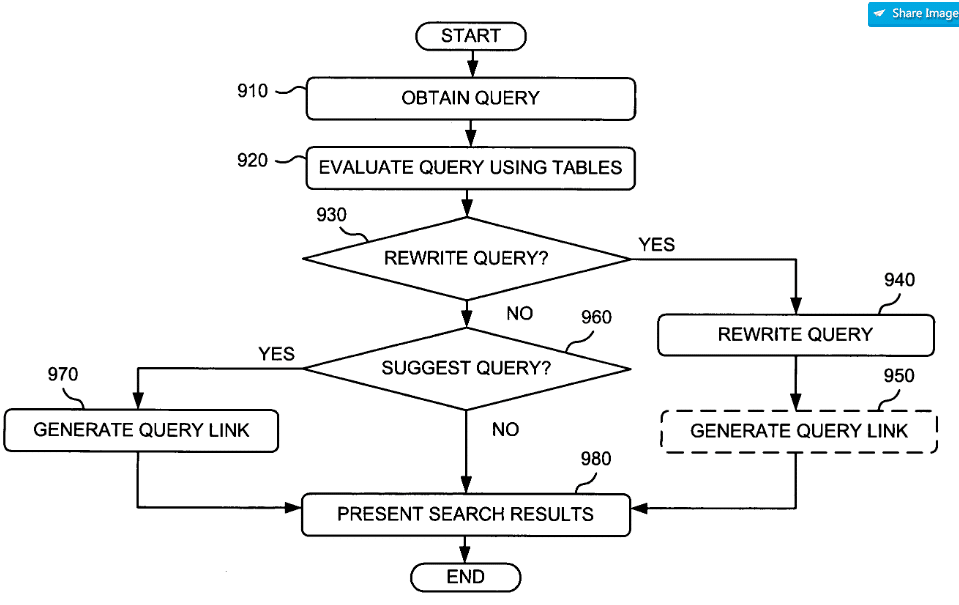
Le brevet semble à première vue assez simple et rudimentaire, car la réécriture de la requête dans les exemples cités fait uniquement référence à un complément aux requêtes de recherche avec des opérateurs de recherche. Par exemple, dans l'un des exemples, la requête "Business Week sur les fonds communs de placement" devient non écrite "Source des fonds communs de placement: Business Week". Je trouve intéressant dans le brevet que, dans les exemples, les identifiants d’entités soient attribués via des domaines. Cela donnerait la présomption que les domaines sont des images numériques uniques d'entités.
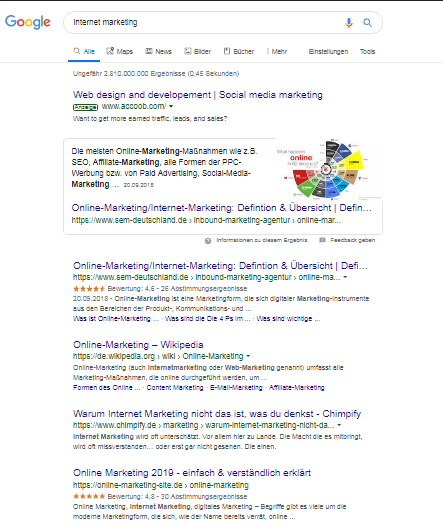
En outre, il est décrit qu’une réécriture de la requête de recherche comporte également différents termes synonymes, tels que. Des synonymes ou des fautes d'orthographe peuvent être exécutés et le contenu fourni en tant que résultats de recherche correspondant à la requête d'origine et à la requête réécrite.
Un exemple serait la requête de recherche "marketing internet". Nous trouvons ici les résultats correspondant à la requête de recherche initiale et au terme synonyme plus populaire de "marketing en ligne".
Découverte des actions d'entité pour un graphe d'entité
Ce brevet a Google dans Janvier 2014 d'abord dessiné et redessiné en octobre 2017 sous un nom actualisé. Il décrit comment Google identifie les activités liées aux entités en fonction des fluctuations de volume de recherche situationnelles à court terme. Ceux-ci peuvent alors être par exemple être ajouté à un panneau de connaissances à court terme ou un contenu qui prend en compte ces activités en cours peut être temporairement poussé vers le haut du classement. Cela permet à Google de réagir aux événements liés à la situation autour d'une entité et d'ajuster les SERP en conséquence.
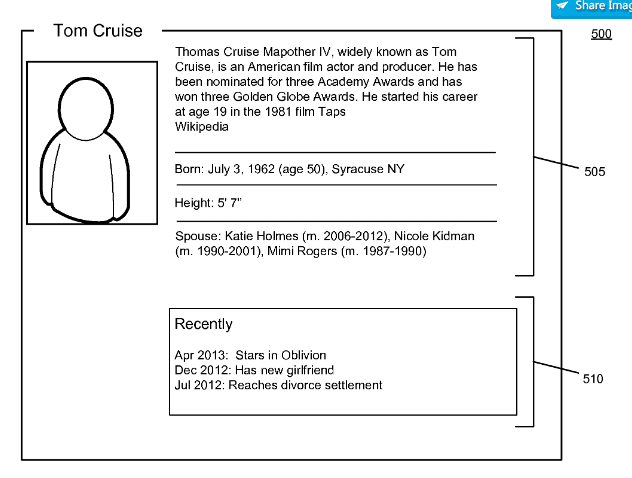
Sélection du contenu à l'aide des propriétés d'entité
Ce brevet a été redessiné pour la première fois en avril 2014 et en octobre 2017 sous un nouveau nom de Google. Il décrit comment Google peut utiliser un indice de confiance pour déterminer la hiérarchie des entités dans une requête de recherche.

