
Sommaire
Les documents PDF offrent un avantage considérable par rapport aux autres types de documents: ils apparaissent exactement de la même manière sur chaque appareil.
Une fois le fichier PDF créé, chaque élément (en-tête, images, texte) sera toujours au même endroit. Le format du fichier PDF importe peu. Dans cet article, vous obtiendrez des conseils sur l’utilisation des fichiers PDF et sur la meilleure utilisation de ceux-ci pour votre stratégie de référencement.

Comment Google gère-t-il les PDF?
Pour les mots clés très compétitifs, les PDF apparaissent rarement dans les résultats de recherche TOP10. Techniquement, cependant, Google ne fait pas la différence entre une page HTML et un document PDF. Au lieu de cela, le moteur de recherche se concentre sur la présentation du meilleur résultat de recherche à l’utilisateur.
textes: Google peut indexer des PDF dans n’importe quelle langue ou codage de caractères, à condition que le document ne soit pas protégé par un mot de passe ni crypté. Les textes implémentés en tant qu’images sont partiellement traités à l’aide d’algorithmes OCR et “lus” en conséquence. Un texte simple permet de déterminer si un texte peut être lu dans un PDF sans trop d’effort de la part de Google: si le texte peut être copié par copier-coller à partir du PDF, Google réussit également à lire le texte et à le comprendre.
images: Les images provenant de fichiers PDF ne conviennent pas à la recherche d’images classique dans Google. Si vous souhaitez être trouvé avec les images du fichier PDF, il est recommandé de créer une page HTML classique.
liens: Les PDF, comme les documents HTML, peuvent également contenir des liens. Comme dans la version HTML, les liens dans les fichiers PDF peuvent hériter de Linkpower. Cela a été confirmé récemment par une déclaration de Gary Illyes:
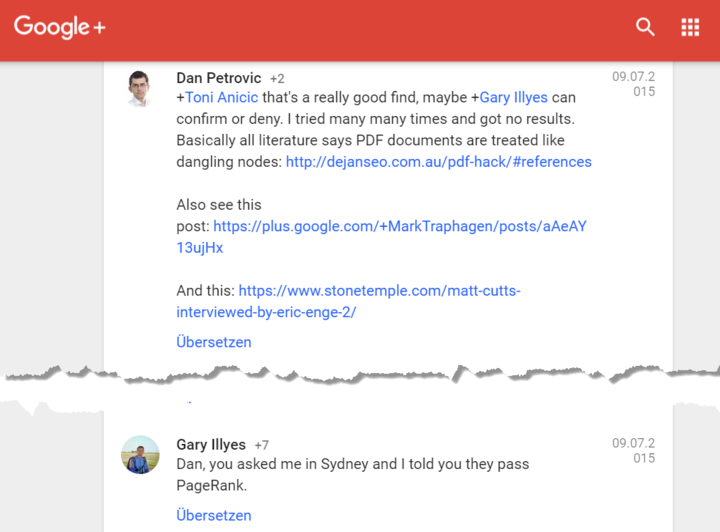
Figure 1: Les liens dans les PDF transmettent Linkpower
avertissement: Gardez à l’esprit lors de la manipulation de PDF que les vues PDF de solutions de suivi telles que Google Analytics ne sont pas enregistrées. Il est donc possible qu’un fichier PDF attire de nombreux visiteurs, mais ce trafic n’est pas utilisé en conséquence.
Afin d’identifier les potentiels et les points faibles, une analyse de fichier journal est recommandée pour examiner les appels provenant de fichiers non HTML. Incidemment, les analyses de fichier journal sont également très utiles pour examiner les activités du robot basées sur l’agent utilisateur.
Utiliser les PDF correctement
Du point de vue des moteurs de recherche, les PDF sont un sujet à deux tranchants. D’une part, les résultats de la recherche peuvent contenir des fichiers PDF, ainsi que d’autres types de documents. D’autre part, ils n’offrent à l’utilisateur aucune navigation ni aucun élément d’interaction avec la page.
C’est pourquoi il est important de réfléchir au rôle des PDF dans votre propre stratégie de référencement. La question la plus importante devrait être: “Un fichier PDF peut-il répondre aux attentes d’un visiteur du moteur de recherche?”
Option 1:
Exclure les PDF qui ne servent pas de page de destination à partir de l’index
Si l’on suppose qu’un fichier PDF indexable ne peut pas répondre aux besoins d’informations d’un utilisateur, vous devez vous assurer que le fichier PDF correspondant est exclu de l’index du moteur de recherche.
Le moyen le plus simple de garder les PDF hors de l’index consiste à utiliser un x-robot dans l’en-tête HTTP. Sur ce, on peut jouer un noindex ou un jour canonique. Bien que le noindex du moteur de recherche fournisse simplement l’information que le contenu n’appartient pas à l’index, on peut se référer à une version HTML du PDF à l’aide de la balise Canonical.
Cas d’utilisation: Quelle solution est la bonne pour moi?
En supposant que vous utilisiez un noindex dans l’en-tête HTTP pour ces PDF, vous gaspilleriez de l’énergie de liaison et seules les URL liées à partir du PDF en bénéficieraient. L’utilisation de la balise Canonical est particulièrement utile pour les PDF ayant généré de nombreux backlinks dans le passé. La balise Canonical transmet toute la puissance du lien à la page de destination appropriée à laquelle elle fait référence. Le PDF disparaîtrait de l’index et la page de destination correspondante apparaîtrait à la place dans les résultats de la recherche.
Figure 2: Exemple de page de destination au lieu d’un PDF
: Don’ts