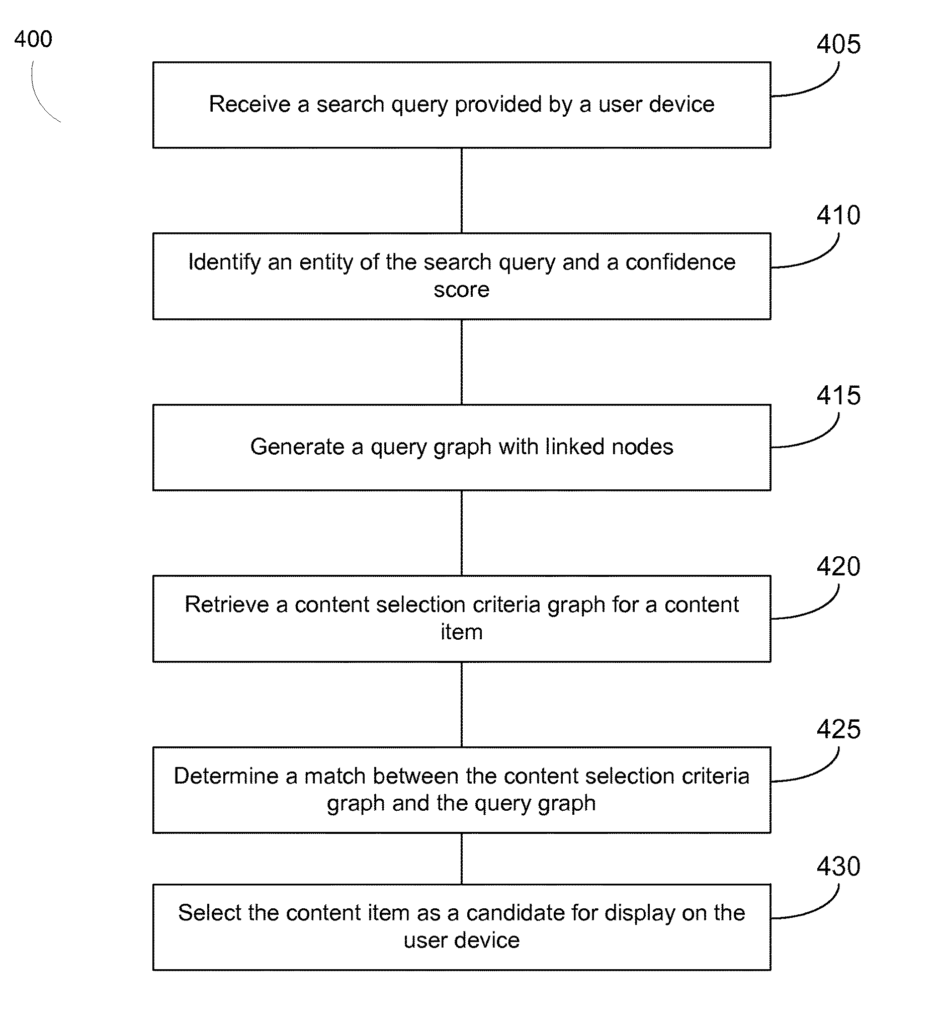
Pour détecter la pertinence d'une entité dans une requête, Google peut utiliser un score de confiance.
Le procédé peut inclure l’identification d’une propriété de la requête de recherche. Le procédé peut inclure le système de traitement de données déterminant une correspondance entre une propriété d'une entité de critères de sélection de contenu et la propriété de l'entité de la requête de recherche. Le procédé peut inclure le système de traitement de données. Source: https://patents.google.com/patent/US9542450B1/en
Après que ce score de confiance soit ensuite déterminé quelle est l'entité principale dans la requête de recherche, les documents appropriés pour les SERP sont donc déterminés. Les attributs d'entité peuvent être inclus dans le processus de sélection via un graphe de requête et un graphe de critères de sélection de contenu.
Dans la requête "rouge stoplight" dans la capture d'écran à gauche, les mots sont dans l'ordre standard – "rouge" décrit "stoplight" , Lorsque l'ordre est inversé, «feu rouge» devient la requête de la main droite, il devient comme s'il s'agissait d'un feu rouge; ici, 'stoplight' devient l'adjectif et 'rouge' devient le nom (un concept).
Identifier et classer les attributs d'entités
Ce brevet de Google, publié en 2015, est sans doute l’un des brevets les plus intéressants sur le sujet. Il décrit comment Google détermine les données de la requête de recherche, les parties descriptives de l'entité et les pièces jointes pour chaque terme de recherche. Ces pièces jointes peuvent par exemple Soyez des attributs. De cette manière, les requêtes de recherche peuvent être analysées pour déterminer les types d'informations que les utilisateurs souhaitent généralement recevoir.
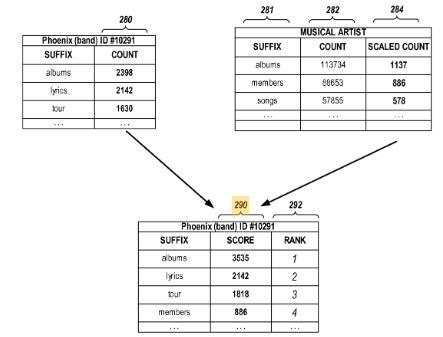
Dans de nombreux cas, les types d'informations qui intéressent un utilisateur pour une entité (telle qu'une personne ou un sujet) sont différents. En analysant les requêtes de recherche, les informations les plus demandées peuvent être identifiées pour une entité donnée. Ensuite, lorsqu'un utilisateur envoie une requête concernant l'entité particulière, les informations les plus demandées peuvent être fournies en réponse à la requête. Par exemple, un bref résumé des faits les plus fréquemment demandés pour l'entité particulière et d'autres entités similaires peut être fourni, tel que: dans un panneau de connaissances ou une carte de connaissances.
Il prend en compte la fréquence à laquelle certaines informations sont recherchées pour l'entité elle-même ainsi qu'en général pour le type d'entité. Si par exemple Basé sur le groupe Phoenix souvent après les albums, les paroles et les dates de tournée, et généralement pour les musiciens après les membres du groupe et les chansons, il en résulte les informations fournies dans le panneau de connaissances.
Méthodes, systèmes et supports d'interprétation de requêtes
Dans ce brevet, Google im Année 2015 diverses méthodes sont décrites comment les moteurs de recherche peuvent interpréter les requêtes de recherche.
Ce brevet décrit le problème de base et les solutions pour faire face aux défis.
Par exemple, en réponse à la requête "film d'action avec Tom Cruise", ces moteurs de recherche peuvent fournir des résultats de recherche non pertinents, tels que "Last Action Hero" et "Tom and Jerry", simplement parce qu'une partie de la requête de recherche est incluse dans la liste. titre des éléments de contenu. En conséquence, une compréhension de la requête de recherche peut produire des résultats de recherche plus significatifs.
Dans la méthode décrite ici, les requêtes de recherche sont décomposées en termes individuels. Pour ces termes, il est vérifié s'ils sont liés à une entité connue. Un score de confiance détermine la proximité des termes par rapport aux entités. Le contexte de la requête de recherche, y compris les termes sans référence directe à une entité, joue également un rôle dans le terme de recherche. Sur la base de l'entité la plus pertinente, une recherche est effectuée en fonction du type d'entité et les résultats de la recherche correspondants sont livrés.

Voici un exemple. Une requête de recherche telle que "Film d'action avec Tom Cruise" serait décomposée en composants "Action", "Film", "Tom" et "Cruise". Le terme action peut être une entité du type entité film, genre ou série. Parmi ces types d’entités, lequel est le plus demandé peut, déterminé par la fréquence ou la popularité d'un score d'entité.
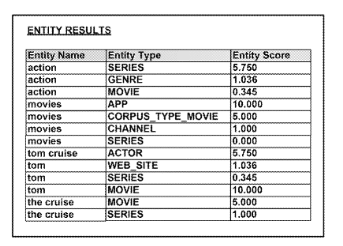
Selon le type de moteur de recherche (recherche d'images, recherche de vidéos …), les formats de média correspondants seront fournis en fonction du type d'entité recherché "Action Film" et de l'entité "Tom Cruise". Le brevet fait référence à une grande variété de recherches telles que, par exemple, Rechercher des requêtes dans une recherche d'image ou via une recherche vocale via un assistant numérique.
Génération de requêtes utilisant la similarité structurelle entre les documents
Ce brevet a été publié dans Septembre 2016 dessiné. Ce qui est excitant à propos de ce brevet, c’est que, parmi les inventeurs impliqués dans Paul Haahr et Yonhui Wu, se trouvaient deux ingénieurs majeurs de l’apprentissage en profondeur. En outre, Yonhui Wu a été l’un des leaders du développement de Rankbrain.
Le brevet décrit une méthode permettant à un moteur de recherche de générer des recherches auxiliaires sur une entité à stocker dans un magasin de requêtes. Ces requêtes de recherche pourraient ensuite être utilisées, par exemple. Requêtes ou réécritures d'un terme de recherche d'origine.
Sur la base de la structure de contenu de documents similaires, les affinements des requêtes de recherche peuvent être résumés. Ainsi, d'un document à l'auteur, la phrase survenue de Joseph Heller "Joseph Heller a écrit le roman influent catch 22 sur un militaire américain au cours de la Seconde Guerre mondiale." La requête "joseph plus brillante" est extraite.
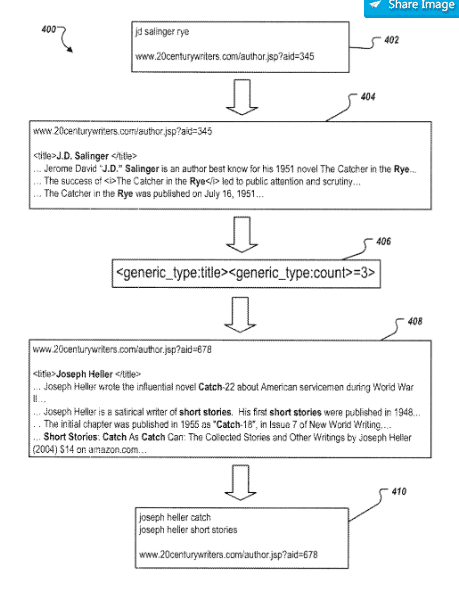
Regroupement d'affinements de requêtes par intention d'utilisateur présumée
Ce brevet a Google dans Mars 2016 d'abord dessiné et redessiné en octobre 2017 sous un nom actualisé. Il existe une méthodologie utilisée par Google pour affiner les requêtes de recherche afin de mieux déterminer ce que recherche réellement l'utilisateur. Ces améliorations sont les requêtes de recherche révisées qui apparaissent sous les résultats de la recherche.
Ces améliorations sont particulièrement importantes en cas de doute sur l’intention de l’utilisateur de lire des résultats plus pertinents et les recherches associées. Pour cela, toutes les recherches possibles sont organisées dans des raffinements de cluster reflétant les différents aspects de la requête d'origine. Ces aspects nécessitent des résultats de recherche différents.
Le regroupement des requêtes de recherche est résolu via une construction graphique. Les relations entre les termes de recherche, dépendantes de la session, ainsi que l'interrogation de documents spécifiques sont prises en compte. Le graphique prend en compte à la fois la similarité basée sur le contenu et la similarité de la cooccurrence de sessions déterminée à partir des journaux de requêtes. En d'autres termes, les dépôts simultanés de recherches consécutives ainsi que le comportement des clics sont analysés.
Dans le graphique, la requête d'origine ainsi que les raffinements et les documents correspondants sont représentés sous forme de nœuds. Des noeuds supplémentaires représentent les requêtes de recherche associées se produisant en session sous forme de co-occurrences intra-session. Tous ces noeuds sont connectés via des bords.
Des groupes d’affinements et de documents de recherche peuvent être créés via le vecteur de probabilité de visite.