- Verrouiller les PDF via Robots.txt – Les PDF seront toujours indexés et l’alimentation de liaison entrante sera perdue.
- Version PDF d’une page – certains CMS proposent par défaut une version PDF de toutes les pages HTML. L’utilisation d’une balise Canonical résoudrait le problème d’indexation, mais les moteurs de recherche devraient analyser les fichiers PDF encore et encore, gaspillant ainsi de précieuses ressources de robot.
Identifier les PDF indexables
Pour identifier rapidement les PDF indexables avec OnPage.org Zoom, quelques clics suffisent. Vous pouvez le faire simplement dans le rapport “Indexabilité” → “Qu’est-ce qui est indexable?” Activez le filtre “Indexable” (1) et cliquez sur le type “Mime” (2) “PDF”.
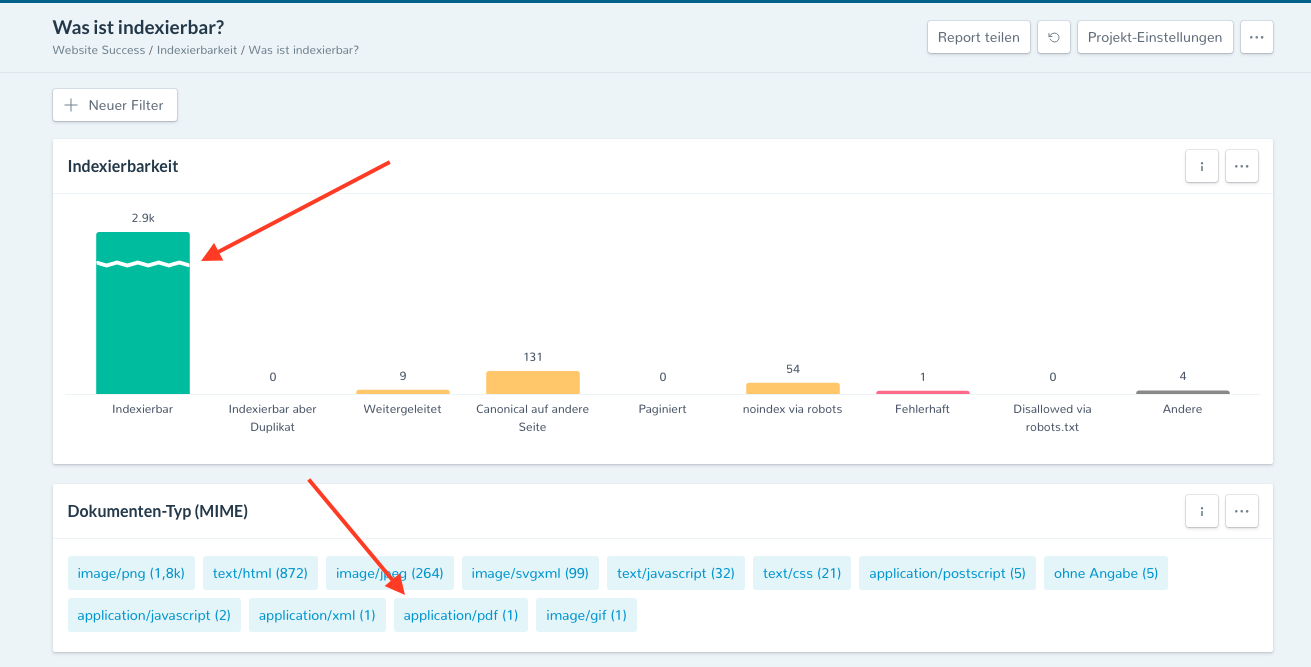
Figure 3: Afficher uniquement les PDF indexables
Si les filtres sont activés, tous les PDF trouvés lors de l’analyse seront répertoriés dans le tableau ci-dessous.
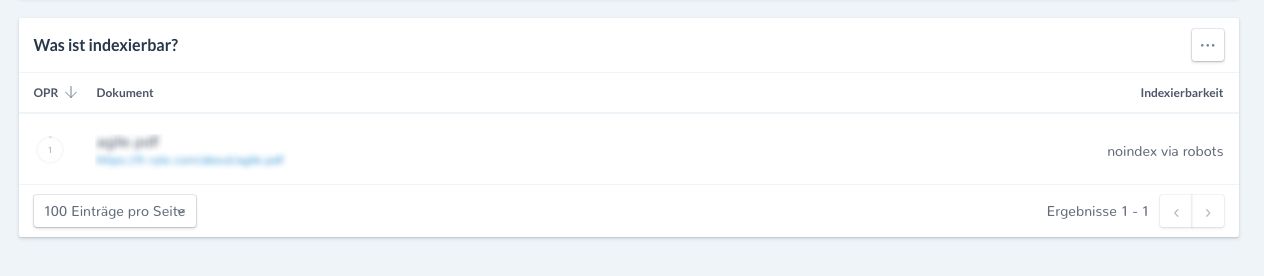
Figure 4: Liste de tous les PDF indexables
Une liste de tous les documents PDF déjà contenus dans Google Index peut être obtenue en combinant les opérateurs de recherche filetype: pdf et site: domain.tld:
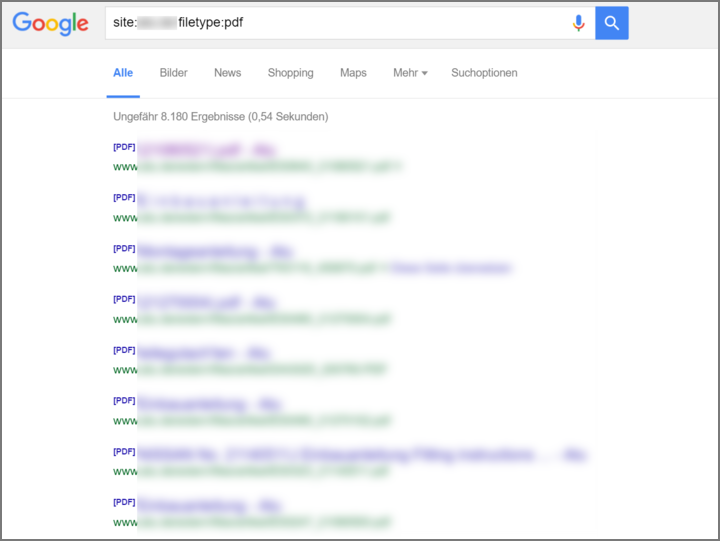
Figure 5: Liste de tous les PDF déjà dans l’index de Google
Option 2:
Garantir l’indexabilité des fichiers PDF pertinents pour l’index
Dans certains cas, il peut être très utile d’ajouter de la valeur aux utilisateurs qui souhaitent fournir des fichiers PDF à Google Index. Ceci est particulièrement utile lorsqu’il s’agit de fichiers PDF qui répondent à un besoin spécifique d’informations des utilisateurs, même si l’utilisateur n’a pas besoin d’interaction avec le site Web.