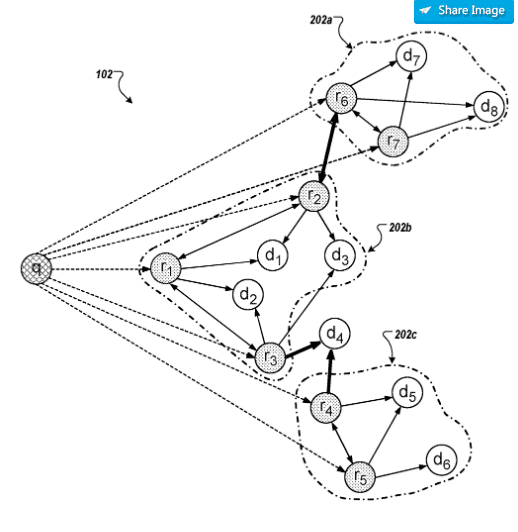
En ce qui concerne les recherches associées, le brevet contient un passage intéressant qui décrit comment les requêtes associées sont générées:
Les requêtes associées sont généralement obtenues à partir des journaux de requête en recherchant d'autres requêtes qui se produisent dans des sessions avec la requête d'origine. Plus précisément, les raffinements de requête, un type particulier de requêtes associées, sont obtenus en recherchant les requêtes les plus susceptibles de suivre la requête d'origine dans une session utilisateur. Pour de nombreuses requêtes courantes, il est possible que plusieurs requêtes associées soient extraites des journaux à l'aide de cette méthode. Toutefois, compte tenu de l'espace limité disponible sur une page de résultats de recherche, les moteurs de recherche ne choisissent généralement que d'afficher quelques requêtes connexes.
À cette fin, Google fournit le plus grand nombre possible de requêtes connexes, qui représentent les aspects les plus importants d’une requête de recherche originale diversifiée. Pour la recherche "mars", Google fournit les recherches connexes suivantes:

Les aspects ou entités suivants sont représentés par les requêtes associées:
- Gottfried Wilhelm Leipzig (philosophe)
- Université de Leibniz (établissement d'enseignement)
- Biscuit de Leibniz (nourriture)
Ces entités forment des grappes. Selon les résultats de la recherche, le groupe le plus populaire semble être le philosophe suivi de l'établissement d'enseignement:
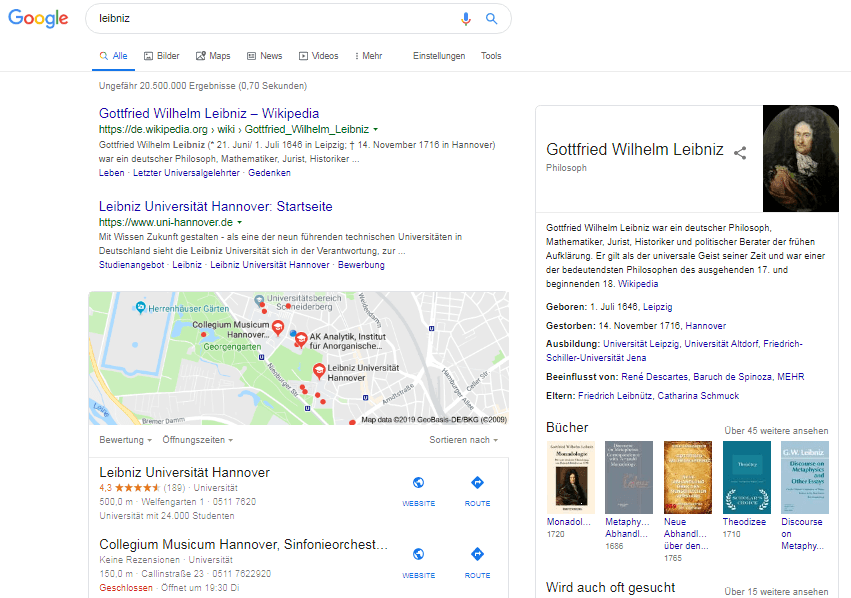
SERP pour la requête de recherche "leibniz" en contexte général
Ce sera intéressant si je change le contexte en affinant la requête de recherche pour "leibniz keks".
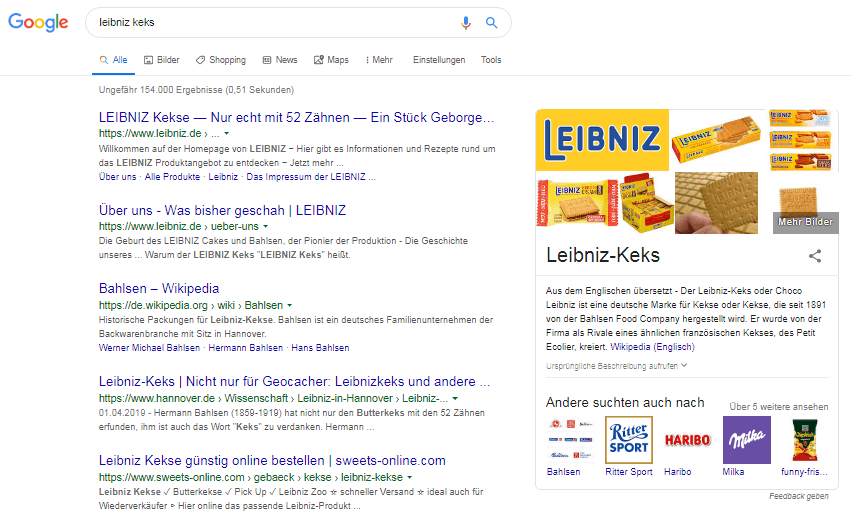
SERP pour la requête de recherche "leibniz keks"
Dès que vous mettez le focus interne de la session sur l'entité "Clés de Leibniz", les SERPs pour la requête de recherche ci-dessus "leibniz" changent comme suit:
- Vous ne verrez plus le panneau de connaissance pour le philosophe, mais pour les trois entités "Boîtes de spécifications" (pour en savoir plus ici)
- En position 1, le résultat est maintenant lié au cookie de Leibniz, tandis que dans la même requête précédente, l'entrée de Wikipédia est remontée jusqu'au philosophe.
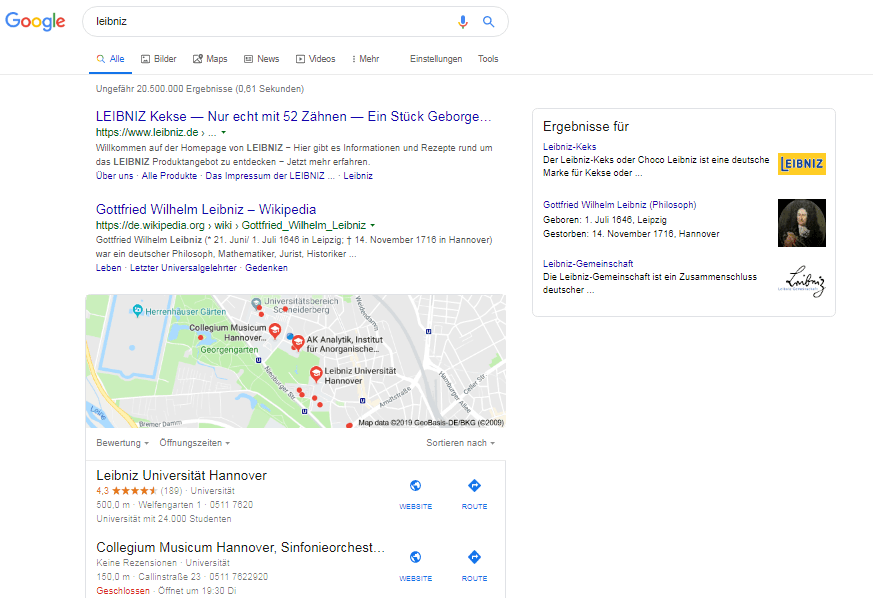
SERP pour "leibniz" en fonction du contexte individuel
Le focus de l'entité a changé par rapport à ma session de recherche individuelle. À partir de ce moment, la popularité du cluster ou de l'entité ne compte plus, mais bien mon intention de recherche personnelle et pertinente. (plus sur la pertinence et la pertinence dans la pertinence, la pertinence et l'utilité sur Google).
Passionnant, non?
Réécriture de requêtes sur l'appareil
Ce brevet a Google dans Avril 2016 d'abord dessiné et redessiné en octobre 2017 sous un nom actualisé. Il souhaite une méthode telle que des requêtes de recherche basées sur un modèle affiché sur le client, par exemple. un smartphone est récrit, annoté et attribué à une catégorie.
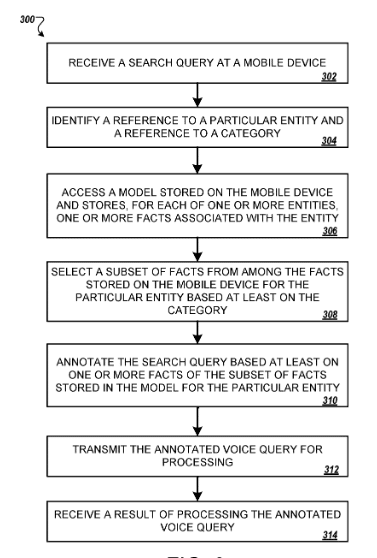
Le gros avantage de cette méthode est que les faits d’une base de données d’entités telle que Le graphique de connaissance peut en outre être enrichi avec des informations relatives à l'utilisateur individuel, telles que, par exemple, Les données de localisation peuvent être étendues. Cela peut être adapté à la situation individuelle de la réponse de l'utilisateur.
Associer à une entité avec une requête de recherche
Dans ce brevet, Google a été attribué en 2016. Il s'agit de savoir comment une entité peut être reconnue dans une requête de recherche ou comment Google peut voir qu'il s'agit en fait d'une requête de recherche avec une référence à une entité. Il existe également une autre version datant de 2013 pour ce brevet.
Le brevet décrit les étapes de processus suivantes:
-
- Recevoir une requête de recherche
- Identifier une entité associée au terme de recherche
- Fournissez un résumé de l'entité afin que les résultats correspondants puissent être affichés en réponse à la requête de recherche. Le résumé contient à la fois des informations pertinentes sur l'entité et des requêtes de recherche supplémentaires facultatives.
- Identifiez la demande de recherche d'entité facultative et établissez un lien avec l'option sélectionnée. (Plus dans le brevet ….)
- Identifier les documents correspondant aux entités ou à l'entité
- Identifier d'autres entités à partir des documents sélectionnés
- Connecter la ou les entités à la requête de recherche
- Déterminer un classement pour les entités

Apprendre des interactions utilisateur dans la recherche de personnel via le paramétrage d'attribut
À partir de 2017, la version scientifique "Tirer des leçons des interactions de l'utilisateur dans la recherche de personnel via le paramétrage d'attributs" est issue de. Voici comment Google pourrait créer des relations d'attributs sémantiques entre les requêtes de recherche et les documents cliqués, et même prendre en charge un algorithme de classement à auto-apprentissage, en analysant le comportement des utilisateurs avec des documents individuels:
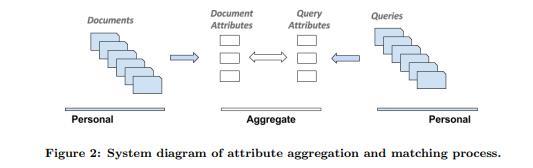
"Le cas dans la recherche privée est différent. Les utilisateurs ne partagent généralement pas les documents (par exemple, les courriels ou les fichiers personnels), et donc directement les agrégats. Pour résoudre ce problème, plutôt que d'apprendre directement du comportement de l'utilisateur pour une paire donnée (requête, doc) comme dans la recherche Web, nous avons plutôt choisi d'utiliser des documents et des requêtes utilisant des attributs sémantiquement cohérents qui sont en quelque sorte représentatifs de leur contenu.