Un bon exemple est celui des réseaux de transport en commun, tels que le réseau S et U de Munich. L’objectif de l’utilisateur est d’obtenir des informations rapides, de télécharger le fichier PDF et de l’enregistrer sur l’appareil mobile sans interagir avec le site Web.
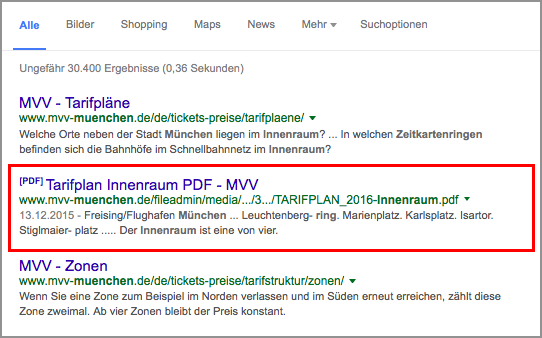
Figure 6: Exemple de PDF de page de destination appropriée dans l’index du moteur de recherche
Figure 7: Plan du réseau de Munich en PDF
Pour qu’un PDF apparaisse dans l’index des moteurs de recherche, l’exigence la plus importante est la Indexabilité du document.
Critères d’indexabilité
- Le code de statut HTTP est 200ok
- Les méta-robots ne peuvent pas être NoIndex
- Les balises canoniques, le cas échéant, ne peuvent faire référence à une autre URL
Si au moins un de ces critères ne s’applique pas, le document ne peut pas être indexé.
Les PDF non indexables peuvent être identifiés en quelques étapes à l’aide de OnPage.org Zoom. Pour cela, vous pouvez simplement sélectionner le type de document “PDF” dans le rapport “Indexabilité” → “Ce qui peut être indexé”. Ensuite, vous pouvez utiliser le graphique pour afficher une liste des PDF non indexables et leurs causes. (Par exemple, tous les PDF marqués avec la balise Meta Robots “noindex”.)
Astuce: Les fichiers PDF indexables doivent toujours inclure un lien vers la page de destination du site Web. Vous offrez donc à l’utilisateur la possibilité de naviguer rapidement sur le site.
conclusion
Les PDF peuvent être listés de la même manière que les pages HTML dans les résultats de la recherche. Mais tous les documents PDF ne conviennent pas comme pages de destination en même temps. Par conséquent, il convient de bien réfléchir au rôle des PDF dans leur propre stratégie de référencement et à la manière dont ils apportent un bénéfice maximal. Pour les fichiers PDF appropriés ne contenant pas de page de destination avec une grande puissance de liaison entrante, il est conseillé d’utiliser l’élément x-robots dans l’en-tête HTTP pour faire référence à une page de destination correspondante. Pour les fichiers PDF pertinents pour l’index, vous devez vous assurer qu’ils répondent à tous les critères d’indexation.