Cette approche est également décrite à la figure 2. Les documents et les projets sont projetés dans un espace attributaire agrégé, plutôt que directement. Puisque nous supposons que les attributs sont dans un modèle d’apprentissage au classement. "
Amélioration de la mise en cluster de sujets sémantiques pour les requêtes de recherche avec la co-occurrence de mots et la mise en cluster de graphes bipartites
Un autre article scientifique de Google donne des informations intéressantes sur la manière dont Google divise aujourd'hui probablement les requêtes de recherche en différents domaines thématiques.
Ce document présente deux méthodes que Google utilise pour contextualiser les requêtes de recherche. Les scores de levage jouent un rôle central dans le regroupement de co-occurrences de Word:
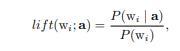
Formule de calcul du score de remontée
"Wi" dans la formule désigne tous les termes étroitement liés au mot racine, tels que les fautes d'orthographe, le pluriel, le singulier ou les synonymes.
"A" peut être toute interaction de l'utilisateur, telle que la recherche d'un terme de recherche spécifique ou la visite d'une page spécifique.
Si le score de levage, par exemple 5, la probabilité que "Wi" soit recherché est 5 fois supérieure à celle de "Wi" généralement recherchée.
"Un score élevé nous aide à construire des sujets significatifs plutôt que des mots inintéressants. En pratique, les probabilités peuvent être estimées à l'aide de la fréquence des mots dans l'historique de recherche Google dans une fenêtre temporelle récente. "
De cette façon, les termes peuvent être donnés à des entités particulières, telles que des entités. Mercedes et / ou lors de la recherche de pièces détachées de la classe de contexte thématique "voiture". La classe de contexte et / ou l'entité peuvent ensuite continuer à être associés à des termes qui apparaissent souvent en tant que co-occurrences des termes de recherche. Cela permet de créer rapidement un nuage de termes sur un sujet spécifique. La hauteur du score d'ascenseur détermine l'affinité avec le sujet:
"Nous utilisons le score de levage pour classer les mots en fonction de leur poids et de leur valeur."
Cette méthode peut être utilisée en particulier lorsque "Wi" est déjà connu, par ex. Termes de recherche par marques ou catégories connues. Si "Wi" ne peut pas être clairement défini, étant donné que les termes de recherche du même sujet sont trop différents, Google pourrait utiliser une deuxième méthode – "clustering bigraph pondéré".
Cette méthode repose sur deux hypothèses.
- Les utilisateurs partageant les mêmes intentions formulent leurs requêtes de recherche différemment. Néanmoins, les mêmes résultats de recherche sont générés par les moteurs de recherche.
- Inversement, des URL similaires sont générées pour une requête de recherche sur les premiers résultats de recherche.
Cette méthode compare les termes de recherche aux URL les mieux classées et crée des paires requête / URL dont la relation est pondérée en fonction des taux de clic et des impressions de l'utilisateur. De cette manière, des similitudes peuvent être faites entre les termes de recherche, qui n'ont pas le même mot racine et forment des clusters sémantiques.
Evaluation des interprétations sémantiques d'une requête de recherche

Ce brevet Google, introduit en juillet 2019, décrit une méthode permettant de déterminer différentes significations sémantiques dans une requête de recherche. Chaque interprétation sémantique est liée à une autre requête de recherche canonique. La requête en cours est modifiée en fonction de cela et du terme de recherche canonique
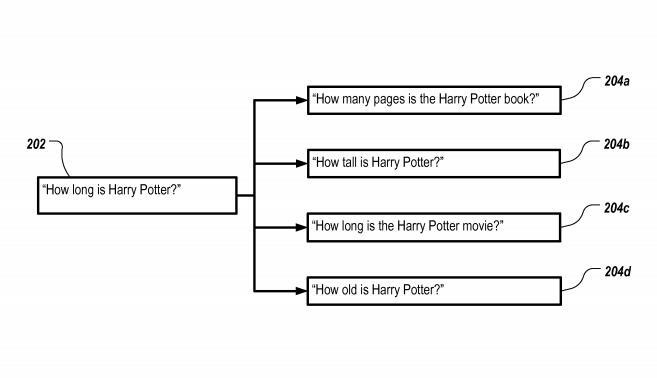
Semblable au brevet déjà mentionné concernant les annotations sémantiques, les termes de recherche modifiés sont déjà commentés avec un sens sémantique. En comparant les résultats de recherche de la requête de recherche initiale et ceux de la requête de recherche modifiée, les deux significations sémantiques possibles peuvent être validées et pondérées en relation. Le degré de similarité des résultats de la recherche détermine la proximité. Le degré de similarité est basé sur la fréquence d'apparition de certains mots-clés associés à la requête particulière dans les résultats de la recherche modifiés. Eine größere Häufigkeit des Auftretens von Keywords kann beispielsweise darauf hinweisen, dass die geänderte Suchanfrage mit größerer Wahrscheinlichkeit der semantischen Bedeutung entspricht.
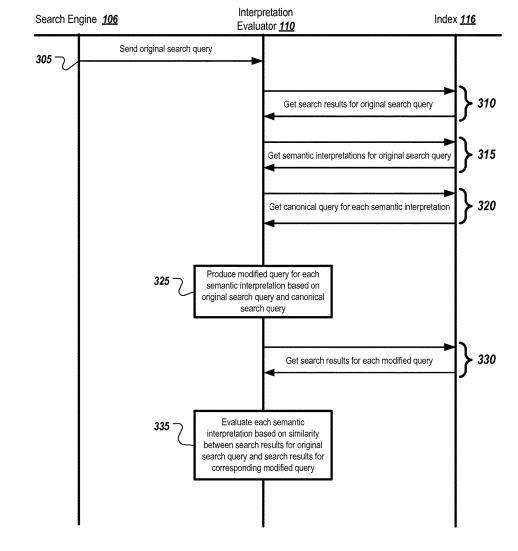
In einigen Fällen können andere Daten, wie z. B. die Klickrate des Benutzers, Website-Traffic-Daten oder andere Daten, verwendet werden, um eine wahrscheinliche semantische Interpretation zu interpretieren.
Query Suggestions based on entity collections of one or more past queries

Ein weiteres Google Patent aus dem Juli 2019 beschreibt eine Methode, wie Google Suggest Vorschläge aus vergangenen Suchanfragen generieren kann. Auch hier spielen Entitäten eine Rolle. Entitäten, die in Beziehung zu den in den bisherigen Suggest-Vorschlägen vorkommenden Entitäten oder in der Vergangenheit gesuchten Entitäten in Beziehung stehen sind die Basis für die Bestimmung einer Ähnlichkeits-Messzahl für die Bestimmung neuer Suggest-Vorschläge.
Weitere Google-Patente für die Entitäten-basierte Interpretation von Suchanfragen
Rankbrain ist ein Entitäten-basierter Search Query Processor
Als Google im Jahr 2015 die Einführung von Rankbrain für die bessere Interpretation von Suchanfragen bekannt gegeben hat gab es eine Vielzahl von Vermutungen und Meinungen aus der SEO-Branche. Es wurde z.B. von der Geburtsstunde von Machine Learning bzw. KI bei Google gesprochen. Wie in meinem Beitrag Bedeutung von Machine Learning, AI & Rankbrain für SEO & Google erläutert beschäftigt sich Google bereits seit 2011 im Rahmen des Projekts Google Brain intensiv mit Deep Learning. Rankbrain war allerdings die erste offizielle Bestätigung seitens Google, dass Machine Learning auch in der Google Suche eingesetzt wird.
Die wohl präzisesten Informationen von Google zu Rankbrain bisher gab es im Bloomberg Interview aus Oktober 2015.
Eine Aussage in dem Interview sorgte für viele Missverständnisse um Rankbrain.
RankBrain is one of the “hundreds” of signals that go into an algorithm that determines what results appear on a Google search page and where they are ranked. In the few months it has been deployed, RankBrain has become the third-most important signal contributing to the result of a search query.
Viele SEO-Medien haben die Aussage so interpretiert, dass Rankbrain einer der drei wichtigsten Rankingfaktoren ist. Aber ein Signal ist kein Faktor. Rankbrain hat einen großen Einfluss darauf wie die Suchergebnisse ausgewählt und geordnet werden ist aber kein Faktor wie z.B. bestimmte Bestandteile eines Inhalts oder Links.
In diesem Interview gibt es eine weitere interessante Aussage:
RankBrain uses artificial intelligence to embed vast amounts of written language into mathematical entities — called vectors — that the computer can understand. If RankBrain sees a word or phrase it isn’t familiar with, the machine can make a guess as to what words or phrases might have a similar meaning and filter the result accordingly, making it more effective at handling never-before-seen search queries.
Bei Rankbrain werden Entitäten in einer Suchanfrage identifiziert und mit den Fakten aus dem Knowledge Graph abgeglichen. Insofern die Begriffe mehrdeutig sind findet Google über Vektorraumanalysen heraus welche der möglichen Entitäten am besten zum Begriff passen. Dabei sind die umliegenden Wörter im Suchterm ein erstes Indiz für die Ermittlung des Kontext. Das mag auch auch ein Grund sein warum Rankbrain u.a. für Longtail-Suchanfragen zum Einsatz kommt.
Das Problem in der Pre-Rankbrain-Zeit war die fehlende Skalierbarkeit bei der Identifikation und Anlage von Entitäten im Knowledge Graph. Der Knowledge Graph basiert aktuell noch in erster Linie aus Informationen aus Wikidata, die durch Wikipedia-Entitäten verifiziert werden und Wikipedia selbst – also manuell gepflegte und dadurch eher statisches und damit nicht skalierbares System.
“Wikipedia is often used as a benchmark for entity mapping systems . As described in Subsection 3.5 this leads to sufficiently good results, and we argue it would be surprising if further effort in this area would lead to reasonable gains.”
Quelle: From Freebase to Wikidata – The Great Migration
Mehr dazu findest Du in den anderen Teilen der Beitragsreihe:
Eine weitere sehr zu empfehlende Quelle für Informationen zur Funktionsweise der Google-Suche aus erster Hand ist der bereits in einem anderen Beitrag erwähnte Vortrag von Paul Haahr auf der SMX West 2016.

Danny Sullivan fragte Jeff in der Q&A, wie RankBrain funktionieren könnte, um die Dokumentqualität oder -autorität festzustellen. Seine Antwort:
This is all a function of the training data that it gets. It sees not just web pages but it sees queries and other signals so it can judge based on stuff like that.
Das spannende an dieser Aussage ist, dass sie implizit ausdrückt, dass Rankbrain erst nach der Auswahl eines ersten Sets an Suchergebnissen eingreift.
Das ist eine wichtige Erkenntnis, da RankBrain die Suchanfrage nicht verfeinert, bevor Google nach Ergebnissen sucht, sondern erst danach.
Dann kann RankBrain die Abfrage möglicherweise verfeinern oder anders interpretieren, um die Ergebnisse für diese Abfrage auszuwählen und neu zu ordnen. Hier können wir den Bogen zu den bereits erwähnten Google-Patenten zur Verfeinerung der Suchanfragen ziehen, die höchstwahrscheinlich mit Rankbrain in Verbindung stehen.
En résumé: RankBrain ist ein Algorithmus basierend auf Deep Learning, der nach der Auswahl eines ersten Subsets an Suchergebnissen zum Einsatz kommt und sich auf Textvektoren und andere Signale stützt, um komplexe Suchanfragen über Natural Language Processing besser zu verstehen.
Das Zusammenspiel aus Rankbrain, Hummingbird und Knowledge Graph
Ich denke, es wird klar, dass Google sich immer mehr zur Ad-hoc-Antwort-Maschine entwickelt und deswegen die Bedeutung einer Suchanfrage immer wichtiger wird als die rein termbasierte Interpretation von Suchanfragen.
Bisherige Information Retrieval Methoden beschränken sich auf die in der Suchanfrage vorkommenden Begriffe und gleichen diese mit Inhalten ab in denen die einzelnen Begriffe vorkommen, ohne über eine Kontextuelle Verbindung der Begriffe zueinander zu berücksichtigen und darüber die eigentliche Bedeutung festzustellen.
Durch Innovationen wie Hummingbird und Rankbrain geht es im Kern darum gesuchte Entitäten über einen Abgleich mit einer Entitäten-Datenbank (Knowledge Graph) zu identifizieren, über die Beziehung der relevanten Entitäten zueinander einen Kontext und darüber die Bedeutung von Suchanfragen und Dokumenten zu erkennen.
Dieses Umdenken im Information Retrieval bei Google war der Grund für die Einführung des Knowledge Graph, das Hummingbird Update im Jahr 2013 und Rankbrain im Jahr 2015. Diese Reihe von Innovationen stehen im direkten Zusammenhang miteinander bzw. greifen prozessual ineinander.
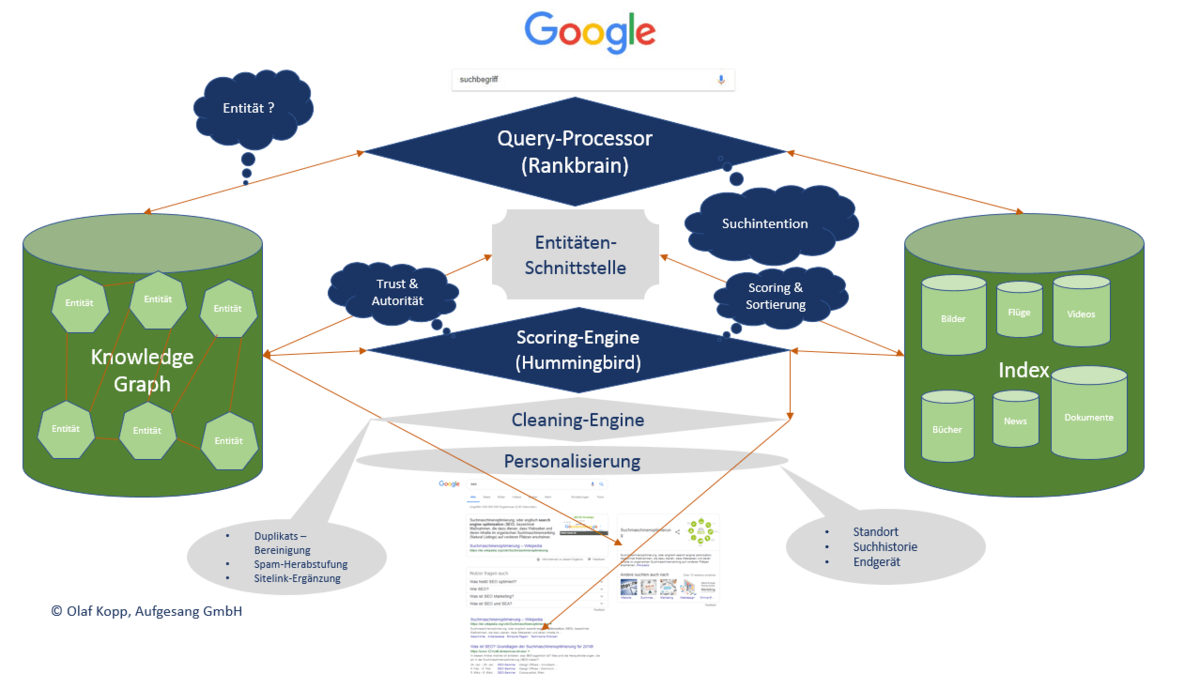
- Rankbrain ist für die Interpretation von Suchanfragen hinsichtlich Synonymität, Ambiguität, Sinn (Intention) und Bedeutung (Extension) zuständig. Gerade mit Blick auf neue Suchanfragen, Long Tail Keywords, mehrdeutige Begriffe sowie Abwicklung von Prozessen im Rahmen von Voice Search und digitalen Assistenten ist Rankbrain das zentrale Element im Query Processing.
- Die im Knowledge Graph erfassten Entitäten und Fakten wie Attribute und Beziehungen der Entitäten untereinander können sowohl bei der Relevanzbestimmung von Ergebnissen als auch bei der Verarbeitung von Suchanfragen (Query Processing) genutzt werden, um z.B. Dokumente und Suchanfragen über Kommentare (Annotations) mit Fakten aus dem Knowledge Graph anzureichern. Dadurch kann die Bedeutung von Suchanfragen als auch Dokumenten bzw. von einzelnen Absätzen und Sätzen in Inhalten besser interpretiert werden.
- Der Hummingbird-Algorithmus ist für das Clustering von Inhalten je nach Bedeutung sowie Zweck in unterschiedliche Korpusse und für die Bewertung bzw. das Scoring der Ergebnisse hinsichtlich Relevanz also das Ranking zuständig.
Das verbindende Element bei allen drei Modulen sind Entitäten. Sie sind kleinste gemeinsame Nenner. Sowohl bei Rankbrain also auch Hummingbird spielen Vektorraumanalysen bzw. Word Embeddings als auch Natural Language Processing eine zentrale Rolle. Durch die Fortschritte in Sachen Machine Learning kann Google diese Methoden immer performanter nutzen, um sich von einer rein textbasierten Suchmaschine zu einer semantischen Suchmaschine zu entwickeln.
Things not strings!



